
Make Random Student Groups
Make random student groups #.
This page demonstrates how to make a Python function called make_random_groups() that will take a list of student names and randomly create a desired number of groups from the list.
Import random module #
Make list of students #.
Here’s a list of student names. Yes, in this scenario, I’m teaching the NBA’s all-star basketball players.
Create make_random_groups() function #
Use make_random_groups() function #, make random student groups explained in more detail #, shuffle the order of the students #, extract a certain number of groups from the list of randomly shuffled students #.
all_groups = []
creates an empty list
range(number_of_groups)
creates a sequence of numbers from 0 to the desired number of groups
represents each number in that sequence
students[index::number_of_groups]
extracts a group of students from the list by selecting the student at whatever position in the list index represents, then jumping forward by number_of_groups spots to select a student at that position in the list, etc
all_groups.append(group)
adds each group to a master list
Let’s say we have 15 students and want 5 random groups. For each index aka number in range(5) — (0,1,2,3,4) — we make a group by selecting students[index::5] .
Group 1 students[0::5] We select the 0th student in the randomly shuffled list, then jump by 5 to select the 5th person in the list, and then jump by 5 to take the 10th person in the list.
Group 2 students[1::5] We select the 1st student in the randomly shuffled list, then jump by 5 to select the 6th person in the list, and then jump by 5 to take the 11th person in the list.
Group 3 students[2::5] We select the 2nd student in the randomly shuffled list, then jump by 5 to select the 7th person in the list, and then jump by 5 to take the 12th person in the list.
Group 4 students[3::5] We select the 3rd student in the randomly shuffled list, then jump by 5 to select the 8th person in the list, and then jump by 5 to take the 13th person in the list.
Group 5 students[4::5] We select the 4th student in the randomly shuffled list, then jump by 5 to select the 9th person in the list, and then jump by 5 to take the 14th person in the list.
Format and display each group #
- Python »
- 3.12.5 Documentation »
- The Python Standard Library »
- Numeric and Mathematical Modules »
- random — Generate pseudo-random numbers
- Theme Auto Light Dark |
random — Generate pseudo-random numbers ¶
Source code: Lib/random.py
This module implements pseudo-random number generators for various distributions.
For integers, there is uniform selection from a range. For sequences, there is uniform selection of a random element, a function to generate a random permutation of a list in-place, and a function for random sampling without replacement.
On the real line, there are functions to compute uniform, normal (Gaussian), lognormal, negative exponential, gamma, and beta distributions. For generating distributions of angles, the von Mises distribution is available.
Almost all module functions depend on the basic function random() , which generates a random float uniformly in the half-open range 0.0 <= X < 1.0 . Python uses the Mersenne Twister as the core generator. It produces 53-bit precision floats and has a period of 2**19937-1. The underlying implementation in C is both fast and threadsafe. The Mersenne Twister is one of the most extensively tested random number generators in existence. However, being completely deterministic, it is not suitable for all purposes, and is completely unsuitable for cryptographic purposes.
The functions supplied by this module are actually bound methods of a hidden instance of the random.Random class. You can instantiate your own instances of Random to get generators that don’t share state.
Class Random can also be subclassed if you want to use a different basic generator of your own devising: see the documentation on that class for more details.
The random module also provides the SystemRandom class which uses the system function os.urandom() to generate random numbers from sources provided by the operating system.
The pseudo-random generators of this module should not be used for security purposes. For security or cryptographic uses, see the secrets module.
M. Matsumoto and T. Nishimura, “Mersenne Twister: A 623-dimensionally equidistributed uniform pseudorandom number generator”, ACM Transactions on Modeling and Computer Simulation Vol. 8, No. 1, January pp.3–30 1998.
Complementary-Multiply-with-Carry recipe for a compatible alternative random number generator with a long period and comparatively simple update operations.
Bookkeeping functions ¶
Initialize the random number generator.
If a is omitted or None , the current system time is used. If randomness sources are provided by the operating system, they are used instead of the system time (see the os.urandom() function for details on availability).
If a is an int, it is used directly.
With version 2 (the default), a str , bytes , or bytearray object gets converted to an int and all of its bits are used.
With version 1 (provided for reproducing random sequences from older versions of Python), the algorithm for str and bytes generates a narrower range of seeds.
Changed in version 3.2: Moved to the version 2 scheme which uses all of the bits in a string seed.
Changed in version 3.11: The seed must be one of the following types: None , int , float , str , bytes , or bytearray .
Return an object capturing the current internal state of the generator. This object can be passed to setstate() to restore the state.
state should have been obtained from a previous call to getstate() , and setstate() restores the internal state of the generator to what it was at the time getstate() was called.
Functions for bytes ¶
Generate n random bytes.
This method should not be used for generating security tokens. Use secrets.token_bytes() instead.
Added in version 3.9.
Functions for integers ¶
Return a randomly selected element from range(start, stop, step) .
This is roughly equivalent to choice(range(start, stop, step)) but supports arbitrarily large ranges and is optimized for common cases.
The positional argument pattern matches the range() function.
Keyword arguments should not be used because they can be interpreted in unexpected ways. For example randrange(start=100) is interpreted as randrange(0, 100, 1) .
Changed in version 3.2: randrange() is more sophisticated about producing equally distributed values. Formerly it used a style like int(random()*n) which could produce slightly uneven distributions.
Changed in version 3.12: Automatic conversion of non-integer types is no longer supported. Calls such as randrange(10.0) and randrange(Fraction(10, 1)) now raise a TypeError .
Return a random integer N such that a <= N <= b . Alias for randrange(a, b+1) .
Returns a non-negative Python integer with k random bits. This method is supplied with the Mersenne Twister generator and some other generators may also provide it as an optional part of the API. When available, getrandbits() enables randrange() to handle arbitrarily large ranges.
Changed in version 3.9: This method now accepts zero for k .
Functions for sequences ¶
Return a random element from the non-empty sequence seq . If seq is empty, raises IndexError .
Return a k sized list of elements chosen from the population with replacement. If the population is empty, raises IndexError .
If a weights sequence is specified, selections are made according to the relative weights. Alternatively, if a cum_weights sequence is given, the selections are made according to the cumulative weights (perhaps computed using itertools.accumulate() ). For example, the relative weights [10, 5, 30, 5] are equivalent to the cumulative weights [10, 15, 45, 50] . Internally, the relative weights are converted to cumulative weights before making selections, so supplying the cumulative weights saves work.
If neither weights nor cum_weights are specified, selections are made with equal probability. If a weights sequence is supplied, it must be the same length as the population sequence. It is a TypeError to specify both weights and cum_weights .
The weights or cum_weights can use any numeric type that interoperates with the float values returned by random() (that includes integers, floats, and fractions but excludes decimals). Weights are assumed to be non-negative and finite. A ValueError is raised if all weights are zero.
For a given seed, the choices() function with equal weighting typically produces a different sequence than repeated calls to choice() . The algorithm used by choices() uses floating-point arithmetic for internal consistency and speed. The algorithm used by choice() defaults to integer arithmetic with repeated selections to avoid small biases from round-off error.
Added in version 3.6.
Changed in version 3.9: Raises a ValueError if all weights are zero.
Shuffle the sequence x in place.
To shuffle an immutable sequence and return a new shuffled list, use sample(x, k=len(x)) instead.
Note that even for small len(x) , the total number of permutations of x can quickly grow larger than the period of most random number generators. This implies that most permutations of a long sequence can never be generated. For example, a sequence of length 2080 is the largest that can fit within the period of the Mersenne Twister random number generator.
Changed in version 3.11: Removed the optional parameter random .
Return a k length list of unique elements chosen from the population sequence. Used for random sampling without replacement.
Returns a new list containing elements from the population while leaving the original population unchanged. The resulting list is in selection order so that all sub-slices will also be valid random samples. This allows raffle winners (the sample) to be partitioned into grand prize and second place winners (the subslices).
Members of the population need not be hashable or unique. If the population contains repeats, then each occurrence is a possible selection in the sample.
Repeated elements can be specified one at a time or with the optional keyword-only counts parameter. For example, sample(['red', 'blue'], counts=[4, 2], k=5) is equivalent to sample(['red', 'red', 'red', 'red', 'blue', 'blue'], k=5) .
To choose a sample from a range of integers, use a range() object as an argument. This is especially fast and space efficient for sampling from a large population: sample(range(10000000), k=60) .
If the sample size is larger than the population size, a ValueError is raised.
Changed in version 3.9: Added the counts parameter.
Changed in version 3.11: The population must be a sequence. Automatic conversion of sets to lists is no longer supported.
Discrete distributions ¶
The following function generates a discrete distribution.
Binomial distribution . Return the number of successes for n independent trials with the probability of success in each trial being p :
Mathematically equivalent to:
The number of trials n should be a non-negative integer. The probability of success p should be between 0.0 <= p <= 1.0 . The result is an integer in the range 0 <= X <= n .
Added in version 3.12.
Real-valued distributions ¶
The following functions generate specific real-valued distributions. Function parameters are named after the corresponding variables in the distribution’s equation, as used in common mathematical practice; most of these equations can be found in any statistics text.
Return the next random floating-point number in the range 0.0 <= X < 1.0
Return a random floating-point number N such that a <= N <= b for a <= b and b <= N <= a for b < a .
The end-point value b may or may not be included in the range depending on floating-point rounding in the expression a + (b-a) * random() .
Return a random floating-point number N such that low <= N <= high and with the specified mode between those bounds. The low and high bounds default to zero and one. The mode argument defaults to the midpoint between the bounds, giving a symmetric distribution.
Beta distribution. Conditions on the parameters are alpha > 0 and beta > 0 . Returned values range between 0 and 1.
Exponential distribution. lambd is 1.0 divided by the desired mean. It should be nonzero. (The parameter would be called “lambda”, but that is a reserved word in Python.) Returned values range from 0 to positive infinity if lambd is positive, and from negative infinity to 0 if lambd is negative.
Changed in version 3.12: Added the default value for lambd .
Gamma distribution. ( Not the gamma function!) The shape and scale parameters, alpha and beta , must have positive values. (Calling conventions vary and some sources define ‘beta’ as the inverse of the scale).
The probability distribution function is:
Normal distribution, also called the Gaussian distribution. mu is the mean, and sigma is the standard deviation. This is slightly faster than the normalvariate() function defined below.
Multithreading note: When two threads call this function simultaneously, it is possible that they will receive the same return value. This can be avoided in three ways. 1) Have each thread use a different instance of the random number generator. 2) Put locks around all calls. 3) Use the slower, but thread-safe normalvariate() function instead.
