- Technical Articles

Developing an Isolated Word Recognition System in MATLAB
By Daryl Ning, MathWorks
Speech-recognition technology is embedded in voice-activated routing systems at customer call centres, voice dialling on mobile phones, and many other everyday applications. A robust speech-recognition system combines accuracy of identification with the ability to filter out noise and adapt to other acoustic conditions, such as the speaker’s speech rate and accent. Designing a robust speech-recognition algorithm is a complex task requiring detailed knowledge of signal processing and statistical modeling.
This article demonstrates a workflow that uses built-in functionality in MATLAB ® and related products to develop the algorithm for an isolated digit recognition system. The system is speaker-dependent—that is, it recognizes speech only from one particular speaker’s voice.
Classifying Speech-Recognition Systems
Most speech-recognition systems are classified as isolated or continuous. Isolated word recognition requires a brief pause between each spoken word, whereas continuous speech recognition does not. Speech-recognition systems can be further classified as speaker-dependent or speaker-independent. A speaker-dependent system only recognizes speech from one particular speaker's voice, whereas a speaker-independent system can recognize speech from anybody.
The Development Workflow
There are two major stages within isolated word recognition: a training stage and a testing stage. Training involves “teaching” the system by building its dictionary, an acoustic model for each word that the system needs to recognize. In our example, the dictionary comprises the digits ‘zero’ to ‘nine’. In the testing stage we use acoustic models of these digits to recognize isolated words using a classification algorithm.
The development workflow consists of three steps:
- Speech acquisition
- Speech analysis
- User interface development
Acquiring Speech
For training, speech is acquired from a microphone and brought into the development environment for offline analysis. For testing, speech is continuously streamed into the environment for online processing.
During the training stage, it is necessary to record repeated utterances of each digit in the dictionary. For example, we repeat the word ‘one’ many times with a pause between each utterance.
Using the following MATLAB code with a standard PC sound card, we capture ten seconds of speech from a microphone input at 8000 samples per second:
We save the data to disk as ‘ mywavefile.wav ’:
This approach works well for training data. In the testing stage, however, we need to continuously acquire and buffer speech samples, and at the same time, process the incoming speech frame by frame, or in continuous groups of samples.
We use Data Acquisition Toolbox™ to set up continuous acquisition of the speech signal and simultaneously extract frames of data for processing.
The following MATLAB code uses a Windows sound card to capture data at a sampling rate of 8000 Hz. Data is acquired and processed in frames of 80 samples. The process continues until the “RUNNING” flag is set to zero.
Analyzing the Acquired Speech
We begin by developing a word-detection algorithm that separates each word from ambient noise. We then derive an acoustic model that gives a robust representation of each word at the training stage. Finally, we select an appropriate classification algorithm for the testing stage.
Developing a Speech-Detection Algorithm
The speech-detection algorithm is developed by processing the prerecorded speech frame by frame within a simple loop. For example, this MATLAB code continuously reads 160 sample frames from the data in ‘speech’.
To detect isolated digits, we use a combination of signal energy and zero-crossing counts for each speech frame. Signal energy works well for detecting voiced signals, while zero-crossing counts work well for detecting unvoiced signals. Calculating these metrics is simple using core MATLAB mathematical and logical operators. To avoid identifying ambient noise as speech, we assume that each isolated word will last at least 25 milliseconds.
Developing the Acoustic Model
A good acoustic model should be derived from speech characteristics that will enable the system to distinguish between the different words in the dictionary.
We know that different sounds are produced by varying the shape of the human vocal tract and that these different sounds can have different frequencies. To investigate these frequency characteristics we examine the power spectral density (PSD) estimates of various spoken digits. Since the human vocal tract can be modeled as an all-pole filter, we use the Yule-Walker parametric spectral estimation technique from Signal Processing Toolbox™ to calculate these PSDs.
After importing an utterance of a single digit into the variable ‘speech’, we use the following MATLAB code to visualize the PSD estimate:
Since the Yule-Walker algorithm fits an autoregressive linear prediction filter model to the signal, we must specify an order of this filter. We select an arbitrary value of 12, which is typical in speech applications.
Figures 1a and 1b plot the PSD estimate of three different utterances of the words ‘one’ and ‘two’. We can see that the peaks in the PSD remain consistent for a particular digit but differ between digits. This means that we can derive the acoustic models in our system from spectral features.

From the linear predictive filter coefficients, we can obtain several feature vectors using Signal Processing Toolbox functions, including reflection coefficients, log area ratio parameters, and line spectral frequencies.
One set of spectral features commonly used in speech applications because of its robustness is Mel Frequency Cepstral Coefficients (MFCCs). MFCCs give a measure of the energy within overlapping frequency bins of a spectrum with a warped (Mel) frequency scale 1 .
Since speech can be considered to be short-term stationary, MFCC feature vectors are calculated for each frame of detected speech. Using many utterances of a digit and combining all the feature vectors, we can estimate a multidimensional probability density function (PDF) of the vectors for a specific digit. Repeating this process for each digit, we obtain the acoustic model for each digit.
