Chapter 10 Experimental Research
Experimental research, often considered to be the “gold standard” in research designs, is one of the most rigorous of all research designs. In this design, one or more independent variables are manipulated by the researcher (as treatments), subjects are randomly assigned to different treatment levels (random assignment), and the results of the treatments on outcomes (dependent variables) are observed. The unique strength of experimental research is its internal validity (causality) due to its ability to link cause and effect through treatment manipulation, while controlling for the spurious effect of extraneous variable.
Experimental research is best suited for explanatory research (rather than for descriptive or exploratory research), where the goal of the study is to examine cause-effect relationships. It also works well for research that involves a relatively limited and well-defined set of independent variables that can either be manipulated or controlled. Experimental research can be conducted in laboratory or field settings. Laboratory experiments , conducted in laboratory (artificial) settings, tend to be high in internal validity, but this comes at the cost of low external validity (generalizability), because the artificial (laboratory) setting in which the study is conducted may not reflect the real world. Field experiments , conducted in field settings such as in a real organization, and high in both internal and external validity. But such experiments are relatively rare, because of the difficulties associated with manipulating treatments and controlling for extraneous effects in a field setting.
Experimental research can be grouped into two broad categories: true experimental designs and quasi-experimental designs. Both designs require treatment manipulation, but while true experiments also require random assignment, quasi-experiments do not. Sometimes, we also refer to non-experimental research, which is not really a research design, but an all-inclusive term that includes all types of research that do not employ treatment manipulation or random assignment, such as survey research, observational research, and correlational studies.

Basic Concepts
Treatment and control groups. In experimental research, some subjects are administered one or more experimental stimulus called a treatment (the treatment group ) while other subjects are not given such a stimulus (the control group ). The treatment may be considered successful if subjects in the treatment group rate more favorably on outcome variables than control group subjects. Multiple levels of experimental stimulus may be administered, in which case, there may be more than one treatment group. For example, in order to test the effects of a new drug intended to treat a certain medical condition like dementia, if a sample of dementia patients is randomly divided into three groups, with the first group receiving a high dosage of the drug, the second group receiving a low dosage, and the third group receives a placebo such as a sugar pill (control group), then the first two groups are experimental groups and the third group is a control group. After administering the drug for a period of time, if the condition of the experimental group subjects improved significantly more than the control group subjects, we can say that the drug is effective. We can also compare the conditions of the high and low dosage experimental groups to determine if the high dose is more effective than the low dose.
Treatment manipulation. Treatments are the unique feature of experimental research that sets this design apart from all other research methods. Treatment manipulation helps control for the “cause” in cause-effect relationships. Naturally, the validity of experimental research depends on how well the treatment was manipulated. Treatment manipulation must be checked using pretests and pilot tests prior to the experimental study. Any measurements conducted before the treatment is administered are called pretest measures , while those conducted after the treatment are posttest measures .
Random selection and assignment. Random selection is the process of randomly drawing a sample from a population or a sampling frame. This approach is typically employed in survey research, and assures that each unit in the population has a positive chance of being selected into the sample. Random assignment is however a process of randomly assigning subjects to experimental or control groups. This is a standard practice in true experimental research to ensure that treatment groups are similar (equivalent) to each other and to the control group, prior to treatment administration. Random selection is related to sampling, and is therefore, more closely related to the external validity (generalizability) of findings. However, random assignment is related to design, and is therefore most related to internal validity. It is possible to have both random selection and random assignment in well-designed experimental research, but quasi-experimental research involves neither random selection nor random assignment.
Threats to internal validity. Although experimental designs are considered more rigorous than other research methods in terms of the internal validity of their inferences (by virtue of their ability to control causes through treatment manipulation), they are not immune to internal validity threats. Some of these threats to internal validity are described below, within the context of a study of the impact of a special remedial math tutoring program for improving the math abilities of high school students.
- History threat is the possibility that the observed effects (dependent variables) are caused by extraneous or historical events rather than by the experimental treatment. For instance, students’ post-remedial math score improvement may have been caused by their preparation for a math exam at their school, rather than the remedial math program.
- Maturation threat refers to the possibility that observed effects are caused by natural maturation of subjects (e.g., a general improvement in their intellectual ability to understand complex concepts) rather than the experimental treatment.
- Testing threat is a threat in pre-post designs where subjects’ posttest responses are conditioned by their pretest responses. For instance, if students remember their answers from the pretest evaluation, they may tend to repeat them in the posttest exam. Not conducting a pretest can help avoid this threat.
- Instrumentation threat , which also occurs in pre-post designs, refers to the possibility that the difference between pretest and posttest scores is not due to the remedial math program, but due to changes in the administered test, such as the posttest having a higher or lower degree of difficulty than the pretest.