Changed in version 3.11: mu and sigma now have default arguments.
Log normal distribution. If you take the natural logarithm of this distribution, you’ll get a normal distribution with mean mu and standard deviation sigma . mu can have any value, and sigma must be greater than zero.
Normal distribution. mu is the mean, and sigma is the standard deviation.
mu is the mean angle, expressed in radians between 0 and 2* pi , and kappa is the concentration parameter, which must be greater than or equal to zero. If kappa is equal to zero, this distribution reduces to a uniform random angle over the range 0 to 2* pi .
Pareto distribution. alpha is the shape parameter.
Weibull distribution. alpha is the scale parameter and beta is the shape parameter.
Alternative Generator ¶
Class that implements the default pseudo-random number generator used by the random module.
Changed in version 3.11: Formerly the seed could be any hashable object. Now it is limited to: None , int , float , str , bytes , or bytearray .
Subclasses of Random should override the following methods if they wish to make use of a different basic generator:
Override this method in subclasses to customise the seed() behaviour of Random instances.
Override this method in subclasses to customise the getstate() behaviour of Random instances.
Override this method in subclasses to customise the setstate() behaviour of Random instances.
Override this method in subclasses to customise the random() behaviour of Random instances.
Optionally, a custom generator subclass can also supply the following method:
Override this method in subclasses to customise the getrandbits() behaviour of Random instances.
Class that uses the os.urandom() function for generating random numbers from sources provided by the operating system. Not available on all systems. Does not rely on software state, and sequences are not reproducible. Accordingly, the seed() method has no effect and is ignored. The getstate() and setstate() methods raise NotImplementedError if called.
Notes on Reproducibility ¶
Sometimes it is useful to be able to reproduce the sequences given by a pseudo-random number generator. By reusing a seed value, the same sequence should be reproducible from run to run as long as multiple threads are not running.
Most of the random module’s algorithms and seeding functions are subject to change across Python versions, but two aspects are guaranteed not to change:
If a new seeding method is added, then a backward compatible seeder will be offered.
The generator’s random() method will continue to produce the same sequence when the compatible seeder is given the same seed.
Basic examples:
Simulations:
Example of statistical bootstrapping using resampling with replacement to estimate a confidence interval for the mean of a sample:
Example of a resampling permutation test to determine the statistical significance or p-value of an observed difference between the effects of a drug versus a placebo:
Simulation of arrival times and service deliveries for a multiserver queue:
Statistics for Hackers a video tutorial by Jake Vanderplas on statistical analysis using just a few fundamental concepts including simulation, sampling, shuffling, and cross-validation.
Economics Simulation a simulation of a marketplace by Peter Norvig that shows effective use of many of the tools and distributions provided by this module (gauss, uniform, sample, betavariate, choice, triangular, and randrange).
A Concrete Introduction to Probability (using Python) a tutorial by Peter Norvig covering the basics of probability theory, how to write simulations, and how to perform data analysis using Python.
These recipes show how to efficiently make random selections from the combinatoric iterators in the itertools module:
The default random() returns multiples of 2⁻⁵³ in the range 0.0 ≤ x < 1.0 . All such numbers are evenly spaced and are exactly representable as Python floats. However, many other representable floats in that interval are not possible selections. For example, 0.05954861408025609 isn’t an integer multiple of 2⁻⁵³.
The following recipe takes a different approach. All floats in the interval are possible selections. The mantissa comes from a uniform distribution of integers in the range 2⁵² ≤ mantissa < 2⁵³ . The exponent comes from a geometric distribution where exponents smaller than -53 occur half as often as the next larger exponent.
All real valued distributions in the class will use the new method:
The recipe is conceptually equivalent to an algorithm that chooses from all the multiples of 2⁻¹⁰⁷⁴ in the range 0.0 ≤ x < 1.0 . All such numbers are evenly spaced, but most have to be rounded down to the nearest representable Python float. (The value 2⁻¹⁰⁷⁴ is the smallest positive unnormalized float and is equal to math.ulp(0.0) .)
Generating Pseudo-random Floating-Point Values a paper by Allen B. Downey describing ways to generate more fine-grained floats than normally generated by random() .
Table of Contents
- Bookkeeping functions
- Functions for bytes
- Functions for integers
- Functions for sequences
- Discrete distributions
- Real-valued distributions
- Alternative Generator
- Notes on Reproducibility
Previous topic
fractions — Rational numbers
statistics — Mathematical statistics functions
- Report a Bug
- Show Source
Python Programming
Python Random Module: Generate Random Numbers and Data
This lesson demonstrates how to generate random data in Python using a random module. In Python, a random module implements pseudo-random number generators for various distributions, including integer and float (real).
Random Data Series
This Python random data generation series contains the following in-depth tutorial . You can directly read those.
- Python random intenger number : Generate random numbers using randint() and randrange().
- Python random choice : Select a random item from any sequence such as list, tuple, set.
- Python random sample : Select multiple random items (k sized random samples) from a list or set.
- Python weighted random choices : Select multiple random items with probability (weights) from a list or set.
- Python random seed : Initialize the pseudorandom number generator with a seed value.
- Python random shuffle : Shuffle or randomize the any sequence in-place.
- Python random float number using uniform() : Generate random float number within a range.
- Generate random string and passwords in Python : Generate a random string of letters. Also, create a random password with a combination of letters, digits, and symbols.
- Cryptographically secure random generator in Python : Generate a cryptographically secure random number using synchronization methods to ensure that no two processes can obtain the same data simultaneously.
- Python Secrets module : Use the secrets module to secure random data in Python 3.6 and above.
- Python UUID Module : Generate random Universally unique IDs
- Python Random data generation Quiz
- Python Random data generation Exercise
How to Use a random module
You need to import the random module in your program, and you are ready to use this module. Use the following statement to import the random module in your code.
As you can see in the result, we have got 0.50. You may get a different number.
- The random.random() is the most basic function of the random module.
- Almost all functions of the random module depend on the basic function random().
- random() return the next random floating-point number in the range [0.0, 1.0).
Random module functions
Now let see the different functions available in the random module and their usage.
Click on each function to study it in detail.
| Function | Meaning |
|---|---|
| Generate a random integer number within a range to . | |
| Returns a random integer number within a range by specifying the increment. | |
| Select a random item from a such as a list, string. | |
| Returns a sized random samples from a such as a list or set | |
| Returns a sized weighted random choices with probability ( ) from a such as a list or set | |
| Initialize the pseudorandom number generator with a seed value . | |
| Shuffle or randomize the sequence in-place. | |
| Returns a random floating-point number within a range | |
| Generate a random floating-point number such that and with the specified mode between those bounds | |
| Returns a random floating-point number with the beta distribution in such a way that . | |
| It returns random floating-point numbers, exponentially distributed. If is positive, it returns values range from 0 to positive infinity. Else from negative infinity to 0 if is negative. | |
| Returns a random floating-point number N with gamma distribution such that |
random.triangular(low, high, mode)
The random.triangular() function returns a random floating-point number N such that lower <= N <= upper and with the specified mode between those bounds.
The default value of a lower bound is ZERO, and the upper bounds are one. Moreover, the peak argument defaults to the midpoint between the bounds, giving a symmetric distribution.
Use the random.triangular() function to generate random numbers for triangular distribution to use these numbers in a simulation. i.e., to generate value from a triangular probability distribution.
Generate random String
Refer to Generate the random string and passwords in Python .
This guide includes the following things: -
- Generate a random string of any length.
- Generate the random password, which contains the letters, digits, and special symbols.
Cryptographically secure random generator in Python
Random Numbers and data generated by the random module are not cryptographically secure.
The cryptographically secure random generator generates random data using synchronization methods to ensure that no two processes can obtain the same data simultaneously.
A secure random generator is useful for security-sensitive applications such as OTP generation.
We can use the following approaches to secure the random generator in Python.
- The secrets module to secure random data in Python 3.6 and above.
- Use the random.SystemRandom class in Python 2.
Get and Set the state of random Generator
The random module has two functions: random.getstate() and random.setstate() to capture the random generator's current internal state. Using these functions, we can generate the same random numbers or sequence of data.
random.getstate()
The getstate() function returns a tuple object by capturing the current internal state of the random generator. We can pass this state to the setstate() method to restore this state as a current state.
random.setstate(state)
The setstate() function restores the random generator's internal state to the state object passed to it.
Note : By changing the state to the previous state, we can get the same random data. For example, If you want to get the same sample items again, you can use these functions.
If you get a previous state and restore it, you can reproduce the same random data repeatedly. Let see the example now to get and set the state of a random generator in Python.
As you can see in the output, we are getting the same sample list because we use the same state again and again
Numpy random package for multidimensional array
PRNG is an acronym for pseudorandom number generator. As you know, using the Python random module, we can generate scalar random numbers and data.
Use a NumPy module to generate a multidimensional array of random numbers. NumPy has the numpy.random package has multiple functions to generate the random n-dimensional array for various distributions.
Create an n-dimensional array of random float numbers
- Use a random.rand(d0, d1, …, dn) function to generate an n-dimensional array of random float numbers in the range of [0.0, 1.0) .
- Use a random.uniform(low=0.0, high=1.0, size=None) function to generate an n-dimensional array of random float numbers in the range of [low, high) .
Generate an n-dimensional array of random integers
Use the random.random_integers(low, high=None, size=None) to generate a random n-dimensional array of integers.
Generate random Universally unique IDs
Python UUID Module provides immutable UUID objects. UUID is a Universally Unique Identifier. It has the functions to generate all versions of UUID. Using the uuid4( ) function of a UUID module, you can generate a 128 bit long random unique ID ad it's cryptographically safe.
These unique ids are used to identify the documents, Users, resources, or information in computer systems.
Dice Game Using a Random module
I have created a simple dice game to understand random module functions. In this game, we have two players and two dice.
- One by one, each Player shuffle both the dice and play.
- The algorithm calculates the sum of two dice numbers and adds it to each Player's scoreboard.
- The Player who scores high number is the winner .
Reference : -
- Python Random Module Official Documentation
- Numpy random - Official Documentation
Exercise and Quiz
To practice what you learned in this tutorial, I have created a Quiz and Exercise project.
- Solve a Python Random data generation Quiz to test your random data generation concepts.
- Solve the Python Random data generation Exercise to practice and master the random data generation techniques.