During the testing stage, we extract the MFCC vectors from the test speech and use a probabilistic measure to determine the source digit with maximum likelihood. The challenge then becomes to select an appropriate PDF to represent the MFCC feature vector distributions.
Figure 2a shows the distribution of the first dimension of MFCC feature vectors extracted from the training data for the digit ‘one’.

We could use dfittool in company/newsletters/articles/developing-an-isolated-word-recognition-system-in-matlab.html™ to fit a PDF, but the distribution looks quite arbitrary, and standard distributions do not provide a good fit. One solution is to fit a Gaussian mixture model (GMM), a sum of weighted Gaussians (Figure 2b).

The complete Gaussian mixture density is parameterized by the mixture weights, mean vectors, and covariance matrices from all component densities. For isolated digit recognition, each digit is represented by the parameters of its GMM.
To estimate the parameters of a GMM for a set of MFCC feature vectors extracted from training speech, we use an iterative expectation-maximization (EM) algorithm to obtain a maximum likelihood (ML) estimate. Given some MFCC training data in the variable MFCCtraindata , we use the Statistics and Machine Learning Toolbox gmdistribution function to estimate the GMM parameters. This function is all that is required to perform the iterative EM calculations.
Selecting a Classification Algorithm
After estimating a GMM for each digit, we have a dictionary for use at the testing stage. Given some test speech, we again extract the MFCC feature vectors from each frame of the detected word. The objective is to find the digit model with the maximum a posteriori probability for the set of test feature vectors, which reduces to maximizing a log-likelihood value. Given a digit model gmmmodel and some test feature vectors testdata , the log-likelihood value is easily computed using the posterior function in Statistics and Machine Learning Toolbox:
We repeat this calculation using each digit’s model. The test speech is classified as the digit with the GMM that produces the maximum log-likelihood value.
Building the User Interface
After developing the isolated digit recognition system in an offline environment with prerecorded speech, we migrate the system to operate on streaming speech from a microphone input.We use MATLAB GUIDE tools to create an interface that displays the time domain plot of each detected word as well as the classified digit (Figure 3).

Extending the Application
The algorithm described in this article can be extended to recognize isolated words instead of digits, or to recognize words from several speakers by developing a speaker-independent system.
If the goal is to implement the speech recognition algorithm in hardware, we could use MATLAB and related products to simulate fixed-point effects, automatically generate embedded C code, and verify the generated code.
Published 2010 - 91805v00
Products Used
- Data Acquisition Toolbox
- Signal Processing Toolbox
- Statistics and Machine Learning Toolbox
- Article: Developing Speech-Processing Algorithms for a Cochlear Implant
View Articles for Related Industries
- Communication Devices
Select a Web Site
Choose a web site to get translated content where available and see local events and offers. Based on your location, we recommend that you select: .
You can also select a web site from the following list
How to Get Best Site Performance
Select the China site (in Chinese or English) for best site performance. Other MathWorks country sites are not optimized for visits from your location.
- América Latina (Español)
- Canada (English)
- United States (English)
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- United Kingdom (English)
Asia Pacific
- Australia (English)
- India (English)
- New Zealand (English)
Contact your local office
- Contact sales
- Corpus ID: 18333316
ISOLATED WORD SPEECH RECOGNITION SYSTEM USING DYNAMIC TIME WARPING
- R. Makhijani , R. Gupta , M. Scholar
- Published 2013
- Computer Science
Figures from this paper

7 Citations
Speaker independent speech recognition using maximum likelihood approach for isolated words, analysis of feature extraction methods for speaker dependent speech recognition, analysis of voice recognition algorithms using matlab, single voice command recognition by finite element analysis, hardware design of dynamic time warping algorithm based on fpga in verilog, automatic home appliance switching using speech recognition software and embedded system, speech-based vehicle movement control solution, 14 references, real time isolated word speech recognition system for human computer interaction, speech recognition with dynamic time warping using matlab, dynamic time warping.
- Highly Influential
Isolated malay speech recognition using Hidden Markov Models
Robust speech recognition using fusion techniques and adaptive filtering, speech recognition using dynamic time warping, speech recognition by machine: a review, statistical modeling in continuous speech recognition (csr), the use of a one-stage dynamic programming algorithm for connected word recognition, related papers.