- Mortality threat refers to the possibility that subjects may be dropping out of the study at differential rates between the treatment and control groups due to a systematic reason, such that the dropouts were mostly students who scored low on the pretest. If the low-performing students drop out, the results of the posttest will be artificially inflated by the preponderance of high-performing students.
- Regression threat , also called a regression to the mean, refers to the statistical tendency of a group’s overall performance on a measure during a posttest to regress toward the mean of that measure rather than in the anticipated direction. For instance, if subjects scored high on a pretest, they will have a tendency to score lower on the posttest (closer to the mean) because their high scores (away from the mean) during the pretest was possibly a statistical aberration. This problem tends to be more prevalent in non-random samples and when the two measures are imperfectly correlated.
Two-Group Experimental Designs
The simplest true experimental designs are two group designs involving one treatment group and one control group, and are ideally suited for testing the effects of a single independent variable that can be manipulated as a treatment. The two basic two-group designs are the pretest-posttest control group design and the posttest-only control group design, while variations may include covariance designs. These designs are often depicted using a standardized design notation, where R represents random assignment of subjects to groups, X represents the treatment administered to the treatment group, and O represents pretest or posttest observations of the dependent variable (with different subscripts to distinguish between pretest and posttest observations of treatment and control groups).
Pretest-posttest control group design . In this design, subjects are randomly assigned to treatment and control groups, subjected to an initial (pretest) measurement of the dependent variables of interest, the treatment group is administered a treatment (representing the independent variable of interest), and the dependent variables measured again (posttest). The notation of this design is shown in Figure 10.1.

Figure 10.1. Pretest-posttest control group design
The effect E of the experimental treatment in the pretest posttest design is measured as the difference in the posttest and pretest scores between the treatment and control groups:
E = (O 2 – O 1 ) – (O 4 – O 3 )
Statistical analysis of this design involves a simple analysis of variance (ANOVA) between the treatment and control groups. The pretest posttest design handles several threats to internal validity, such as maturation, testing, and regression, since these threats can be expected to influence both treatment and control groups in a similar (random) manner. The selection threat is controlled via random assignment. However, additional threats to internal validity may exist. For instance, mortality can be a problem if there are differential dropout rates between the two groups, and the pretest measurement may bias the posttest measurement (especially if the pretest introduces unusual topics or content).
Posttest-only control group design . This design is a simpler version of the pretest-posttest design where pretest measurements are omitted. The design notation is shown in Figure 10.2.

Figure 10.2. Posttest only control group design.
The treatment effect is measured simply as the difference in the posttest scores between the two groups:
E = (O 1 – O 2 )
The appropriate statistical analysis of this design is also a two- group analysis of variance (ANOVA). The simplicity of this design makes it more attractive than the pretest-posttest design in terms of internal validity. This design controls for maturation, testing, regression, selection, and pretest-posttest interaction, though the mortality threat may continue to exist.
Covariance designs . Sometimes, measures of dependent variables may be influenced by extraneous variables called covariates . Covariates are those variables that are not of central interest to an experimental study, but should nevertheless be controlled in an experimental design in order to eliminate their potential effect on the dependent variable and therefore allow for a more accurate detection of the effects of the independent variables of interest. The experimental designs discussed earlier did not control for such covariates. A covariance design (also called a concomitant variable design) is a special type of pretest posttest control group design where the pretest measure is essentially a measurement of the covariates of interest rather than that of the dependent variables. The design notation is shown in Figure 10.3, where C represents the covariates:

Figure 10.3. Covariance design
Because the pretest measure is not a measurement of the dependent variable, but rather a covariate, the treatment effect is measured as the difference in the posttest scores between the treatment and control groups as:

Figure 10.4. 2 x 2 factorial design
Factorial designs can also be depicted using a design notation, such as that shown on the right panel of Figure 10.4. R represents random assignment of subjects to treatment groups, X represents the treatment groups themselves (the subscripts of X represents the level of each factor), and O represent observations of the dependent variable. Notice that the 2 x 2 factorial design will have four treatment groups, corresponding to the four combinations of the two levels of each factor. Correspondingly, the 2 x 3 design will have six treatment groups, and the 2 x 2 x 2 design will have eight treatment groups. As a rule of thumb, each cell in a factorial design should have a minimum sample size of 20 (this estimate is derived from Cohen’s power calculations based on medium effect sizes). So a 2 x 2 x 2 factorial design requires a minimum total sample size of 160 subjects, with at least 20 subjects in each cell. As you can see, the cost of data collection can increase substantially with more levels or factors in your factorial design. Sometimes, due to resource constraints, some cells in such factorial designs may not receive any treatment at all, which are called incomplete factorial designs . Such incomplete designs hurt our ability to draw inferences about the incomplete factors.