All random data generation tutorials:
Python weighted random choices to choose from the list with different probability
Updated on: June 16, 2021 | 8 Comments
Python Random Data Generation Quiz
Updated on: February 24, 2024 | 3 Comments
Python random Data generation Exercise
Updated on: December 8, 2021 | 13 Comments
Python UUID Module to Generate Universally Unique Identifiers
Updated on: March 9, 2021 | Leave a Comment
Python Secrets Module to Generate secure random numbers for managing secrets
Updated on: June 16, 2021 | 11 Comments
Python random.shuffle() function to shuffle list
Updated on: June 16, 2021 | 6 Comments
Python random.seed() function to initialize the pseudo-random number generator
Updated on: May 3, 2024 | 9 Comments
Generate Random Strings and Passwords in Python
Updated on: February 16, 2022 | 20 Comments
Python random sample() to choose multiple items from any sequence
Updated on: July 25, 2021 | 16 Comments
Python random choice() function to select a random item from a List and Set
Updated on: July 22, 2023 | 14 Comments
Generate Random Float numbers in Python using random() and Uniform()
Updated on: June 16, 2021 | 3 Comments
Generate Cryptographically secure random numbers and data in Python
Updated on: March 9, 2021 | 3 Comments
Python random randrange() and randint() to generate random integer number within a range
Updated on: October 1, 2022 | 18 Comments
About PYnative
PYnative.com is for Python lovers. Here, You can get Tutorials, Exercises, and Quizzes to practice and improve your Python skills .
Explore Python
- Learn Python
- Python Basics
- Python Databases
- Python Exercises
- Python Quizzes
- Online Python Code Editor
- Python Tricks
To get New Python Tutorials, Exercises, and Quizzes
Legal Stuff
We use cookies to improve your experience. While using PYnative, you agree to have read and accepted our Terms Of Use , Cookie Policy , and Privacy Policy .
Copyright © 2018–2024 pynative.com

Python Random Module Tutorial
The Python random module is a built-in library that allows you to create random numbers and random choices. It’s useful for tasks where you need unpredictability, such as in games, simulations, and data sampling.
This module generates pseudo-random numbers, which means the numbers are generated using algorithms that mimic randomness but are deterministic. This is usually sufficient for most applications but may not be suitable for cryptographic purposes.

The random module is very versatile and can be used in many different scenarios:
- Simulations and Modeling : Creating random events to mimic real-life processes.
- Games and Entertainment : Generating random game elements like dice rolls, shuffled decks of cards, or random enemy movements.
- Data Sampling : Selecting random samples from large datasets for analysis or testing.
- Security : Generating random passwords or keys (although for high-security needs, the secrets module is recommended instead).
Here’s what we will learn in this tutorial.
Getting Started with the Random Module
To use the random module, you first need to import it into your Python program:
Now, let’s learn about the starting functions of the random module.
Generating random numbers using random()
The random.random() function generates a random floating-point number between 0.0 and 1.0, where 0.0 is inclusive and 1.0 is exclusive. This means the result could be any number from 0.0 up to, but not including, 1.0.
Generating random floating-point numbers
If you need a random floating-point number within a specific range, you can use random.uniform(a, b) . This function will give you a random float between the values a and b , both inclusive.
Here, random_float will be a random number like 4.237 or 9.482, and it will be between 1.0 and 10.0.
Generating Random Integers
When working with random numbers in Python, you often need to generate random integers. The random module in Python provides two useful functions for this purpose: randint(a, b) and randrange(start, stop, step) .
Using randint(a, b)
The randint(a, b) function generates a random integer between two specified values, a and b . Both a and b are inclusive, meaning the result can be a , b , or any integer in between.
When you run this code, you might get any integer between 1 and 10, such as 3, 7, or 10.
Using randrange(start, stop, step)
The randrange(start, stop, step) function generates a random number from a range that starts at start , ends before stop , and increments by step . This gives you more control over the range and the numbers you get. You can use this function to get a random even number or odd number.
Generating Random Sequences
The randrange() function is also handy for generating random sequences which can be used for many tasks, like generating random data for simulations or games. You can use the list comprehension with randrange() to create a list of random integers.
Generating random sequences of even or odd numbers
To generate a sequence of random even numbers, you can specify a step value in randrange() . The step value defines the difference between each number in the range.
Similarly, to generate a sequence of random odd numbers, you can adjust the starting point and step value.
Shuffling a List Randomly With shuffle()
Shuffling a list means rearranging its elements in a random order. This is particularly useful in situations where you need to randomize the order of elements. Python’s random module provides a function called shuffle() that makes this easy.
This function takes a list and rearranges its elements randomly. It modifies the original list in place and does not return a new list.
A common use case for shuffle() is to shuffle a deck of cards.
When you run this code, your list my_deck will be shuffled into a random order.
Randomly Selecting Multiple Elements Without Repetition With sample()
Sometimes, you need to pick several items from a list without choosing the same item more than once. Python’s random module has a function called sample() that makes this easy. This is useful for things like picking random winners for a contest, selecting random survey participants, or any situation where you need a random sample from a list.
The sample() function lets you select a specified number of elements from a list randomly, ensuring the selected elements are unique and do not repeat.
Here’s the syntax:
- population : The list you want to sample from.
- k : The number of elements you want to select. It must be less than or equal to the length of the list. If k is greater than the number of elements in the list, sample() will raise a ValueError .
In this example, you’ll get a list of 3 unique, randomly selected colors from the colors list.
Selecting Elements Randomly From a List With choice()
Imagine you have a list of items, and you want to pick one item from the list randomly. The choice() function can help you with that. You give it a list, and it gives you back one random element from that list.
This can be handy in many situations, like choosing a random card, selecting a random question from a quiz, or even deciding what to eat for lunch.
This code will select a random fruit from the list.
Random Choices and Weighted Selection Using choices()
The random module offers a helpful function called choices() that lets you make random selections from a list or sequence. This function is quite flexible; you can either make simple random selections or assign weights to the elements, influencing their chances of being picked.
This function is pretty straightforward. You give it a list or sequence of items, and it returns one or more random selections from that list.
- sequence : This is the list or sequence from which you want to make selections.
- weights (optional) : You can assign weights to the elements in the sequence. Higher weights mean higher chances of selection.
- k (optional) : This specifies how many selections you want to make. By default, it’s set to 1.
Here’s one more example that shows you the effect of weights more clearly.
Seed for Reproducibility
Randomness is often crucial in various applications, such as simulations, statistical sampling, and cryptography. However, sometimes you need to reproduce the same sequence of random numbers for debugging, testing, or ensuring consistent results in data analysis. This is where setting a random seed becomes essential. By fixing the seed value, you ensure that the same sequence of random numbers is generated every time you run the code, regardless of the platform or environment.
In Python, you can set a random seed using the seed() function from the random module.
The Normal Distribution
A normal distribution is a way to describe how data points are spread out. It’s often called a bell curve because of its shape: most data points are near the middle (mean), and fewer data points are at the ends. The curve is symmetric around the mean.
Normal distribution is important because many real-world phenomena follow this pattern. Examples include heights, test scores, and measurement errors.
By using the gauss() function of random module, you can generate random numbers that follow a normal distribution.
- mu : The mean of the distribution.
- sigma : The standard deviation, which indicates how spread out the numbers are from the mean.
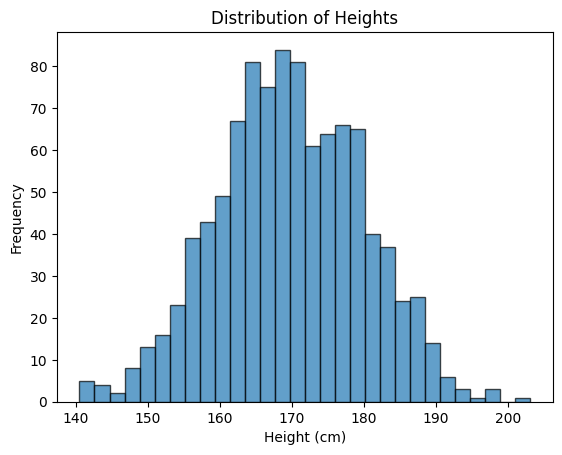
Let’s simulate the heights of people in a group. We’ll use a mean height of 170 cm and a standard deviation of 10 cm. This means most people’s heights are around 170 cm, but some are shorter or taller.
In this example:
We use a list comprehension to generate 1000 random heights using the random.gauss(mean, std_dev) function.
And for creating the plot we import the matplotlib.pyplot . Then we create a histogram of the heights using plt.hist() , which shows the distribution of heights in the form of a bell curve.
The Exponential Distribution
An exponential distribution is a way to describe the time between events that happen at a constant average rate.
Exponential distribution is used in many areas such as:
- Queueing Systems : Understanding how long you will wait in line.
- Reliability : Predicting the lifespan of products like electronics. For example, how long a light bulb lasts before it burns out?
- Biology : Modeling the time between events like radioactive decay.
In Python, you can use the expovariate() function from the random module to generate random numbers that follow an exponential distribution. This helps simulate and understand real-world scenarios where the exponential distribution is applicable.
- lambd : The rate parameter (λ). It represents how often events happen. It’s the inverse of the average waiting time (mean).
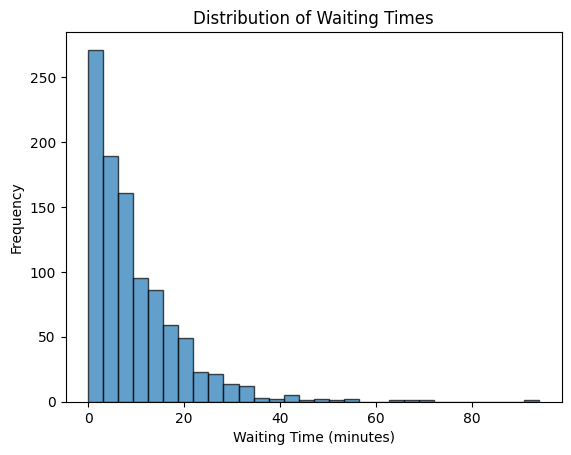
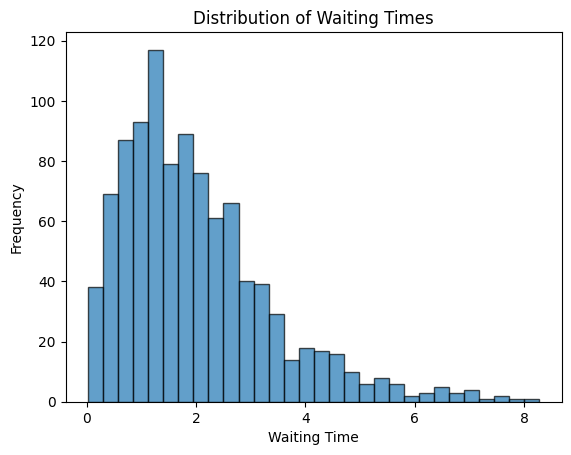
Let’s simulate waiting times for buses that arrive every 10 minutes on average. The rate parameter λ is the inverse of the mean waiting time (1/10 = 0.1).