Showing 1 through 3 of 0 Related Papers
An automatic speech recognition system for isolated Amazigh word using 1D & 2D CNN-LSTM architecture
- Published: 11 October 2023
- Volume 26 , pages 775–787, ( 2023 )
Cite this article

- Mohamed Daouad ORCID: orcid.org/0009-0007-6492-2513 1 ,
- Fadoua Ataa Allah ORCID: orcid.org/0000-0001-7091-4412 2 &
- El Wardani Dadi ORCID: orcid.org/0000-0003-2946-854X 1
190 Accesses
3 Citations
Explore all metrics
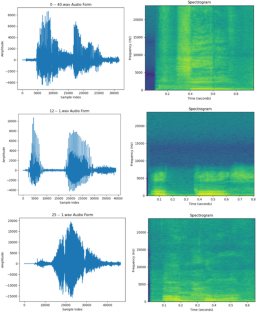
The availability of automatic speech recognition systems is crucial in various domains such as communication, healthcare, security, education, etc. However, currently, the existing systems often favor dominant languages such as English, French, Arabic, or Asian languages, leaving under-resourced languages without the consideration they deserve. In this specific context, our work is focused on the Amazigh language, which is widely spoken in North Africa. Our primary objective is to develop an automatic speech recognition system specifically for isolated words, with a particular focus on the Tarifit dialect spoken in the Rif region of Northern Morocco. For the dataset construction, we considered 30 isolated words recorded from 80 diverse speakers, resulting in 2400 audio files. The collected corpus is characterized by its quantity, quality, and variety. Moreover, the dataset serves as a valuable resource for further research and development in the field, supporting the advancement of speech recognition technology for underrepresented languages. For the recognition system, we have chosen the most recent approach in the field of speech recognition, which is a combination of convolutional neural networks and LSTM (CNN-LSTM). For the test, we have evaluated two different architectural models: the 1D CNN LSTM and the 2D CNN LSTM. The experimental results demonstrate a remarkable accuracy rate of over 96% in recognizing spoken words utilizing the 2D CNN LSTM architecture.
This is a preview of subscription content, log in via an institution to check access.
Access this article
Price includes VAT (Russian Federation)
Instant access to the full article PDF.
Rent this article via DeepDyve
Institutional subscriptions
Similar content being viewed by others

Recognition Method of Wa Language Isolated Words Based on Convolutional Neural Network

Isolated Word Automatic Speech Recognition System

An acoustic model and linguistic analysis for Malayalam disyllabic words: a low resource language
Data availability.
The data used in this study are not publicly available due to restrictions imposed by the LSA Laboratory. However, the data can be made available by the corresponding author upon reasonable request.
Abakarim, F., & Abenaou, A. (2020). Amazigh isolated word speech recognition system using the adaptive orthogonal transform method. 2020 International conference on intelligent systems and computer vision . https://doi.org/10.1109/ISCV49265.2020.9204291
Article Google Scholar
Abdullah, M., Ahmad, M., & Han, D. (2020). Facial expression recognition in videos: An CNN-LSTM based model for video classification. In 2020 International conference on electronics, information, and communication (ICEIC) (pp. 16–18). IEEE. https://doi.org/10.1109/ICEIC49074.2020.9051332
Ameur, M., Bouhjar, A., Boukhris, F., Boukouss, A., Boumalk, A., Elmedlaoui, M., El Mehdi, I., & Souifi, H. (2004). Initiation à la langue amazighe . El Maârif al Jadida.
Badshah, A. M., Rahim, N., Ullah, N., Ahmad, J., Muhammad, K., Lee, M. Y., Kwon, S., & Baik, S. W. (2019). Deep features-based speech emotion recognition for smart affective services. Multimedia Tools and Applications, 78 (5), 5571–5589. https://doi.org/10.1007/s11042-017-5292-7
Barkani, F., Hamidi, M., Laaidi, N., Zealouk, O., Satori, H., & Satori, K. (2023). Amazigh speech recognition based on the Kaldi ASR toolkit. International Journal of Information Technology . https://doi.org/10.1007/s41870-023-01354-z
Boukous, A. (1995). Société, langues et cultures au maroc : Enjeux symboliques (8th ed., p. 239). Faculté des Lettres et des Sciences Humaines, Université Mohamed V.
Google Scholar
Choi, K., Fazekas, G., Sandler, M., & Cho, K. (2018). A comparison of audio signal preprocessing methods for deep neural networks on music tagging. European Signal Processing Conference, 2018 , 1870–1874. https://doi.org/10.23919/EUSIPCO.2018.8553106
El Ouahabi, S., Atounti, M., & Bellouki, M. (2017). A database for Amazigh speech recognition research: AMZSRD. In Proceedings of 2017 International conference of cloud computing technologies and applications, CloudTech 2017, 2018-Janua (pp. 1–5). IEEE. https://doi.org/10.1109/CloudTech.2017.8284715
El Ouahabi, S., Atounti, M., & Bellouki, M. (2019a). Amazigh speech recognition using triphone modeling and clustering tree decision. Annals of the University of Craiova Mathematics and Computer Science Series, 46 (1), 55–65.
El Ouahabi, S., Atounti, M., & Bellouki, M. (2019b). Toward an automatic speech recognition system for Amazigh-tarifit language. International Journal of Speech Technology, 22 (2), 421–432. https://doi.org/10.1007/s10772-019-09617-6
El Ouahabi, S., Atounti, M., & Bellouki, M. (2020). Optimal parameters selected for automatic recognition of spoken Amazigh digits and letters using hidden Markov model toolkit. International Journal of Speech Technology, 23 (4), 861–871. https://doi.org/10.1007/s10772-020-09762-3
Essa, Y., Hunt, H. G. P., Gijben, M., & Ajoodha, R. (2022). Deep learning prediction of thunderstorm severity using remote sensing weather data. IEEE Journal of Selected Topics in Applied Earth Observations and Remote Sensing, 15 , 4004–4013. https://doi.org/10.1109/JSTARS.2022.3172785
Fadoua, A. A., & Siham, B. (2012). Natural language processing for Amazigh language: Challenges and future directions. Language Technology for Normalisation of Less-Resourced Languages, 19 , 23.