In a factorial design, a main effect is said to exist if the dependent variable shows a significant difference between multiple levels of one factor, at all levels of other factors. No change in the dependent variable across factor levels is the null case (baseline), from which main effects are evaluated. In the above example, you may see a main effect of instructional type, instructional time, or both on learning outcomes. An interaction effect exists when the effect of differences in one factor depends upon the level of a second factor. In our example, if the effect of instructional type on learning outcomes is greater for 3 hours/week of instructional time than for 1.5 hours/week, then we can say that there is an interaction effect between instructional type and instructional time on learning outcomes. Note that the presence of interaction effects dominate and make main effects irrelevant, and it is not meaningful to interpret main effects if interaction effects are significant.
Hybrid Experimental Designs
Hybrid designs are those that are formed by combining features of more established designs. Three such hybrid designs are randomized bocks design, Solomon four-group design, and switched replications design.
Randomized block design. This is a variation of the posttest-only or pretest-posttest control group design where the subject population can be grouped into relatively homogeneous subgroups (called blocks ) within which the experiment is replicated. For instance, if you want to replicate the same posttest-only design among university students and full -time working professionals (two homogeneous blocks), subjects in both blocks are randomly split between treatment group (receiving the same treatment) or control group (see Figure 10.5). The purpose of this design is to reduce the “noise” or variance in data that may be attributable to differences between the blocks so that the actual effect of interest can be detected more accurately.
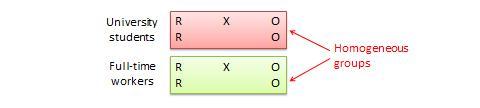
Figure 10.5. Randomized blocks design.
Solomon four-group design . In this design, the sample is divided into two treatment groups and two control groups. One treatment group and one control group receive the pretest, and the other two groups do not. This design represents a combination of posttest-only and pretest-posttest control group design, and is intended to test for the potential biasing effect of pretest measurement on posttest measures that tends to occur in pretest-posttest designs but not in posttest only designs. The design notation is shown in Figure 10.6.

Figure 10.6. Solomon four-group design
Switched replication design . This is a two-group design implemented in two phases with three waves of measurement. The treatment group in the first phase serves as the control group in the second phase, and the control group in the first phase becomes the treatment group in the second phase, as illustrated in Figure 10.7. In other words, the original design is repeated or replicated temporally with treatment/control roles switched between the two groups. By the end of the study, all participants will have received the treatment either during the first or the second phase. This design is most feasible in organizational contexts where organizational programs (e.g., employee training) are implemented in a phased manner or are repeated at regular intervals.
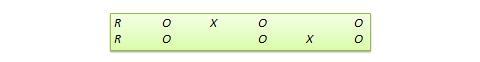
Figure 10.7. Switched replication design.
Quasi-Experimental Designs
Quasi-experimental designs are almost identical to true experimental designs, but lacking one key ingredient: random assignment. For instance, one entire class section or one organization is used as the treatment group, while another section of the same class or a different organization in the same industry is used as the control group. This lack of random assignment potentially results in groups that are non-equivalent, such as one group possessing greater mastery of a certain content than the other group, say by virtue of having a better teacher in a previous semester, which introduces the possibility of selection bias . Quasi-experimental designs are therefore inferior to true experimental designs in interval validity due to the presence of a variety of selection related threats such as selection-maturation threat (the treatment and control groups maturing at different rates), selection-history threat (the treatment and control groups being differentially impact by extraneous or historical events), selection-regression threat (the treatment and control groups regressing toward the mean between pretest and posttest at different rates), selection-instrumentation threat (the treatment and control groups responding differently to the measurement), selection-testing (the treatment and control groups responding differently to the pretest), and selection-mortality (the treatment and control groups demonstrating differential dropout rates). Given these selection threats, it is generally preferable to avoid quasi-experimental designs to the greatest extent possible.
Many true experimental designs can be converted to quasi-experimental designs by omitting random assignment. For instance, the quasi-equivalent version of pretest-posttest control group design is called nonequivalent groups design (NEGD), as shown in Figure 10.8, with random assignment R replaced by non-equivalent (non-random) assignment N . Likewise, the quasi -experimental version of switched replication design is called non-equivalent switched replication design (see Figure 10.9).

Figure 10.8. NEGD design.
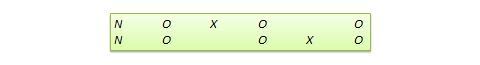
Figure 10.9. Non-equivalent switched replication design.
In addition, there are quite a few unique non -equivalent designs without corresponding true experimental design cousins. Some of the more useful of these designs are discussed next.