When you run the code, you will see a histogram that shows the distribution of waiting times:
- Right-Skewed Shape : The distribution has a long tail to the right, meaning there are fewer long waiting times compared to short ones. This creates a curve that slopes downwards to the right.
- Average Waiting Time : The mean of the distribution is 10 minutes, as expected.
The Triangular Distribution
A triangular distribution is a way to describe data that has a clear minimum, maximum, and most likely value. It forms a triangle shape when graphed.
Triangular distribution is helpful because it’s simple and easy to understand. It’s often used in situations where:
- Estimating Task Duration : Predicting how long a task might take when you have some idea but not exact data.
- Risk Analysis : Assessing possible outcomes when you don’t have precise information.
- Supply Chain Management : Estimating delivery times when data is limited.
By using the random.triangular() function, you can generate random numbers that follow a triangular distribution. It needs three values: the minimum value, the maximum value, and the most likely value (mode).
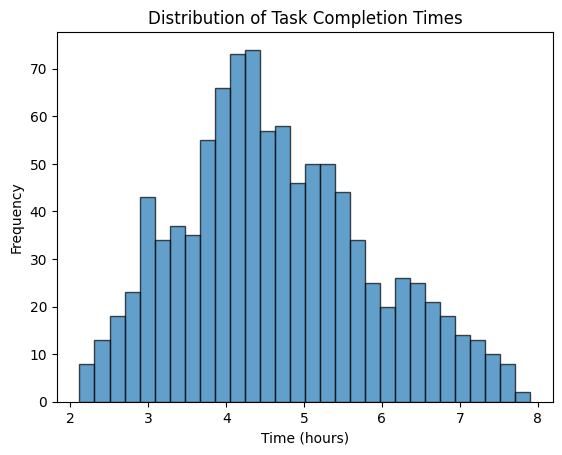
Let’s say you want to estimate the time to complete a task. You think it will take at least 2 hours, at most 8 hours, and most likely 4 hours.
When you run the code, you will see a histogram that shows how the task completion times are spread out:
- Triangular Shape : The histogram forms a triangle, peaking at the most likely time (4 hours) and sloping down towards the minimum (2 hours) and maximum (8 hours) values.
- Mode : The most likely completion time is where the histogram is highest.
The Beta Distribution
Beta distribution is a type of probability distribution that is used to describe the probability of different outcomes for a value that ranges between 0 and 1. It is defined by two numbers, called shape parameters: alpha (α) and beta (β). These parameters determine the shape of the distribution.
The Beta distribution is important because it can model different types of data and scenarios. Here are some key uses:
- Bayesian Statistics : Representing prior knowledge about probabilities.
- Project Management : Estimating the time to complete tasks.
- Proportion Data : Analyzing data that represents percentages or proportions, like the success rate of a process.
The betavariate() function helps you to generate random numbers based on a Beta distribution. You just have to specify the alpha (α) and beta (β) parameters.
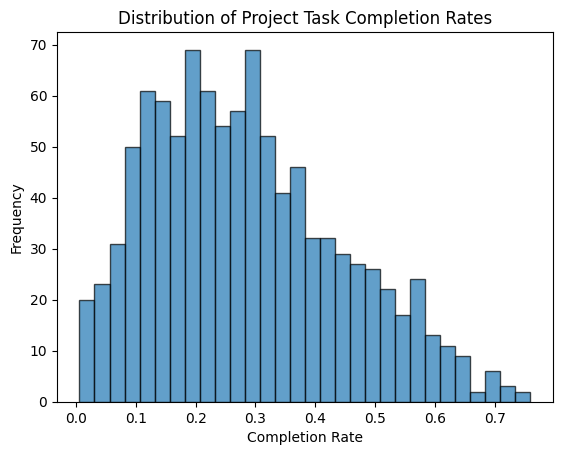
Let’s imagine we want to model the completion rate of a project task. We use α = 2 and β = 5, which means the distribution is skewed towards lower values, suggesting that the task is more likely to be incomplete most of the time.
When you run the code, you will see a histogram that shows the distribution of project task completion rates:
- Skewed Shape : The histogram will likely show more values close to 0 (indicating lower completion rates).
- If α and β are both greater than 1 and equal, the distribution will be bell-shaped.
- If α is less than 1 and β is greater than 1, the distribution will be skewed towards 0.
- If α is greater than 1 and β is less than 1, the distribution will be skewed towards 1.
The Gamma Distribution
Suppose you’re waiting for a bus, and you want to know how long it will take for the next bus to arrive. The Gamma distribution helps answer questions like these by describing the probability of waiting for a certain amount of time. It’s like having a tool to predict how long you might wait for something to happen.
The Gamma distribution is essential because it helps us understand waiting times and lifetimes in many situations. Here are some use cases:
- Reliability : It helps predict how long things like machines or electronics will last before breaking down.
- Service Waiting Times : It helps estimate how long you might wait for the next customer service representative or the next bus.
- Insurance : It’s used to estimate how long it might take for insurance claims to be made.
With the help of gammavariate() function, you can generate random numbers that follow a Gamma distribution.
To use gammavariate() , we need to give it two parameters: the shape of the distribution and how spread out it is. These are called the shape (k) and scale (θ) parameters.
- k : This controls the shape of the distribution. Higher values mean the peak is sharper.
- theta : This controls how spread out the distribution is. Higher values mean the distribution is more spread out.
Let’s say we want to know how long it takes for the next customer to arrive at a service point. We’ll use gammavariate() to simulate this scenario.
When we plot the waiting times, we see a histogram that shows us how likely it is to wait for different amounts of time:
- Shape : The histogram might look like a curve with a tail on one end. This tail tells us how likely it is to wait for longer times.
- Spread : If the curve is wider, it means we’re likely to wait for a more extended range of times.
The Log-Normal Distribution
The Log-Normal distribution helps us understand data that are clustered around a central point but have a wide range of possible values. By using the random.lognormvariate() function, we can generate random numbers that follow this distribution.
Here’s why it’s important:
- Financial Markets : Stock prices and financial data often follow a log-normal distribution.
- Biological Sciences : Characteristics like body size or concentrations of substances in biological systems often have a log-normal distribution.
- Engineering : Quantities such as response times or failure times of components in engineering systems often exhibit a log-normal distribution.
To use lognormvariate() , we need to specify two things: the average value (mean) and how spread out the data is (standard deviation) after taking the natural logarithm of the values.
- mu : This is like the middle or average value around which most of the data is clustered.
- sigma : This tells us how spread out the data is. A larger value means the data is more spread out.
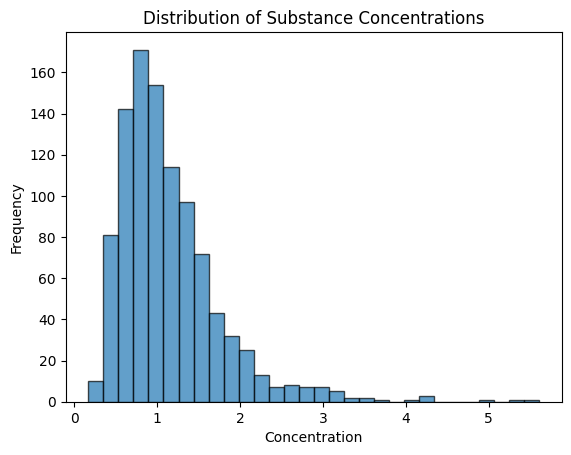
Let’s say we want to simulate the concentrations of a substance in a biological sample. Here’s how we can use lognormvariate() :
When we plot the concentrations, we see a histogram that shows us how likely it is to observe different concentration values:
- Shape : The histogram might resemble a bell-shaped curve, but it’s skewed towards higher values.
- Spread : The spread of the curve tells us how wide the range of concentration values is.
The Von Mises Distribution
Now, imagine you’re tracking the direction in which a compass needle points. Most of the time, it might point north, but there could be some variation due to magnetic interference. The Von Mises distribution helps us understand this kind of data, where values are concentrated around a central direction, but there’s some variation around it.
This distribution is commonly seen in many real-life scenarios such as:
- Navigation : It helps model directions in compasses, gyroscopes, or celestial navigation.
- Earth Sciences : It’s used to analyze the orientation of geological structures like fault lines or mineral deposits.
- Signal Processing : It’s useful for modeling phase angles in oscillatory signals like sound waves or electromagnetic waves.
To generate random numbers that follow a Von Mises distribution, you can use the vonmisesvariate() function.
- mu : This is the mean direction, where most of the data is clustered around.
- kappa : This parameter controls how spread out the data is. A higher value means less spread.
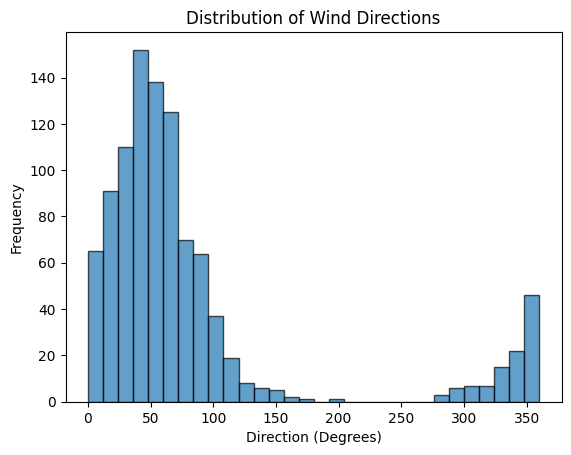
Let’s say we want to simulate wind directions at a particular location.
When we look at the histogram, we can see:
- Shape : It’s like a bell-shaped curve, with most wind directions concentrated around the mean direction.
- Spread : The concentration parameter ( kappa ) controls how spread out the directions are. A higher kappa means less spread.
The Pareto Distribution
Pareto distribution helps us understand situations where there’s inequality or imbalance. Imagine you’re looking at the distribution of wealth in a society. You might notice that a small percentage of people have most of the wealth, while the majority have much less.
Here are some more use cases of this distribution:
- Natural Phenomena : It describes the distribution of things like the sizes of earthquakes, the wealth of species in ecosystems, or the popularity of websites on the internet.