Hajarolasvadi, N., & Demirel, H. (2019). 3D CNN-based speech emotion recognition using k-means clustering and spectrograms. Entropy, 21 (5), 479. https://doi.org/10.3390/e21050479
Hochreiter, S., & Schmidhuber, J. (1997). Long short-term memory. Neural Computation, 9 (8), 1735–1780. https://doi.org/10.1162/neco.1997.9.8.1735
Idhssaine, A., & El Kirat, Y. (2021). Amazigh language use, perceptions and revitalisation in morocco: The case of rabat-sale region. Journal of North African Studies, 26 (3), 465–479. https://doi.org/10.1080/13629387.2019.1690996
Krizhevsky, A., Sutskever, I., & Hinton, G. E. (2017). ImageNet classification with deep convolutional neural networks. Communications of the ACM, 60 (6), 84–90. https://doi.org/10.1145/3065386
Lee, J., & Tashev, I. (2015). High-level feature representation using recurrent neural network for speech emotion recognition. In Proceedings of the annual conference of the international speech communication association, INTERSPEECH , 2015 - Janua (pp. 1537–1540). https://doi.org/10.21437/interspeech.2015-336
Oruh, J., Viriri, S., & Adegun, A. (2022). Long short-term memory recurrent neural network for automatic speech recognition. IEEE Access, 10 , 30069–30079. https://doi.org/10.1109/ACCESS.2022.3159339
Ouhnini, A., Aksasse, B., & Ouanan, M. (2023). Towards an automatic speech-to-text transcription system: Amazigh language. International Journal of Advanced Computer Science and Applications, 14 (2), 413–418. https://doi.org/10.14569/IJACSA.2023.0140250
Satori, H., & Elhaoussi, F. (2014). Investigation amazigh speech recognition using CMU tools. International Journal of Speech Technology, 17 (3), 235–243. https://doi.org/10.1007/s10772-014-9223-y
Telmem, M., & Ghanou, Y. (2020). A comparative study of HMMs and CNN acoustic model in amazigh recognition system. Advances in Intelligent Systems and Computing, 1076 , 533–540. https://doi.org/10.1007/978-981-15-0947-6_50
Telmem, M., & Ghanou, Y. (2021). The convolutional neural networks for Amazigh speech recognition system. Telkomnika (Telecommunication Computing Electronics and Control), 19 (2), 515–522. https://doi.org/10.12928/TELKOMNIKA.v19i2.16793
Vankdothu, R., Hameed, M. A., & Fatima, H. (2022). A brain tumor identification and classification using deep learning based on CNN-LSTM method. Computers and Electrical Engineering, 101 (November 2021), 107960. https://doi.org/10.1016/j.compeleceng.2022.107960
Zealouk, O., Satori, H., Laaidi, N., Hamidi, M., & Satori, K. (2020). Noise effect on Amazigh digits in speech recognition system. International Journal of Speech Technology, 23 (4), 885–892. https://doi.org/10.1007/s10772-020-09764-1
Download references
No funding was received for conducting this study. The authors declare they have no financial interests.
Author information
Authors and affiliations.
LSA laboratory, ENSAH, SOVIA Team, University of Abdelmalek Essaadi, Tetouan, Morocco
Mohamed Daouad & El Wardani Dadi
CEISIC, The Royal Institute of the Amazigh Culture, Rabat, Morocco
Fadoua Ataa Allah
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Mohamed Daouad .
Additional information
Publisher’s note.
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
Reprints and permissions
About this article
Daouad, M., Allah, F.A. & Dadi, E.W. An automatic speech recognition system for isolated Amazigh word using 1D & 2D CNN-LSTM architecture. Int J Speech Technol 26 , 775–787 (2023). https://doi.org/10.1007/s10772-023-10054-9
Download citation
Received : 22 June 2023
Accepted : 29 September 2023
Published : 11 October 2023
Issue Date : September 2023
DOI : https://doi.org/10.1007/s10772-023-10054-9
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Amazigh language
- Convolutional neural network
- Deep learning
- Spectrogram
- Speech recognition
- Find a journal
- Publish with us
- Track your research

An official website of the United States government
The .gov means it’s official. Federal government websites often end in .gov or .mil. Before sharing sensitive information, make sure you’re on a federal government site.
The site is secure. The https:// ensures that you are connecting to the official website and that any information you provide is encrypted and transmitted securely.
- Publications
- Account settings
- My Bibliography
- Collections
- Citation manager
Save citation to file
Email citation, add to collections.
- Create a new collection
- Add to an existing collection
Add to My Bibliography
Your saved search, create a file for external citation management software, your rss feed.
- Search in PubMed
- Search in NLM Catalog
- Add to Search
Application of an Isolated Word Speech Recognition System in the Field of Mental Health Consultation: Development and Usability Study
Affiliation.