Regression-discontinuity (RD) design . This is a non-equivalent pretest-posttest design where subjects are assigned to treatment or control group based on a cutoff score on a preprogram measure. For instance, patients who are severely ill may be assigned to a treatment group to test the efficacy of a new drug or treatment protocol and those who are mildly ill are assigned to the control group. In another example, students who are lagging behind on standardized test scores may be selected for a remedial curriculum program intended to improve their performance, while those who score high on such tests are not selected from the remedial program. The design notation can be represented as follows, where C represents the cutoff score:
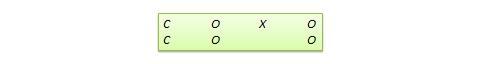
Figure 10.10. RD design.
Because of the use of a cutoff score, it is possible that the observed results may be a function of the cutoff score rather than the treatment, which introduces a new threat to internal validity. However, using the cutoff score also ensures that limited or costly resources are distributed to people who need them the most rather than randomly across a population, while simultaneously allowing a quasi-experimental treatment. The control group scores in the RD design does not serve as a benchmark for comparing treatment group scores, given the systematic non-equivalence between the two groups. Rather, if there is no discontinuity between pretest and posttest scores in the control group, but such a discontinuity persists in the treatment group, then this discontinuity is viewed as evidence of the treatment effect.
Proxy pretest design . This design, shown in Figure 10.11, looks very similar to the standard NEGD (pretest-posttest) design, with one critical difference: the pretest score is collected after the treatment is administered. A typical application of this design is when a researcher is brought in to test the efficacy of a program (e.g., an educational program) after the program has already started and pretest data is not available. Under such circumstances, the best option for the researcher is often to use a different prerecorded measure, such as students’ grade point average before the start of the program, as a proxy for pretest data. A variation of the proxy pretest design is to use subjects’ posttest recollection of pretest data, which may be subject to recall bias, but nevertheless may provide a measure of perceived gain or change in the dependent variable.
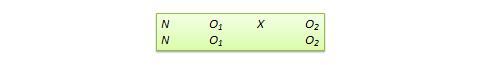
Figure 10.11. Proxy pretest design.
Separate pretest-posttest samples design . This design is useful if it is not possible to collect pretest and posttest data from the same subjects for some reason. As shown in Figure 10.12, there are four groups in this design, but two groups come from a single non-equivalent group, while the other two groups come from a different non-equivalent group. For instance, you want to test customer satisfaction with a new online service that is implemented in one city but not in another. In this case, customers in the first city serve as the treatment group and those in the second city constitute the control group. If it is not possible to obtain pretest and posttest measures from the same customers, you can measure customer satisfaction at one point in time, implement the new service program, and measure customer satisfaction (with a different set of customers) after the program is implemented. Customer satisfaction is also measured in the control group at the same times as in the treatment group, but without the new program implementation. The design is not particularly strong, because you cannot examine the changes in any specific customer’s satisfaction score before and after the implementation, but you can only examine average customer satisfaction scores. Despite the lower internal validity, this design may still be a useful way of collecting quasi-experimental data when pretest and posttest data are not available from the same subjects.

Figure 10.12. Separate pretest-posttest samples design.
Nonequivalent dependent variable (NEDV) design . This is a single-group pre-post quasi-experimental design with two outcome measures, where one measure is theoretically expected to be influenced by the treatment and the other measure is not. For instance, if you are designing a new calculus curriculum for high school students, this curriculum is likely to influence students’ posttest calculus scores but not algebra scores. However, the posttest algebra scores may still vary due to extraneous factors such as history or maturation. Hence, the pre-post algebra scores can be used as a control measure, while that of pre-post calculus can be treated as the treatment measure. The design notation, shown in Figure 10.13, indicates the single group by a single N , followed by pretest O 1 and posttest O 2 for calculus and algebra for the same group of students. This design is weak in internal validity, but its advantage lies in not having to use a separate control group.
An interesting variation of the NEDV design is a pattern matching NEDV design , which employs multiple outcome variables and a theory that explains how much each variable will be affected by the treatment. The researcher can then examine if the theoretical prediction is matched in actual observations. This pattern-matching technique, based on the degree of correspondence between theoretical and observed patterns is a powerful way of alleviating internal validity concerns in the original NEDV design.
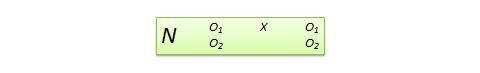
Figure 10.13. NEDV design.