- Business : It’s used in marketing to understand the distribution of customer lifetime value or the distribution of product sales.
In Python, we can generate random numbers that follow a Pareto distribution using the paretovariate() function. For this function, we only need to specify one parameter, which is the shape of the distribution (alpha). Higher values of alpha mean the distribution decreases more slowly.
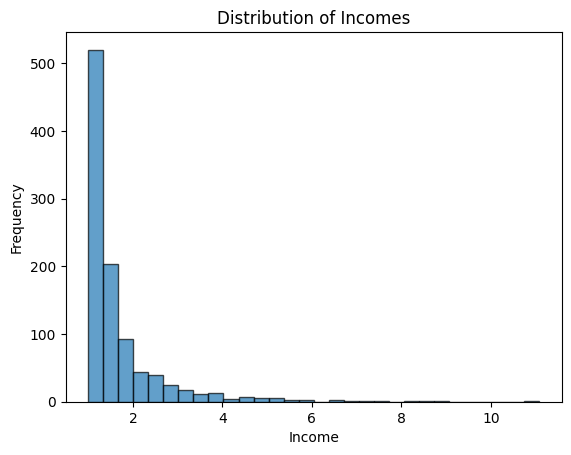
Let’s say we want to simulate the distribution of incomes in a society.
Here, you can see the distribution decreases rapidly at first and then slows down, showing that there are many low incomes and few high-incomes.
The Weibull Distribution
The Weibull distribution is important because it’s used in many fields to model the failure rates of various products and systems. Imagine you’re studying how long it takes for light bulbs to burn out. Some might fail quickly, while others last much longer. The Weibull distribution helps us describe this kind of data, where the probability of an event happening changes over time.
Here’s why it’s significant:
- Reliability Engineering : It helps predict the lifetimes of components and systems.
- Survival Analysis : It’s used in medical research to study the time until death or failure.
- Extreme Value Theory : It’s employed to analyze the distribution of extreme events, like floods or earthquakes.
The random module provides the weibullvariate() function to generate random numbers that follow a Weibull distribution. To use this, we need to specify two parameters:
- alpha : This parameter controls the shape of the distribution. Higher values mean a more sharply peaked curve.
- beta : This parameter controls the scale of the distribution. Higher values mean a wider spread of data.
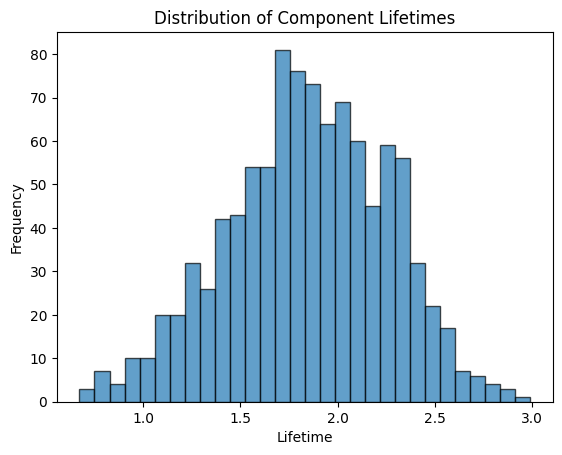
Let’s say we want to simulate the lifetimes of electronic components.
When we look at the histogram, we can see, that it’s like a curve that can be skewed or flattened, depending on the values of alpha and beta . The curve tells us how wide the range of lifetime values is.
Some Real Life Examples
Randomness plays a crucial role in various real-life applications, making systems unpredictable and secure. Two prominent examples are randomizing elements in game development and generating random passwords for security purposes.
Randomizing Elements in Game Development
In game development, randomness is used to create unpredictable and engaging experiences. This includes generating random events, distributing resources, and creating varied gameplay.
Here’s an example of randomly shuffling a list of items in Python for game development:
Random Password Generation
Creating strong, random passwords is crucial for maintaining security. Randomly generated passwords are less predictable and harder to crack.
Here’s how you can generate a random password with a mix of letters, numbers, and symbols:
Similar Posts

Mastering SQLite with Python: A Step-by-Step Tutorial
SQLite is a simple, lightweight database system that stores data in a single file. Unlike other database systems that require setting up a server, SQLite…

Python OS Module Hacks You Probably Haven’t Tried
The Python os module is a handy tool for working with your computer’s operating system directly from your Python code. It offers functions to handle…
ttk Checkbuttons
A ttk checkbutton in Tkinter is a small box that you can tick or untick. It’s useful for letting users pick between two choices, such…

Formatting Strings: The Power of f-strings
String formatting in Python is a handy way to create and customize text, making it clear and easy to read. Whether you’re making user messages,…
ttk Spinbox
In Tkinter, the Spinbox widget provides a convenient way for users to select a value from a predefined range. However, the regular Tkinter Spinbox has…
Tkinter Radiobuttons
Tkinter Radiobuttons are handy little widgets that let users choose only one option from a set of options. Imagine you’re making a quiz app or…
Leave a Reply Cancel reply
Your email address will not be published. Required fields are marked *
Save my name, email, and website in this browser for the next time I comment.
Privacy Overview
| Cookie | Duration | Description |
|---|---|---|
| cookielawinfo-checkbox-analytics | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Analytics". |
| cookielawinfo-checkbox-functional | 11 months | The cookie is set by GDPR cookie consent to record the user consent for the cookies in the category "Functional". |
| cookielawinfo-checkbox-necessary | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookies is used to store the user consent for the cookies in the category "Necessary". |
| cookielawinfo-checkbox-others | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Other. |
| cookielawinfo-checkbox-performance | 11 months | This cookie is set by GDPR Cookie Consent plugin. The cookie is used to store the user consent for the cookies in the category "Performance". |
| viewed_cookie_policy | 11 months | The cookie is set by the GDPR Cookie Consent plugin and is used to store whether or not user has consented to the use of cookies. It does not store any personal data. |
Random Data Generation in Python

- Discussion (2)
Hello and welcome to the Real Python video series, Generating Random Data in Python . In these videos, you’ll explore a variety of ways to create random—or seemingly random—data in your programs and see how Python makes randomness happen.
Why You May Want to Generate Random Data
Why might you want to generate random data in your programs? There are many reasons (games, testing, and so on), but these reasons generally fall under two broad categories:
The random Module
For simulation, it’s best to start with the random module.
Most people getting started in Python are quickly introduced to this module, which is part of the Python Standard Library. This means that it’s built into the language. random provides a number of useful tools for generating what we call pseudo-random data . It’s known as a Pseudo-Random Number Generator , or PRNG .
We’ll come back to that term later, because it’s important, but right now, let’s consider this guess-a-number game.
Importing random gives us a method, randint() , that will generate a random integer within a range we specify. This range includes its bounds. In other words, invoking randint() , as done here, can generate any number between and including 1 and 100 .
In this program, we’re having the computer simulate a person who is thinking of a number in their head and having a second person (in our case, the user) make a series of guesses until they guess correctly. Let’s look at another example.
Here, represented by a list of strings, is a deck of 52 cards. The first part of each string is the card’s value, and the last character is the suit. We’re going to simulate drawing a random card from this deck.
The choice() method in random is a good candidate for this simulation. Its job is to return a random element from a list or sequence. Yes, we could do the same thing by generating a random index value using randint() , but choice() reads a lot better. Just pass the sequence as an argument.
It might seem logical that if we wanted to simulate a full game of cards, say Blackjack or Go Fish, then we could repeatedly invoke random.choice() for the number of cards in our hand.
However, this could generate duplicates. Each call to random.choice() uses the original sequence so there is the potential to pull the same random value more than once. In fact, there is a method in the random module, choices() , that saves us the trouble of repeating random.choice() .
But again, the potential for duplicates is there, and that is why the documentation for choices() uses the words “with replacement.” The simulation, in this case, is like placing each card back in the deck after it’s pulled. What if we wanted to avoid pulling duplicates?
It just so happens that random provides another useful method, sample() , which pulls a number of random values from a sequence without replacement. This means that, unlike choice() and choices() , when a card is pulled using sample() , it is no longer in play. This is more appropriate for the real life example of dealing a hand from a deck of cards, since we won’t get duplicates.
Speaking of cards, we also get a shuffle() method from random. To use shuffle() , we need to pass it a mutable sequence. In other words, you can pass shuffle() a list, but not a tuple or string. This is because shuffle() does not return a new value but rather shuffles what you give it. If you shuffle this deck of cards, then the original sequence is lost.
Sometimes, Python programmers forget this and place a variable assignment in front of random.shuffle() . This variable will hold the value None because shuffle() did the shuffling job on the actual list and had nothing to return.
If we needed to shuffle a sequence but retain the original order, then we’d have to make a copy and shuffle the copy.
What if we wanted to use shuffle() to create a scrambled word puzzle? Strings aren’t mutable. What we could do is create a list, which is mutable and therefore can be scrambled, out of the string. We could then shuffle it and use .join() to piece it back into a string.
In the next video, you’ll learn why pseudo-randomness makes for a great modeling tool and see a few of its operations in data science using the NumPy library. See you there!
00:00 Hello and welcome to Real Python’s video series Generating Random Data in Python. In these videos, you’ll explore a variety of ways to create random or seemingly random data in your programs, and see how Python makes randomness happen.
00:16 So, why might you want to generate random data in your programs? There are many reasons—games, testing, et cetera. But these reasons generally fall under two broad categories, simulation and security.
00:30 For simulation, it’s best to start with the random module. Most people getting started in Python are quickly introduced to this module, which is part of the Python standard library, meaning it’s built into the language.
00:43 random provides a number of useful tools for generating what we call pseudo-random data. It’s known as a pseudo-random number generator , or a PRNG.
00:54 We’ll come back to this term later because it’s important. But right now, as an introduction to the module, let’s consider this very simple guess-a-number game.
01:04 Importing random gives us the method randint() . That will generate a random integer within a range we specify. This range includes its bounds.
01:13 In other words invoking, the randint() method as we’ve done here can generate any number between, and including, 1 and 100 . In this program, we are having the computer simulate a person thinking of a number in their head and having a second person have a series of guesses until they guess correctly.
01:33 Let’s look at another example.
01:37 Here, represented by a simple list of strings, is a deck of 52 cards. The first part of each string is the card’s value and the last character is the suit.
01:48 We’re going to simulate drawing a random card from this deck. random ’s choice() method is a good candidate for this simulation.
01:56 Its job is to return a random element from a list or sequence. Yes, we could do the same thing by generating a random index value using randint() , but the choice() method reads a lot better.