- 1 Liberal Arts College, Hunan Normal University, Changsha, China.
- PMID: 32384054
- PMCID: PMC7301261
- DOI: 10.2196/18677
Background: Speech recognition is a technology that enables machines to understand human language.
Objective: In this study, speech recognition of isolated words from a small vocabulary was applied to the field of mental health counseling.
Methods: A software platform was used to establish a human-machine chat for psychological counselling. The software uses voice recognition technology to decode the user's voice information. The software system analyzes and processes the user's voice information according to many internal related databases, and then gives the user accurate feedback. For users who need psychological treatment, the system provides them with psychological education.
Results: The speech recognition system included features such as speech extraction, endpoint detection, feature value extraction, training data, and speech recognition.
Conclusions: The Hidden Markov Model was adopted, based on multithread programming under a VC2005 compilation environment, to realize the parallel operation of the algorithm and improve the efficiency of speech recognition. After the design was completed, simulation debugging was performed in the laboratory. The experimental results showed that the designed program met the basic requirements of a speech recognition system.
Keywords: HMM; hidden Markov model; isolated words; mental health; programming; small vocabulary; speech recognition.
©Weifeng Fu. Originally published in JMIR Medical Informatics (http://medinform.jmir.org), 03.06.2020.
PubMed Disclaimer
Conflict of interest statement
Conflicts of Interest: None declared.
Block diagram of speech recognition…
Block diagram of speech recognition system.
References use templates as word…
References use templates as word units. HMM: Hidden Markov Model.
Mel Frequency Cepstral Coefficient (MFCC)…
Mel Frequency Cepstral Coefficient (MFCC) calculation flow diagram. FFT: fast Fourier transform.
Mel Frequency Cepstral Coefficient (MFCC) scale corresponding curve.
Similar articles
- Frontier Research on Low-Resource Speech Recognition Technology. Slam W, Li Y, Urouvas N. Slam W, et al. Sensors (Basel). 2023 Nov 10;23(22):9096. doi: 10.3390/s23229096. Sensors (Basel). 2023. PMID: 38005483 Free PMC article. Review.
- Geospatial assistive technologies for wheelchair users: a scoping review of usability measures and criteria for mobile user interfaces and their potential applicability. Prémont MÉ, Vincent C, Mostafavi MA, Routhier F. Prémont MÉ, et al. Disabil Rehabil Assist Technol. 2020 Feb;15(2):119-131. doi: 10.1080/17483107.2018.1539876. Epub 2019 Jan 21. Disabil Rehabil Assist Technol. 2020. PMID: 30663444 Review.
- Effect of training on word-recognition performance in noise for young normal-hearing and older hearing-impaired listeners. Burk MH, Humes LE, Amos NE, Strauser LE. Burk MH, et al. Ear Hear. 2006 Jun;27(3):263-78. doi: 10.1097/01.aud.0000215980.21158.a2. Ear Hear. 2006. PMID: 16672795
- Development of a speech-based dialogue system for report dictation and machine control in the endoscopic laboratory. Molnar B, Gergely J, Toth G, Pronai L, Zagoni T, Papik K, Tulassay Z. Molnar B, et al. Endoscopy. 2000 Jan;32(1):58-61. doi: 10.1055/s-2000-136. Endoscopy. 2000. PMID: 10691274
- Adaptive communication systems for patients with mobility disorders. Zimmer CA, Devlin PM, Werner JL, Stamp CV, Bellian KT, Powell DM, Edlich RF. Zimmer CA, et al. J Burn Care Rehabil. 1991 Jul-Aug;12(4):354-60. J Burn Care Rehabil. 1991. PMID: 1834676
- Boussaid L, Hassine M. Arabic isolated word recognition system using hybrid feature extraction techniques and neural network. Int J Speech Technol. 2017 Nov 23;21(1):29–37. doi: 10.1007/s10772-017-9480-7. - DOI
- Bennettlevy J, Martin E, Bridgman H, Carey T.A, Isaacs A. N, Little F. Mental health academics in rural and remote Australia. Rural and remote health. 2016;16(3):3793–3793. - PubMed
- Wu S. A Traffic Motion Object Extraction Algorithm. Int J Bifurcation Chaos. 2016 Jan 14;25(14):1540039. doi: 10.1142/s0218127415400398. - DOI
- Fujii Y, Fujii K, Yoon J, Sugahara H, Kitano N, Okura T. The Effects Of Low-intensity Exercise On Depressive Symptoms In Socially-isolated Older Adults. Medicine & Science in Sports & Exercise. 2016;48:1052. doi: 10.1249/01.mss.0000488166.06405.c1. - DOI
- Elovainio M, Hakulinen C, Pulkki-Råback L, Virtanen M, Josefsson K, Jokela M, Vahtera J, Kivimäki M. Contribution of risk factors to excess mortality in isolated and lonely individuals: an analysis of data from the UK Biobank cohort study. The Lancet Public Health. 2017 Jun;2(6):e260–e266. doi: 10.1016/s2468-2667(17)30075-0. - DOI - PMC - PubMed
Related information
Linkout - more resources, full text sources.