Perils of Experimental Research
Experimental research is one of the most difficult of research designs, and should not be taken lightly. This type of research is often best with a multitude of methodological problems. First, though experimental research requires theories for framing hypotheses for testing, much of current experimental research is atheoretical. Without theories, the hypotheses being tested tend to be ad hoc, possibly illogical, and meaningless. Second, many of the measurement instruments used in experimental research are not tested for reliability and validity, and are incomparable across studies. Consequently, results generated using such instruments are also incomparable. Third, many experimental research use inappropriate research designs, such as irrelevant dependent variables, no interaction effects, no experimental controls, and non-equivalent stimulus across treatment groups. Findings from such studies tend to lack internal validity and are highly suspect. Fourth, the treatments (tasks) used in experimental research may be diverse, incomparable, and inconsistent across studies and sometimes inappropriate for the subject population. For instance, undergraduate student subjects are often asked to pretend that they are marketing managers and asked to perform a complex budget allocation task in which they have no experience or expertise. The use of such inappropriate tasks, introduces new threats to internal validity (i.e., subject’s performance may be an artifact of the content or difficulty of the task setting), generates findings that are non-interpretable and meaningless, and makes integration of findings across studies impossible.
The design of proper experimental treatments is a very important task in experimental design, because the treatment is the raison d’etre of the experimental method, and must never be rushed or neglected. To design an adequate and appropriate task, researchers should use prevalidated tasks if available, conduct treatment manipulation checks to check for the adequacy of such tasks (by debriefing subjects after performing the assigned task), conduct pilot tests (repeatedly, if necessary), and if doubt, using tasks that are simpler and familiar for the respondent sample than tasks that are complex or unfamiliar.
In summary, this chapter introduced key concepts in the experimental design research method and introduced a variety of true experimental and quasi-experimental designs. Although these designs vary widely in internal validity, designs with less internal validity should not be overlooked and may sometimes be useful under specific circumstances and empirical contingencies.
- Social Science Research: Principles, Methods, and Practices. Authored by : Anol Bhattacherjee. Provided by : University of South Florida. Located at : http://scholarcommons.usf.edu/oa_textbooks/3/ . License : CC BY-NC-SA: Attribution-NonCommercial-ShareAlike
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Chapter 10: Single-Subject Research
10.1 Overview of Single-Subject Research 10.2 Single-Subject Research Designs 10.3 The Single-Subject Versus Group “Debate”
Research Methods in Psychology Copyright © 2016 by University of Minnesota is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
- Request new password
- Create a new account
Research Methods and Statistics in Psychology
Student resources, multiple choice questions.
Revise your knowledge with these multiple choice quiz questions.
Chapter 2: Research in Psychology: Objectives and Ideals
Chapter 3: Research Methods
Chapter 4: Experimental Design
Chapter 5: Survey Design
Chapter 6: Descriptive Statistics
Chapter 7: Some Principles of Statistical Inference
Chapter 8: Examining Differences between Means: The t -test
Chapter 9: Examining Relationships between Variables: Correlation
Chapter 10: Comparing Two or More Means by Analysing Variances: ANOVA
Chapter 11: Analysing Other Forms of Data: Chi-square and Distribution-free Tests
Chapter 12: Classical Qualitative Methods
Chapter 13: Contextual Qualitative Methods
Chapter 14: Research Ethics
Chapter 15: Conclusion: Managing Uncertainty in Psychological Research
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
Chapter 10: Qualitative Data Collection & Analysis Methods
Learning Objectives
- Describe the circumstances under which it is suitable to use the interview technique for data collection.
- Explain semi-structured interview
- Identify the characteristics of an open-ended question.
- Describe an interview guide.
- Identify the challenges associated with interviewing.
- Explain what a focus group is and identify the situations where conducting a focus group is valuable.
- Describe when it is appropriate to utilize videography as a data collection method.
- Identify the pros and cons of videography as a data collection method.
- Explain what a code is and describe the coding process.
- Describe the differences between inductive and deductive coding.
- Describe the two types of inductive coding (descriptive and interpretive) and compare those to the two deductive coding (open and focused/axial coding) techniques.
- List the various steps involved in analyzing qualitative data.
- Describe an oral history.
- Identify the strengths and weaknesses of qualitative interviews.
Research Methods for the Social Sciences: An Introduction Copyright © 2020 by Valerie Sheppard is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
2.2 Research Methods
Learning objectives.
By the end of this section, you should be able to:
- Recall the 6 Steps of the Scientific Method
- Differentiate between four kinds of research methods: surveys, field research, experiments, and secondary data analysis.
- Explain the appropriateness of specific research approaches for specific topics.
Sociologists examine the social world, see a problem or interesting pattern, and set out to study it. They use research methods to design a study. Planning the research design is a key step in any sociological study. Sociologists generally choose from widely used methods of social investigation: primary source data collection such as survey, participant observation, ethnography, case study, unobtrusive observations, experiment, and secondary data analysis , or use of existing sources. Every research method comes with plusses and minuses, and the topic of study strongly influences which method or methods are put to use. When you are conducting research think about the best way to gather or obtain knowledge about your topic, think of yourself as an architect. An architect needs a blueprint to build a house, as a sociologist your blueprint is your research design including your data collection method.