02:08 Simply pass the sequence as an argument. It might seem logical that if we wanted to simulate a full game of cards, say Blackjack or Go Fish, we could repeat random.choice() for the number of cards that we needed in our hand. However, this could generate duplicates.
02:26 Each call to random.choice() uses the same original sequence, so there’s the potential to pull the same random value more than once. In fact, there’s a method in the random module called choices() , with an s , which saves us the trouble of repeating random.choice() . But again, the potential for duplicates is there, and that is why the documentation for the choices() method mentions the words “with replacement.” The simulation, in this case, is like placing each card back in the deck after pulling it. So, what do we do if we want to avoid pulling duplicates?
03:04 It just so happens, random provides another useful method called sample() . sample() pulls a number of random values from a sequence without replacement, meaning unlike choice() and choices() , when a card is pulled using sample() , it is no longer in play.
03:20 This is more appropriate for the real life example of dealing a hand from a deck of cards, since we won’t get duplicates.
03:29 Speaking of cards, we also get a shuffle() method from random . To use shuffle() , we need to pass it a mutable sequence. In other words, you can pass shuffle() a list, but not a tuple or a string.
03:42 The reason why is, shuffle() does not return a new value— it shuffles what you give it. So if you shuffle this deck of cards, the original sequence is lost. Sometimes Python programmers forget this and place a variable assignment in front of random.shuffle() .
03:58 This variable will hold the value None because shuffle() did the shuffling job on the actual list and returned nothing. If we needed to shuffle a sequence and retain the original order, we’d have to make a copy and shuffle the copy.
04:14 What if we wanted to use shuffle() to create a scrambled word puzzle? Strings aren’t mutable, so what do we do? What we could do is create a mutable and therefore scramble-able list out of the string, shuffle that, and use string’s .join() method to piece it back into a string.
04:36 Coming up in the next video, you’ll learn why pseudo-randomness is ideal for modeling and simulation, and you’ll learn about another random module, this one incorporated in the NumPy package. See you there.

Chaitanya on June 29, 2019
i would say its better to give more examples explaining the concept. just a suggestion and this is not an offense.

Jackie Wilson RP Team on June 29, 2019
Thanks for the feedback!
Become a Member to join the conversation.
Have a language expert improve your writing
Run a free plagiarism check in 10 minutes, generate accurate citations for free.
- Knowledge Base
Methodology
- Random Assignment in Experiments | Introduction & Examples
Random Assignment in Experiments | Introduction & Examples
Published on March 8, 2021 by Pritha Bhandari . Revised on June 22, 2023.
In experimental research, random assignment is a way of placing participants from your sample into different treatment groups using randomization.
With simple random assignment, every member of the sample has a known or equal chance of being placed in a control group or an experimental group. Studies that use simple random assignment are also called completely randomized designs .
Random assignment is a key part of experimental design . It helps you ensure that all groups are comparable at the start of a study: any differences between them are due to random factors, not research biases like sampling bias or selection bias .
Table of contents
Why does random assignment matter, random sampling vs random assignment, how do you use random assignment, when is random assignment not used, other interesting articles, frequently asked questions about random assignment.
Random assignment is an important part of control in experimental research, because it helps strengthen the internal validity of an experiment and avoid biases.
In experiments, researchers manipulate an independent variable to assess its effect on a dependent variable, while controlling for other variables. To do so, they often use different levels of an independent variable for different groups of participants.
This is called a between-groups or independent measures design.
You use three groups of participants that are each given a different level of the independent variable:
- a control group that’s given a placebo (no dosage, to control for a placebo effect ),
- an experimental group that’s given a low dosage,
- a second experimental group that’s given a high dosage.
Random assignment to helps you make sure that the treatment groups don’t differ in systematic ways at the start of the experiment, as this can seriously affect (and even invalidate) your work.
If you don’t use random assignment, you may not be able to rule out alternative explanations for your results.
- participants recruited from cafes are placed in the control group ,
- participants recruited from local community centers are placed in the low dosage experimental group,
- participants recruited from gyms are placed in the high dosage group.
With this type of assignment, it’s hard to tell whether the participant characteristics are the same across all groups at the start of the study. Gym-users may tend to engage in more healthy behaviors than people who frequent cafes or community centers, and this would introduce a healthy user bias in your study.
Although random assignment helps even out baseline differences between groups, it doesn’t always make them completely equivalent. There may still be extraneous variables that differ between groups, and there will always be some group differences that arise from chance.
Most of the time, the random variation between groups is low, and, therefore, it’s acceptable for further analysis. This is especially true when you have a large sample. In general, you should always use random assignment in experiments when it is ethically possible and makes sense for your study topic.
Prevent plagiarism. Run a free check.
Random sampling and random assignment are both important concepts in research, but it’s important to understand the difference between them.
Random sampling (also called probability sampling or random selection) is a way of selecting members of a population to be included in your study. In contrast, random assignment is a way of sorting the sample participants into control and experimental groups.
While random sampling is used in many types of studies, random assignment is only used in between-subjects experimental designs.
Some studies use both random sampling and random assignment, while others use only one or the other.

Random sampling enhances the external validity or generalizability of your results, because it helps ensure that your sample is unbiased and representative of the whole population. This allows you to make stronger statistical inferences .
You use a simple random sample to collect data. Because you have access to the whole population (all employees), you can assign all 8000 employees a number and use a random number generator to select 300 employees. These 300 employees are your full sample.
Random assignment enhances the internal validity of the study, because it ensures that there are no systematic differences between the participants in each group. This helps you conclude that the outcomes can be attributed to the independent variable .
- a control group that receives no intervention.
- an experimental group that has a remote team-building intervention every week for a month.
You use random assignment to place participants into the control or experimental group. To do so, you take your list of participants and assign each participant a number. Again, you use a random number generator to place each participant in one of the two groups.
To use simple random assignment, you start by giving every member of the sample a unique number. Then, you can use computer programs or manual methods to randomly assign each participant to a group.
- Random number generator: Use a computer program to generate random numbers from the list for each group.
- Lottery method: Place all numbers individually in a hat or a bucket, and draw numbers at random for each group.
- Flip a coin: When you only have two groups, for each number on the list, flip a coin to decide if they’ll be in the control or the experimental group.
- Use a dice: When you have three groups, for each number on the list, roll a dice to decide which of the groups they will be in. For example, assume that rolling 1 or 2 lands them in a control group; 3 or 4 in an experimental group; and 5 or 6 in a second control or experimental group.
This type of random assignment is the most powerful method of placing participants in conditions, because each individual has an equal chance of being placed in any one of your treatment groups.
Random assignment in block designs
In more complicated experimental designs, random assignment is only used after participants are grouped into blocks based on some characteristic (e.g., test score or demographic variable). These groupings mean that you need a larger sample to achieve high statistical power .
For example, a randomized block design involves placing participants into blocks based on a shared characteristic (e.g., college students versus graduates), and then using random assignment within each block to assign participants to every treatment condition. This helps you assess whether the characteristic affects the outcomes of your treatment.
In an experimental matched design , you use blocking and then match up individual participants from each block based on specific characteristics. Within each matched pair or group, you randomly assign each participant to one of the conditions in the experiment and compare their outcomes.
Sometimes, it’s not relevant or ethical to use simple random assignment, so groups are assigned in a different way.
When comparing different groups
Sometimes, differences between participants are the main focus of a study, for example, when comparing men and women or people with and without health conditions. Participants are not randomly assigned to different groups, but instead assigned based on their characteristics.
In this type of study, the characteristic of interest (e.g., gender) is an independent variable, and the groups differ based on the different levels (e.g., men, women, etc.). All participants are tested the same way, and then their group-level outcomes are compared.
When it’s not ethically permissible
When studying unhealthy or dangerous behaviors, it’s not possible to use random assignment. For example, if you’re studying heavy drinkers and social drinkers, it’s unethical to randomly assign participants to one of the two groups and ask them to drink large amounts of alcohol for your experiment.
When you can’t assign participants to groups, you can also conduct a quasi-experimental study . In a quasi-experiment, you study the outcomes of pre-existing groups who receive treatments that you may not have any control over (e.g., heavy drinkers and social drinkers). These groups aren’t randomly assigned, but may be considered comparable when some other variables (e.g., age or socioeconomic status) are controlled for.
Here's why students love Scribbr's proofreading services
Discover proofreading & editing
If you want to know more about statistics , methodology , or research bias , make sure to check out some of our other articles with explanations and examples.
- Student’s t -distribution
- Normal distribution
- Null and Alternative Hypotheses
- Chi square tests
- Confidence interval
- Quartiles & Quantiles
- Cluster sampling
- Stratified sampling
- Data cleansing
- Reproducibility vs Replicability
- Peer review
- Prospective cohort study
Research bias
- Implicit bias
- Cognitive bias
- Placebo effect
- Hawthorne effect
- Hindsight bias
- Affect heuristic
- Social desirability bias
In experimental research, random assignment is a way of placing participants from your sample into different groups using randomization. With this method, every member of the sample has a known or equal chance of being placed in a control group or an experimental group.
Random selection, or random sampling , is a way of selecting members of a population for your study’s sample.
In contrast, random assignment is a way of sorting the sample into control and experimental groups.
Random sampling enhances the external validity or generalizability of your results, while random assignment improves the internal validity of your study.
Random assignment is used in experiments with a between-groups or independent measures design. In this research design, there’s usually a control group and one or more experimental groups. Random assignment helps ensure that the groups are comparable.
In general, you should always use random assignment in this type of experimental design when it is ethically possible and makes sense for your study topic.
To implement random assignment , assign a unique number to every member of your study’s sample .
Then, you can use a random number generator or a lottery method to randomly assign each number to a control or experimental group. You can also do so manually, by flipping a coin or rolling a dice to randomly assign participants to groups.
Cite this Scribbr article
If you want to cite this source, you can copy and paste the citation or click the “Cite this Scribbr article” button to automatically add the citation to our free Citation Generator.
Bhandari, P. (2023, June 22). Random Assignment in Experiments | Introduction & Examples. Scribbr. Retrieved August 12, 2024, from https://www.scribbr.com/methodology/random-assignment/
Is this article helpful?

Pritha Bhandari
Other students also liked, guide to experimental design | overview, steps, & examples, confounding variables | definition, examples & controls, control groups and treatment groups | uses & examples, get unlimited documents corrected.
✔ Free APA citation check included ✔ Unlimited document corrections ✔ Specialized in correcting academic texts
Stack Exchange Network
Stack Exchange network consists of 183 Q&A communities including Stack Overflow , the largest, most trusted online community for developers to learn, share their knowledge, and build their careers.