- Europe PubMed Central
- JMIR Publications
- PubMed Central
Miscellaneous
- NCI CPTAC Assay Portal
- Citation Manager
NCBI Literature Resources
MeSH PMC Bookshelf Disclaimer
The PubMed wordmark and PubMed logo are registered trademarks of the U.S. Department of Health and Human Services (HHS). Unauthorized use of these marks is strictly prohibited.
IEEE Account
- Change Username/Password
- Update Address
Purchase Details
- Payment Options
- Order History
- View Purchased Documents
Profile Information
- Communications Preferences
- Profession and Education
- Technical Interests
- US & Canada: +1 800 678 4333
- Worldwide: +1 732 981 0060
- Contact & Support
- About IEEE Xplore
- Accessibility
- Terms of Use
- Nondiscrimination Policy
- Privacy & Opting Out of Cookies
A not-for-profit organization, IEEE is the world's largest technical professional organization dedicated to advancing technology for the benefit of humanity. © Copyright 2024 IEEE - All rights reserved. Use of this web site signifies your agreement to the terms and conditions.
Academia.edu no longer supports Internet Explorer.
To browse Academia.edu and the wider internet faster and more securely, please take a few seconds to upgrade your browser .
Enter the email address you signed up with and we'll email you a reset link.
- We're Hiring!
- Help Center

ISOLATED WORD SPEECH RECOGNITION SYSTEM USING HTK

2014, TJPRC
This paper proposes a system of Isolated Word Speech Recognition for Tamil language using Hidden Markov Model (HMM) approach. The most powerful Mel Frequency Cepstral Coefficients (MFCC) feature extraction technique is used to train the acoustic features of the speech database. The triphone based acoustic model is chosen to recognize the given Tamil digits. This system is a small vocabulary system where it is trained to identify the Tamil digits from one to ten. The result analysis of HTK (HMM Tool Kit) shows 90% of recognition accuracy at the word level.
Related Papers
— Speech recognition is the process of converting an acoustic waveform into the text similar to the information being conveyed by the speaker. In this paper implementation of isolated words and connected words Automatic Speech Recognition system (ASR) for the words of Hindi language will be discussed. The HTK (hidden markov model toolkit) based on Hidden Markov Model (HMM), a statistical approach, is used to develop the system. Initially the system is trained for 100 distinct Hindi words .This paper also describes the working of HTK tool, which is used in various phases of ASR system, by presenting a detailed architecture of an ASR system developed using various HTK library modules and tools. The recognition results will show that the overall system accuracy for isolated words is 95% and for connected words is 90%. Index Terms— HMM, HTK, Mel Frequency Cepstral Coefficient (MFCC), Automatic Speech Recognition (ASR), Hindi, Isolated word ASR, connected word ASR.
Mohamed Kalith Ibralebbe
Speech recognition technology has improved with time to enhanced Human Computer Interaction (HCI).This paper proposed a system for isolated to connected Tamil digit speech recognition system using CMU Sphinx tools. The connected speech recognition important in many application such as voice-dialling telephone, automated banking system automated data entry, pin entry etc. the proposed system is tri phone based, small vocabularies, speaker specific and speaker-independent. The most powerful Mel Frequency Cepstral Coefficient (MFCC) feature extraction techniques are used to train the acoustic feature of speech database. The probabilistic Hidden Markov Model (HMM) is used to model the speech utterance. And the Viterbi beam search algorithm is used in decoding process. The system tested with random digit (0 to 100) in a various condition shows optimum result 96.7% recognition rates for speaker specific and 54.5% recognition rate for speaker independent in connected word recognition. We use CMU sphinx speech recognition tools to construction of speech recognizer.
amritesh raj
nikita dhanvijay
This paper is based on SR system. In the speech recognition process computer takes a voice signal which is recorded using a microphone and converted into words in real-time. This SR system has been developed using different feature extraction techniques which include MFCC, HMM. All are used as the classifier. ASR i.e. automated speech recognition is program or we can called it as a machine, and it has ability to recognize the voice signal (speech signal or voice commands) or take dictation which involves the ability to match a voice pattern opposite to a given vocabulary. HTK i.e. The Hidden Markov model Toolkit is used to develop the SR System. HMM consist of the Acoustic word model which is used to recognize the isolated word. In this paper, we collect Hindi database, with a vocabulary size a bit extended. HMM has been implemented using the HTK Toolkit.