When entering a particular social environment, a researcher must be careful. There are times to remain anonymous and times to be overt. There are times to conduct interviews and times to simply observe. Some participants need to be thoroughly informed; others should not know they are being observed. A researcher wouldn’t stroll into a crime-ridden neighborhood at midnight, calling out, “Any gang members around?”
Making sociologists’ presence invisible is not always realistic for other reasons. That option is not available to a researcher studying prison behaviors, early education, or the Ku Klux Klan. Researchers can’t just stroll into prisons, kindergarten classrooms, or Klan meetings and unobtrusively observe behaviors or attract attention. In situations like these, other methods are needed. Researchers choose methods that best suit their study topics, protect research participants or subjects, and that fit with their overall approaches to research.
As a research method, a survey collects data from subjects who respond to a series of questions about behaviors and opinions, often in the form of a questionnaire or an interview. The survey is one of the most widely used scientific research methods. The standard survey format allows individuals a level of anonymity in which they can express personal ideas.
At some point, most people in the United States respond to some type of survey. The 2020 U.S. Census is an excellent example of a large-scale survey intended to gather sociological data. Since 1790, United States has conducted a survey consisting of six questions to received demographical data pertaining to residents. The questions pertain to the demographics of the residents who live in the United States. Currently, the Census is received by residents in the United Stated and five territories and consists of 12 questions.
Not all surveys are considered sociological research, however, and many surveys people commonly encounter focus on identifying marketing needs and strategies rather than testing a hypothesis or contributing to social science knowledge. Questions such as, “How many hot dogs do you eat in a month?” or “Were the staff helpful?” are not usually designed as scientific research. The Nielsen Ratings determine the popularity of television programming through scientific market research. However, polls conducted by television programs such as American Idol or So You Think You Can Dance cannot be generalized, because they are administered to an unrepresentative population, a specific show’s audience. You might receive polls through your cell phones or emails, from grocery stores, restaurants, and retail stores. They often provide you incentives for completing the survey.
Sociologists conduct surveys under controlled conditions for specific purposes. Surveys gather different types of information from people. While surveys are not great at capturing the ways people really behave in social situations, they are a great method for discovering how people feel, think, and act—or at least how they say they feel, think, and act. Surveys can track preferences for presidential candidates or reported individual behaviors (such as sleeping, driving, or texting habits) or information such as employment status, income, and education levels.
A survey targets a specific population , people who are the focus of a study, such as college athletes, international students, or teenagers living with type 1 (juvenile-onset) diabetes. Most researchers choose to survey a small sector of the population, or a sample , a manageable number of subjects who represent a larger population. The success of a study depends on how well a population is represented by the sample. In a random sample , every person in a population has the same chance of being chosen for the study. As a result, a Gallup Poll, if conducted as a nationwide random sampling, should be able to provide an accurate estimate of public opinion whether it contacts 2,000 or 10,000 people.
After selecting subjects, the researcher develops a specific plan to ask questions and record responses. It is important to inform subjects of the nature and purpose of the survey up front. If they agree to participate, researchers thank subjects and offer them a chance to see the results of the study if they are interested. The researcher presents the subjects with an instrument, which is a means of gathering the information.
A common instrument is a questionnaire. Subjects often answer a series of closed-ended questions . The researcher might ask yes-or-no or multiple-choice questions, allowing subjects to choose possible responses to each question. This kind of questionnaire collects quantitative data —data in numerical form that can be counted and statistically analyzed. Just count up the number of “yes” and “no” responses or correct answers, and chart them into percentages.
Questionnaires can also ask more complex questions with more complex answers—beyond “yes,” “no,” or checkbox options. These types of inquiries use open-ended questions that require short essay responses. Participants willing to take the time to write those answers might convey personal religious beliefs, political views, goals, or morals. The answers are subjective and vary from person to person. How do you plan to use your college education?
Some topics that investigate internal thought processes are impossible to observe directly and are difficult to discuss honestly in a public forum. People are more likely to share honest answers if they can respond to questions anonymously. This type of personal explanation is qualitative data —conveyed through words. Qualitative information is harder to organize and tabulate. The researcher will end up with a wide range of responses, some of which may be surprising. The benefit of written opinions, though, is the wealth of in-depth material that they provide.