Q&A for work
Connect and share knowledge within a single location that is structured and easy to search.
Balanced Random Assignment in Python
It has been a very long time since I've used Python.
What I'm looking for : I would like to create a 6-by-6 random matrix where each component is either 1 or 2, so that there are 18 ones and 18 twos .
Sure, this works. But this seems to me to be extremely inefficient, as the code is literally having to insert new matrix values until the number of ones/twos is 18. How can I make this more efficient?
Just create a list of 18 ones and 18 twos, shuffle it, then reshape to 6x6:
Produces (for example):
Your Answer
Sign up or log in, post as a guest.
Required, but never shown
By clicking “Post Your Answer”, you agree to our terms of service and acknowledge you have read our privacy policy .
Not the answer you're looking for? Browse other questions tagged python python-2.x random matrix numpy or ask your own question .
- Featured on Meta
- Bringing clarity to status tag usage on meta sites
- We've made changes to our Terms of Service & Privacy Policy - July 2024
- Announcing a change to the data-dump process
Hot Network Questions
- Is "Alice loves candies" actually necessary for "Alice loves all sweet foods"?
- Solve an integral analytically
- Has technology regressed in the Alien universe?
- What is the translation of point man in French?
- MOSFETs keep shorting way below rated current
- Where exactly was this picture taken?
- UART pin acting as power pin
- Giant War-Marbles of Doom: What's the Biggest possible Spherical Vehicle we could Build?
- How would a culture living in an extremely vertical environment deal with dead bodies?
- How predictable are the voting records of members of the US legislative branch?
- Do temperature variations make trains on Mars impractical?
- Garage door not closing when sunlight is bright
- How to fix a bottom bracket shell that has been cut from outside?
- How did Jason Bourne know the garbage man isn't CIA?
- General Formula For Hadamard Gate on Superposition State
- Very old fantasy adventure movie where the princess is captured by evil, for evil, and turned evil
- are "lie low" and "keep a low profile" interchangeable?
- In compound nouns is there a way to distinguish which is the subject or the object?
- Short story or novella where a man's wife dies and is brought back to life. The process is called rekindling. Rekindled people are very different
- What if something goes wrong during the seven minutes of terror?
- Does H3PO exist?
- Finding a Linear Algebra reading topic
- Pollard's rho algorithm implementation
- 1 amen for 2 berachot?
Python Tutorial
File handling, python modules, python numpy, python pandas, python matplotlib, python scipy, machine learning, python mysql, python mongodb, python reference, module reference, python how to, python examples, python random module.
Python has a built-in module that you can use to make random numbers.
The random module has a set of methods:
| Method | Description |
|---|---|
| Initialize the random number generator | |
| Returns the current internal state of the random number generator | |
| Restores the internal state of the random number generator | |
| Returns a number representing the random bits | |
| Returns a random number between the given range | |
| Returns a random number between the given range | |
| Returns a random element from the given sequence | |
| Returns a list with a random selection from the given sequence | |
| Takes a sequence and returns the sequence in a random order | |
| Returns a given sample of a sequence | |
| Returns a random float number between 0 and 1 | |
| Returns a random float number between two given parameters | |
| Returns a random float number between two given parameters, you can also set a mode parameter to specify the midpoint between the two other parameters | |
| betavariate() | Returns a random float number between 0 and 1 based on the Beta distribution (used in statistics) |
| expovariate() | Returns a random float number based on the Exponential distribution (used in statistics) |
| gammavariate() | Returns a random float number based on the Gamma distribution (used in statistics) |
| gauss() | Returns a random float number based on the Gaussian distribution (used in probability theories) |
| lognormvariate() | Returns a random float number based on a log-normal distribution (used in probability theories) |
| normalvariate() | Returns a random float number based on the normal distribution (used in probability theories) |
| vonmisesvariate() | Returns a random float number based on the von Mises distribution (used in directional statistics) |
| paretovariate() | Returns a random float number based on the Pareto distribution (used in probability theories) |
| weibullvariate() | Returns a random float number based on the Weibull distribution (used in statistics) |

COLOR PICKER

Contact Sales
If you want to use W3Schools services as an educational institution, team or enterprise, send us an e-mail: [email protected]
Report Error
If you want to report an error, or if you want to make a suggestion, send us an e-mail: [email protected]
Top Tutorials
Top references, top examples, get certified.
Random assignment of participants to groups
I am trying to set up a PsychoPy experiment, first time all by myself. Unfortunately, I am a total beginner when it comes to Python and programming. Good thing is, I already have a working experiment template from a previous pilot study which I now need to change to my needs.
Major thing which needs to be included is: Participants should randomly be assigned to one of four different groups. The experiment consists of two phases: training phase and generalisation phase. Thus, when a participant was assigned to group 1 in the training phase, they have to be assigned to the same group in the generalisation phase.
I’ve created the files I need (excel & folder with pictures) for each group and each phase: so I have for example the files for TrainingG1 (group 1) containing the TrainingG1 excel file and the TrainingG1 zip-folder with the PNG files. Same goes for TrainingG2-4 and GeneralisationG1-4.
I know how to set up the experiment with Training & Generalisation phase for one group, but how can I add a “junction” so to say where the participants are randomly assigned one way (either group1, group2, group3, group4)?
I would really appreciate your help!
Hello Lucia
Put this code at a “Begin Experiment”-tab. It loads four differtent stimulus-files depending on the participant number.
Hey Jens and LuciaIglhaut, two things: Do you know of a way to group participants with non-numeric IDs? I am using Prolific (for the first time) and I believe they don’t use a simple incrementing number as ID.
and for Lucial: once you used the Code of Jens, you need to use the variable (in this case stimfile) in the conditionsfile of a loop. like this: $stimfile it is necissary, that all of the variables in the .xlsx are called the same and is kind of prone to errors.
Regards, Fritz
Hello Becker,
sorry, I have not used Prolific, but you find suggestion on how to use Prolifc and Pavlovia in the forum Search results for 'Prolific' - PsychoPy
Hi @JensBoelte
I’m afraid that this code is incorrect. For four groups all of the statements should have %4 but then check for values 0, 1, 2 and 3.
You can use my VESPR study portal to assign participants to groups or assign numeric participant numbers.
https://moryscarter.com/vespr/portal
Hi @wakecarter
do you mind telling me what is wrong with this code? I checked it and it loads the simulus-files accordingly.
Best wishes Jens
In words, you’ve written: if divisible by 1 else if divisible by 3 else if divisible by 2 else.
Here are how the first 20 participants will be divided:
- 1; 5; 7; 11; 13; 17; 19 = 7 participants
- 2; 10; 14 = 3 participants
- 3; 6; 9; 15; 18 = 5 participants
- 4; 8; 12; 16; 20 = 5 participants
Please correct me if you think I’ve got that wrong. Participant 0 (if you have one) would be allocated to group 4.
My method is to divide by 4 and use the remainder which will equally be 0, 1, 2 or 3.
Hello @wakecarter
that is correct. My code does not result in an even distribution of participants to all groups. I knew that. Your code results in an even distribution of participants to groups which is probably advantageous in most cases.
Thanks for highlighting this.
Related Topics
| Topic | Replies | Views | Activity | |
|---|---|---|---|---|
| Builder | 13 | 1264 | July 19, 2022 | |
| Builder | 31 | 7343 | May 21, 2022 | |
| Builder | 15 | 321 | June 2, 2023 | |
| Builder | 2 | 439 | September 6, 2021 | |
| Builder | 3 | 1140 | June 13, 2017 |
- Python Course
- Python Basics
- Interview Questions
- Python Quiz
- Popular Packages
- Python Projects
- Practice Python
- AI With Python
- Learn Python3
- Python Automation
- Python Web Dev
- DSA with Python
- Python OOPs
- Dictionaries
Python Random – random() Function
There are certain situations that involve games or simulations which work on a non-deterministic approach. In these types of situations, random numbers are extensively used in the following applications:
- Creating pseudo-random numbers on Lottery scratch cards
- reCAPTCHA on login forms uses a random number generator to define different numbers and images
- Picking a number, flipping a coin, and throwing of a dice related games required random numbers
- Shuffling deck of playing cards
In Python , random numbers are not generated implicitly; therefore, it provides a random module in order to generate random numbers explicitly. A random module in Python is used to create random numbers. To generate a random number, we need to import a random module in our program using the command:
Python Random random() Method
The random.random() function generates random floating numbers in the range of 0.1, and 1.0. It takes no parameters and returns values uniformly distributed between 0 and 1. There are various functions associated with the random module are:
- Python random()
- Python randrange()
- Python randint()
- Python seed()
- Python choice() , and many more. We are only demonstrating the use of the random() function in this article.
Python Random random() Syntax
Syntax : random.random() Parameters : This method does not accept any parameter. Returns : This method returns a random floating number between 0 and 1.
Python random.random() Method Example
Random in Python generate different number every time you run this program.
Another way to write the same code.
Create a List of Random Numbers
The random() method in Python from the random module generates a float number between 0 and 1. Here, we are using Python Loop and append random numbers in the Python list .
[0.12144204979175777, 0.27614050014306335, 0.8217122381411321, 0.34259785168486445, 0.6119383347065234, 0.8527573184278889, 0.9741465121560601, 0.21663626227016142, 0.9381166706029976, 0.2785298315133211]
Python Random seed() Method
This function generates a random number based on the seed value. It is used to initialize the base value of the pseudorandom number generator. If the seed value is 10, it will always generate 0.5714025946899135 as the first random number.
Please Login to comment...
Similar reads.
- Python-random
Improve your Coding Skills with Practice
What kind of Experience do you want to share?
Random Team Generator:
How to create randomized groups.
Enter each item on a new line, choose the amount of groups unders settings, and click the button to generate your randomized list. Don't like the first team? Just click again until you do.
Fairly pick teams without bias. No need to draw names out of a hat. No need to do a grade school style draft or put hours of thought into the most balanced teams. The most fair dividing method possible is random.
Mix up your to-do list by generating random groups out of them. For example, enter all your housecleaning activities and split them into seven groups, one for each day or one for each person.
Want something similar?
Use the list randomizer if you don't want separate groups or use the random name picker to pull a single name.
Team Picker Wheel
Randomize people into groups
2. CONTROLLER
Tool settings.