IJESRT Journal
This paper is based on SR system. In the speech recognition process computer takes a voice signal which is recorded using a microphone and converted into words in real-time. This SR system has been developed using different feature extraction techniques which include MFCC, HMM. All are used as the classifier. ASR i.e. automated speech recognition is program or we can called it as a machine, and it has ability to recognize the voice signal (speech signal or voice commands) or take dictation which involves the ability to match a voice pattern opposite to a given vocabulary. HTK i.e. The Hidden Markov model Toolkit is used to develop the SR System. HMM consist of the Acoustic word model which is used to recognize the isolated word. In this paper, we collect Hindi database, with a vocabulary size a bit extended. HMM has been implemented using the HTK Toolkit. KEYWORDS: HMM (hidden markov model), ASR (Automatic Speech Recognition), Speech recognition (SR). MFCC (mel frequency cepestral coefficient)
Ishan Bhardwaj
International Journal of Engineering Research and Technology (IJERT)
IJERT Journal
https://www.ijert.org/sanskrit-speech-recognition-using-hidden-markov-model-toolkit https://www.ijert.org/research/sanskrit-speech-recognition-using-hidden-markov-model-toolkit-IJERTV3IS100141.pdf Automated Speech Recognition (ASR) is the ability of a machine or program to recognize the voice commands or take dictation which involves the ability to match a voice pattern against a provided or acquired vocabulary. At present, mainly Hidden Markov Model (HMMs) based speech recognizers are used. This research work aims to build a speech recognition system for Sanskrit language. Hidden Markov Model Toolkit (HTK) is used to develop the system. The system is trained to recognize 50 Sanskrit utterances. Training data has been collected from ten speakers. The experimental results show that the overall accuracy of the presented system with 5 state and 10 states in HMM topology is 95.2% to 97.2% respectively.
International Journal of Physical Sciences
Mondher Frikha
iswarya ganesh
In recent years, Human-Computer Interaction is one of the upcoming technologies which allows human to communicate with computer by speech and enables machine to understand human communication. Speech Recognition is the fascinating field in Human-Computer Interaction which has attained certain level of maturity in English language and still startup level in Indian languages. Most widely used feature extraction technique in digital signal processing is Linear Predictive Cepstral Coefficient and Mel Frequency Cepstral Coefficient. This paper presents comparative analysis of Linear Predictive Cepstral Coefficient and Mel Frequency Cepstral Coefficient feature extraction methods for isolated speech database in Tamil language. Probabilistic neural network is widely used in research to find more efficient classification solutions. From each speech sample frame 8, 12 and 24 feature vectors of Linear Predictive cepstral coefficient and Mel frequency cepstral coefficient are extracted and classified using probabilistic neural network. The experimental results shows that 24 feature vectors extracted using Mel frequency cepstral coefficient provides better recognition accuracy of 97% for isolated Tamil words, when compared with 8,12- Mel frequency cepstral coefficient and 8,12,24- Linear Predictive cepstral coefficient feature vectors respectively.
Abdullah - al - mamun
here we present a model of isolated speech recognition (ISR) system for Bangla character set and analysis the performance of that recognizer model. In this isolated Bangla speech recognition is implemented by the combining MFCC as feature extraction for the input audio file and used Hidden Markov Model (HMM) for training & recognition due to HMMs uncomplicated and effective framework for modeling time-varying sequence of spectral feature vector. A series of experiments have been performed with 10-talkers (5 male and 5 female) by 56 Bangla characters (include, Bangla vowel, Bangla consonant, Bangla
Loading Preview
Sorry, preview is currently unavailable. You can download the paper by clicking the button above.
RELATED PAPERS
International Journal of Recent Technology and Engineering
anand unnibhavi
Achyuta Nand Mishra
Shweta Sinha
Cini Kurian
International Journal of Engineering Sciences & Research Technology
Ijesrt Journal
Journal of Signal and Information Processing
PROF MAHUA BHATTACHARYA
Computing Research Repository
Hemakumar Gopal
Elizabeth Sherly
International Journal of Computer Applications
Neeta Awasthy
Current Journal of Applied Science and Technology
David Asirvatham
Journal of Physics: Conference Series
Nindian Puspa Dewi
IJSRD Journal
Intl. J. of Multidisciplinary Research and Development
Md. Mijanur Rahman , Ashraful Kadir
Engineering Advancements RSEA
Supun Molligoda
2013 IEEE Second International Conference on Image Information Processing (ICIIP-2013)
neha baranwal
bhargab Medhi
Professor (Dr.) Ratnadeep R . Deshmukh
Dalmiya C P
vikram karimella
- We're Hiring!
- Help Center
- Find new research papers in:
- Health Sciences
- Earth Sciences
- Cognitive Science
- Mathematics
- Computer Science
- Academia ©2024
IMAGES
VIDEO
COMMENTS
The Development Workflow. There are two major stages within isolated word recognition: a training stage and a testing stage. Training involves "teaching" the system by building its dictionary, an acoustic model for each word that the system needs to recognize. In our example, the dictionary comprises the digits 'zero' to 'nine'.
The paper is devoted to an isolated word automatic speech recognition. The first part deals with a theoretical description of methods for speech signal processing and algorithms which can be used for automatic speech recognition such as a dynamic time warping, hidden Markov models and deep neural networks. The practical part is focused on the ...
The following problems are to be solved by the isolated word speech recognition system based on the HMM: First, how to determine an optimal state transition sequence q = (q 1,q 2,…,q T), and calculate the output probability P(O|λ) of the observation sequence O = o 1,o 2,…o T to the HMM, and judge the recognition result of the voice command ...