An interview is a one-on-one conversation between the researcher and the subject, and it is a way of conducting surveys on a topic. However, participants are free to respond as they wish, without being limited by predetermined choices. In the back-and-forth conversation of an interview, a researcher can ask for clarification, spend more time on a subtopic, or ask additional questions. In an interview, a subject will ideally feel free to open up and answer questions that are often complex. There are no right or wrong answers. The subject might not even know how to answer the questions honestly.
Questions such as “How does society’s view of alcohol consumption influence your decision whether or not to take your first sip of alcohol?” or “Did you feel that the divorce of your parents would put a social stigma on your family?” involve so many factors that the answers are difficult to categorize. A researcher needs to avoid steering or prompting the subject to respond in a specific way; otherwise, the results will prove to be unreliable. The researcher will also benefit from gaining a subject’s trust, from empathizing or commiserating with a subject, and from listening without judgment.
Surveys often collect both quantitative and qualitative data. For example, a researcher interviewing people who are incarcerated might receive quantitative data, such as demographics – race, age, sex, that can be analyzed statistically. For example, the researcher might discover that 20 percent of incarcerated people are above the age of 50. The researcher might also collect qualitative data, such as why people take advantage of educational opportunities during their sentence and other explanatory information.
The survey can be carried out online, over the phone, by mail, or face-to-face. When researchers collect data outside a laboratory, library, or workplace setting, they are conducting field research, which is our next topic.
Field Research
The work of sociology rarely happens in limited, confined spaces. Rather, sociologists go out into the world. They meet subjects where they live, work, and play. Field research refers to gathering primary data from a natural environment. To conduct field research, the sociologist must be willing to step into new environments and observe, participate, or experience those worlds. In field work, the sociologists, rather than the subjects, are the ones out of their element.
The researcher interacts with or observes people and gathers data along the way. The key point in field research is that it takes place in the subject’s natural environment, whether it’s a coffee shop or tribal village, a homeless shelter or the DMV, a hospital, airport, mall, or beach resort.
While field research often begins in a specific setting , the study’s purpose is to observe specific behaviors in that setting. Field work is optimal for observing how people think and behave. It seeks to understand why they behave that way. However, researchers may struggle to narrow down cause and effect when there are so many variables floating around in a natural environment. And while field research looks for correlation, its small sample size does not allow for establishing a causal relationship between two variables. Indeed, much of the data gathered in sociology do not identify a cause and effect but a correlation .
Sociology in the Real World
Beyoncé and lady gaga as sociological subjects.
Sociologists have studied Lady Gaga and Beyoncé and their impact on music, movies, social media, fan participation, and social equality. In their studies, researchers have used several research methods including secondary analysis, participant observation, and surveys from concert participants.
In their study, Click, Lee & Holiday (2013) interviewed 45 Lady Gaga fans who utilized social media to communicate with the artist. These fans viewed Lady Gaga as a mirror of themselves and a source of inspiration. Like her, they embrace not being a part of mainstream culture. Many of Lady Gaga’s fans are members of the LGBTQ community. They see the “song “Born This Way” as a rallying cry and answer her calls for “Paws Up” with a physical expression of solidarity—outstretched arms and fingers bent and curled to resemble monster claws.”
Sascha Buchanan (2019) made use of participant observation to study the relationship between two fan groups, that of Beyoncé and that of Rihanna. She observed award shows sponsored by iHeartRadio, MTV EMA, and BET that pit one group against another as they competed for Best Fan Army, Biggest Fans, and FANdemonium. Buchanan argues that the media thus sustains a myth of rivalry between the two most commercially successful Black women vocal artists.
Participant Observation
In 2000, a comic writer named Rodney Rothman wanted an insider’s view of white-collar work. He slipped into the sterile, high-rise offices of a New York “dot com” agency. Every day for two weeks, he pretended to work there. His main purpose was simply to see whether anyone would notice him or challenge his presence. No one did. The receptionist greeted him. The employees smiled and said good morning. Rothman was accepted as part of the team. He even went so far as to claim a desk, inform the receptionist of his whereabouts, and attend a meeting. He published an article about his experience in The New Yorker called “My Fake Job” (2000). Later, he was discredited for allegedly fabricating some details of the story and The New Yorker issued an apology. However, Rothman’s entertaining article still offered fascinating descriptions of the inside workings of a “dot com” company and exemplified the lengths to which a writer, or a sociologist, will go to uncover material.
Rothman had conducted a form of study called participant observation , in which researchers join people and participate in a group’s routine activities for the purpose of observing them within that context. This method lets researchers experience a specific aspect of social life. A researcher might go to great lengths to get a firsthand look into a trend, institution, or behavior. A researcher might work as a waitress in a diner, experience homelessness for several weeks, or ride along with police officers as they patrol their regular beat. Often, these researchers try to blend in seamlessly with the population they study, and they may not disclose their true identity or purpose if they feel it would compromise the results of their research.