Quick Tool Links: Picker Wheel , Yes No Picker Wheel , Number Picker Wheel , Letter Picker Wheel , Country Picker Wheel , Date Picker Wheel , Image Picker Wheel
Team Picker Wheel - Randomize a List of Names into Group
- What Is Team Picker Wheel?
- How to Use the Random Team Generator?
- Set Team Names
- Preset Group Members
- Tool Customization
- File Storage - How to Save/Open/Delete File?
- Create New Team and Switch Team List
- Modify Title Section
- Full Screen View
- How to Share Team Picker Wheel?
- Specification
- Random Group Generator Use Cases
- We Want to Hear Your Feedback
1. What Is Team Picker Wheel?
Team Picker Wheel is a random team generator developed by Picker Wheel team. It helps you to split a list of names into teams or groups. It is also known as a random group generator or can be used as a random pair generator.
By inserting the list of names into the team generator, the team generator will randomize all the names you entered into equal groups. You can set the number of groups or the number of people/group you want to create, generating equally into random groups.
There is another unique feature from this tool where you can choose to balance the gender of participants equally into groups, in the condition you have set the gender of each participant after filling in the names.
Besides, you don't need to download the groupings result manually from this group randomizer. You can save the group's result as an image or download the group's result in a CSV file for further use.
2. How to Use the Random Team Generator?
Insert participants' names (Two methods available).

Flip a coin to make a decision?
Try FlipSimu Coin Flipper->
- Stack Overflow for Teams Where developers & technologists share private knowledge with coworkers
- Advertising & Talent Reach devs & technologists worldwide about your product, service or employer brand
- OverflowAI GenAI features for Teams
- OverflowAPI Train & fine-tune LLMs
- Labs The future of collective knowledge sharing
- About the company Visit the blog
Collectives™ on Stack Overflow
Find centralized, trusted content and collaborate around the technologies you use most.
Q&A for work
Connect and share knowledge within a single location that is structured and easy to search.
Get early access and see previews of new features.
How to randomly assign variables in python?
Hello I am trying to make a simple multiple choice quiz in pygame. This is the code I wrote and it works as intended.
The problem arises here when I wrote a pygame script to open a window with the question as a header and the three possible answers randomly blitted on three black rectangles. What I want to do is to randomly pick a question from the list, blit it on the screen where it says "Insert question here" and randomly assign answers to the three rectangles. If you were to press the right rectangle then the rectangle changes colour to green, otherwise, it becomes red. But I cannot figure out how to do it.
- So? What is the problem? – Psytho Commented Apr 5, 2018 at 14:02
- @Psytho problem is I can’t figure out how to do it – Moe Commented Apr 5, 2018 at 14:04
- 2 If you provide a minimal reproducible example of your problem people are more likely to help you. Nobody wants to skim over pages of code just to figure out what's actually bothering you... – zwer Commented Apr 5, 2018 at 14:07
- @zwer I shortened it, thank you. – Moe Commented Apr 5, 2018 at 14:12
2 Answers 2
To cycle through the questions I'd define an index variable and assign the current question-choices-answer dict to a variable (I just call it question here).
Increment the index when the user switches to the next question (I'd do that in the event loop).
Pass the question text and choices to font.render (you can render the texts only once when they need to be updated).
When the user clicks on a button, check if the corresponding answer is correct and then change the color of the button/rect.
Pass the current rect color to pygame.draw.rect .
When the user switches to the next question, reset the button colors.
Lists are a very nice method of being able to have random answers.
You would first go into a ranged for loop:
Then you can index the new list when you need to draw
text = myFont.render(myList[0], True, (255, 255, 255))
Later you might want to add some duplicate-detecting code but i hope this helps.
- Ranged for loops are last thing you do in Python, only if there is no other way to express something without unnecessary index values. This looks like a job for random.shuffle() . – BlackJack Commented Apr 5, 2018 at 16:09
Your Answer
Reminder: Answers generated by artificial intelligence tools are not allowed on Stack Overflow. Learn more
Sign up or log in
Post as a guest.
Required, but never shown
By clicking “Post Your Answer”, you agree to our terms of service and acknowledge you have read our privacy policy .
Not the answer you're looking for? Browse other questions tagged python python-3.x pygame or ask your own question .
- Featured on Meta
- We've made changes to our Terms of Service & Privacy Policy - July 2024
- Bringing clarity to status tag usage on meta sites
- Feedback requested: How do you use tag hover descriptions for curating and do...
Hot Network Questions
- Inner tube with sealent inside (unopened), have expiry date?
- How to cite a book if only its chapters have DOIs?
- are "lie low" and "keep a low profile" interchangeable?
- Fourth order BVP partial differential equation
- What is the good errorformat or compiler plugin for pyright?
- Where will the ants position themselves so that they are precisely twice as far from vinegar as they are from peanut butter?
- Fitting the 9th piece into the pizza box
- Just got a new job... huh?
- What's the airplane with the smallest ratio of wingspan to fuselage width?
- when translating a video game's controls into German do I assume a German keyboard?
- They come in twos
- Is my encryption format secure?
- Extrude Individual Faces function is not working
- Did the United States have consent from Texas to cede a piece of land that was part of Texas?
- Is it mandatory in German to use the singular in negative sentences like "none of the books here are on fire?"
- Is "Alice loves candies" actually necessary for "Alice loves all sweet foods"?
- Phrase for giving up?
- what is wrong with my intuition for the sum of the reciprocals of primes?
- Giant War-Marbles of Doom: What's the Biggest possible Spherical Vehicle we could Build?
- Does a Way of the Astral Self Monk HAVE to do force damage with Arms of the Astral Self from 10' away, or can it be bludgeoning?
- Implications of the statement: "Note that it is very difficult to remove Rosetta 2 once it is installed"
- Guitar amplifier placement for live band
- MOSFETs keep shorting way below rated current
- Solve an integral analytically
IMAGES
COMMENTS
I'm trying to make a random group generator splitting a list of students into n nearly-equal partitions (for example, if there are 11 students and three groups, we would want two groups of four and one group of 3) . We need to repeat this process for x number of assignments.
The problem is randomly picking a team for each player. As random.randint produces equally distributed values, each player has the same chance of being assigned to any given team, so you can end up with everyone in the same team.. Instead you should consider iterating over the teams and assigning a random player to it.
Let's say we have 15 students and want 5 random groups. For each index aka number in range(5) — (0,1,2,3,4) — we make a group by selecting students[index::5]. Group 1. students[0::5] We select the 0th student in the randomly shuffled list, then jump by 5 to select the 5th person in the list, and then jump by 5 to take the 10th person in ...
PRNGs in Python The random Module. Probably the most widely known tool for generating random data in Python is its random module, which uses the Mersenne Twister PRNG algorithm as its core generator. Earlier, you touched briefly on random.seed(), and now is a good time to see how it works. First, let's build some random data without seeding.
The default random() returns multiples of 2⁻⁵³ in the range 0.0 ≤ x < 1.0. All such numbers are evenly spaced and are exactly representable as Python floats. However, many other representable floats in that interval are not possible selections. For example, 0.05954861408025609 isn't an integer multiple of 2⁻⁵³.
events: an integer specifying how many group assignments should be created; group size: an integer specifying how big a group can be at maximum. The function should return a list of group assignments. The following shall apply to these: Each student must appear in a group only once per group assignment. A group assignment may not appear more ...
Random Data Series. This Python random data generation series contains the following in-depth tutorial.You can directly read those. Python random intenger number: Generate random numbers using randint() and randrange().; Python random choice: Select a random item from any sequence such as list, tuple, set.; Python random sample: Select multiple random items (k sized random samples) from a list ...
The Python. random. module is a built-in library that allows you to create random numbers and random choices. It's useful for tasks where you need unpredictability, such as in games, simulations, and data sampling. This module generates pseudo-random numbers, which means the numbers are generated using algorithms that mimic randomness but are ...
Step 2: Shuffle the List of Students Randomly, once we have defined the list of students, we will shuffle the list randomly using the random.shuffle () method. This method will shuffle the list of ...
In the next video, you'll learn why pseudo-randomness makes for a great modeling tool and see a few of its operations in data science using the NumPy library. See you there! Hello and welcome to Real Python's video series Generating Random Data in Python. In these videos, you'll explore a variety of ways to create random or seemingly ...
Random sampling (also called probability sampling or random selection) is a way of selecting members of a population to be included in your study. In contrast, random assignment is a way of sorting the sample participants into control and experimental groups. While random sampling is used in many types of studies, random assignment is only used ...
import random. array = numpy.zeros((6, 6)) while (array == 1).sum() != 18 or (array == 2).sum() != 18: for i in range(0, 6): for j in range(0, 6): array[i][j] = random.randint(1, 2) print array. Sure, this works. But this seems to me to be extremely inefficient, as the code is literally having to insert new matrix values until the number of ...
Python has a built-in module that you can use to make random numbers. The random module has a set of methods: Method. Description. seed () Initialize the random number generator. getstate () Returns the current internal state of the random number generator. setstate ()
The choices () method returns multiple random elements from the list with replacement. You can weigh the possibility of each result with the weights parameter or the cum_weights parameter. Syntax : random.choices (sequence, weights=None, cum_weights=None, k=1) Parameters : 1. sequence is a mandatory parameter that can be a list, tuple, or string.
Major thing which needs to be included is: Participants should randomly be assigned to one of four different groups. The experiment consists of two phases: training phase and generalisation phase. Thus, when a participant was assigned to group 1 in the training phase, they have to be assigned to the same group in the generalisation phase.
The random.random () function generates random floating numbers in the range of 0.1, and 1.0. It takes no parameters and returns values uniformly distributed between 0 and 1. There are various functions associated with the random module are: Python random () Python randrange ()
Gale. Jesse. Mike. Group 4. Walter. Jane. Pete. Gustavo. Brock Gale Gustavo Hank Hector Holly Jane Jesse Lydia Marie Mike Pete Saul Skyler Todd Walter.
So you want the two groups to be matched in the sense that for every consecutive pair of skiers in the ranking list (df1) it is to be decided randomly (with equal probabilities) whether the higher ranked skier is allocated to group 1 and the lower ranked one to group 2 or vice versa.. A straightforward if not the most efficient way to achieve this is to use Python's standard random module to ...
Team Picker Wheel is a random team generator developed by Picker Wheel team. It helps you to split a list of names into teams or groups. It is also known as a random group generator or can be used as a random pair generator. By inserting the list of names into the team generator, the team generator will randomize all the names you entered into ...
Lists are a very nice method of being able to have random answers. You would first go into a ranged for loop: for i in range(3): myList.append(answers['Your question'][random.randint(0, 3)])