Data are instances of isolated spoken words Sequence of feature vectors derived from speech signal, typically 1 vector from a 25ms frame of speech, with frames shifted by 10ms. ... 6.345 Automatic Speech Recognition Designing HMM-based speech recognition systems 13 . Computing Best Path Scores for Viterbi Decoding The approximate score for a ...
This research aims to design and develop an accurate speech recognition system for a set of predefined words collected from short audio clips. It uses The Speech Commands Dataset v0.01 provided by Google's TensorFlow. Isolated word speech recognition can be implemented in voice user interfaces for applications with key-word spotting. The end goal is to classify and recognize ten words, along ...
Speaker-dependent speech recognition system requires the system should not only recognize speech, but also recognize the speaker of the segment. In this paper, two indicators are selected-short-time average zero-crossing rate and dual-threshold endpoint to test the signal endpoint through the study of speaker-dependent isolated-word speech characteristics, and MFCC parameters are taken as the ...
Automatic Speech Recognition (ASR) System is defined as transformation of acoustic speech signals to string of words. This paper presents an approach of ASR system based on isolated word structure using Mel-Frequency Cepstral Coefficients (MFCC's), Dynamic Time Wrapping (DTW) and K-Nearest Neighbor (KNN) techniques. The Mel-Frequency scale used to capture the significant characteristics of the ...
release (1968) IBM was just getting started with a large speech recognition. project that led to a very successful large vocabulary isolated word dictation. system and several small vocabulary control systems. In the middle nineties. IBM's VoiceType, Dragon Systems' DragonDictate, and Kurzweil Applied. Intelligence's.
The paper is devoted to an isolated word automatic speech recognition. The first part deals with a theoretical description of methods for speech signal processing and algorithms which can be used ...
For voice command system, it is based on implementation of isolated-word speech recognition and it can include many applications, such as voice-activated devices, robots, access control system, etc.
A real time isolated word speech recognition system for humancomputer interaction to recognize a list of words in which the speaker says through the microphone using the melfrequency cepstral coefficients. This paper includes a new approach to develop a real time isolated word speech recognition system for humancomputer interaction. The system is a speaker dependent system.
Isolated word versus continuous speech: Some speech systems only need identify single words at a time (e.g., speaking a number to route a phone call to a company to the appropriate person), while others must recognize sequences of words at a time. The isolated word systems are, not surprisingly, easier to construct and can be quite robust as
Summary. This lecture is intended to provide an insight into some of the algorithms and techniques that lie behind contemporary automatic speech recognition systems. It is noted that, due to the lack of success of earlier phonetically motivated approaches, the majority of current speech recognizers employ whole-word pattern matching techniques.
The objective of this work was to develop an isolated word speech recognition system for children with Down syndrome to communicate with others, almost normally. These children are delayed in the use of meaningful speech and slower to obtain a fruitful vocabulary due to their large tongue and other factors. In this thesis, single
The aim of this work is to develop an isolated-word speech recognition system for the Amazigh language. A particular interest is devoted to Tarifit dialect used in our region. To develop an efficient system and in order to fully leverage the benefits of deep learning, we employed a combination of convolutional neural networks and long short ...
Abstract —The paper presents a design of an isolated word. speaker recognizer syste m by using the Hi dden Markov Model. HTK toolkit is use d as a design tool. The system is o perated on a ...
N ex t, the sa m p led the speech signal at the inpu t has already been segm en ted in to an iso latedw ord .Then , the signal-to-sym bo l. en ted in to iso latedw ords and converted to a sequence of d iscrete observab les { O t } . For now let us assum e. 2 . Speech recogn ition system.
Background: Speech recognition is a technology that enables machines to understand human language. Objective: In this study, speech recognition of isolated words from a small vocabulary was applied to the field of mental health counseling. Methods: A software platform was used to establish a human-machine chat for psychological counselling.
Speech recognition is an interdisciplinary field drawing from computer science, linguistics, and computer engineering. Many modern devices have speech recognition functions in them to allow for easier. The demand for speech recognition in new languages corresponds to cultural preservation, accessibility, market growth, research, enhanced efficiency, innovation, and empowerment, rendering it a ...
This paper includes a new approach to develop a real time isolated word speech recognition system for human-computer interaction. The system is a speaker dependent system. The main motive behind developing this system is to recognize a list of words in which the speaker says through the microphone. The features used are the mel-
RECOGNITION SYSTEMS Speech recognition systems are generally classified as discrete or continuous systems that are speaker dependent, independent, or adaptive. Discrete systems maintain a separate acoustic model for each word, combination of words, or phrases and are referred to as isolated (word) speech recognition (ISR).Connected word
recognition system for isolated words using band pass filters. The features used were the energy .ogniuon rate of the order of 'Yo was reported of fifteen words and ten digits In 1985, Lau and Chan :ramed, isolated woru recognition system based energv level of the speech signal as features of the rate of the system was 9n5 % for a small vocabulary
— Speech recognition is the process of converting an acoustic waveform into the text similar to the information being conveyed by the speaker. In this paper implementation of isolated words and connected words Automatic Speech Recognition system (ASR) for the words of Hindi language will be discussed.