At the beginning of a field study, researchers might have a question: “What really goes on in the kitchen of the most popular diner on campus?” or “What is it like to be homeless?” Participant observation is a useful method if the researcher wants to explore a certain environment from the inside.
Field researchers simply want to observe and learn. In such a setting, the researcher will be alert and open minded to whatever happens, recording all observations accurately. Soon, as patterns emerge, questions will become more specific, observations will lead to hypotheses, and hypotheses will guide the researcher in analyzing data and generating results.
In a study of small towns in the United States conducted by sociological researchers John S. Lynd and Helen Merrell Lynd, the team altered their purpose as they gathered data. They initially planned to focus their study on the role of religion in U.S. towns. As they gathered observations, they realized that the effect of industrialization and urbanization was the more relevant topic of this social group. The Lynds did not change their methods, but they revised the purpose of their study.
This shaped the structure of Middletown: A Study in Modern American Culture , their published results (Lynd & Lynd, 1929).
The Lynds were upfront about their mission. The townspeople of Muncie, Indiana, knew why the researchers were in their midst. But some sociologists prefer not to alert people to their presence. The main advantage of covert participant observation is that it allows the researcher access to authentic, natural behaviors of a group’s members. The challenge, however, is gaining access to a setting without disrupting the pattern of others’ behavior. Becoming an inside member of a group, organization, or subculture takes time and effort. Researchers must pretend to be something they are not. The process could involve role playing, making contacts, networking, or applying for a job.
Once inside a group, some researchers spend months or even years pretending to be one of the people they are observing. However, as observers, they cannot get too involved. They must keep their purpose in mind and apply the sociological perspective. That way, they illuminate social patterns that are often unrecognized. Because information gathered during participant observation is mostly qualitative, rather than quantitative, the end results are often descriptive or interpretive. The researcher might present findings in an article or book and describe what he or she witnessed and experienced.
This type of research is what journalist Barbara Ehrenreich conducted for her book Nickel and Dimed . One day over lunch with her editor, Ehrenreich mentioned an idea. How can people exist on minimum-wage work? How do low-income workers get by? she wondered. Someone should do a study . To her surprise, her editor responded, Why don’t you do it?
That’s how Ehrenreich found herself joining the ranks of the working class. For several months, she left her comfortable home and lived and worked among people who lacked, for the most part, higher education and marketable job skills. Undercover, she applied for and worked minimum wage jobs as a waitress, a cleaning woman, a nursing home aide, and a retail chain employee. During her participant observation, she used only her income from those jobs to pay for food, clothing, transportation, and shelter.
She discovered the obvious, that it’s almost impossible to get by on minimum wage work. She also experienced and observed attitudes many middle and upper-class people never think about. She witnessed firsthand the treatment of working class employees. She saw the extreme measures people take to make ends meet and to survive. She described fellow employees who held two or three jobs, worked seven days a week, lived in cars, could not pay to treat chronic health conditions, got randomly fired, submitted to drug tests, and moved in and out of homeless shelters. She brought aspects of that life to light, describing difficult working conditions and the poor treatment that low-wage workers suffer.
The book she wrote upon her return to her real life as a well-paid writer, has been widely read and used in many college classrooms.
Ethnography
Ethnography is the immersion of the researcher in the natural setting of an entire social community to observe and experience their everyday life and culture. The heart of an ethnographic study focuses on how subjects view their own social standing and how they understand themselves in relation to a social group.
An ethnographic study might observe, for example, a small U.S. fishing town, an Inuit community, a village in Thailand, a Buddhist monastery, a private boarding school, or an amusement park. These places all have borders. People live, work, study, or vacation within those borders. People are there for a certain reason and therefore behave in certain ways and respect certain cultural norms. An ethnographer would commit to spending a determined amount of time studying every aspect of the chosen place, taking in as much as possible.
A sociologist studying a tribe in the Amazon might watch the way villagers go about their daily lives and then write a paper about it. To observe a spiritual retreat center, an ethnographer might sign up for a retreat and attend as a guest for an extended stay, observe and record data, and collate the material into results.
Institutional Ethnography
Institutional ethnography is an extension of basic ethnographic research principles that focuses intentionally on everyday concrete social relationships. Developed by Canadian sociologist Dorothy E. Smith (1990), institutional ethnography is often considered a feminist-inspired approach to social analysis and primarily considers women’s experiences within male- dominated societies and power structures. Smith’s work is seen to challenge sociology’s exclusion of women, both academically and in the study of women’s lives (Fenstermaker, n.d.).
Historically, social science research tended to objectify women and ignore their experiences except as viewed from the male perspective. Modern feminists note that describing women, and other marginalized groups, as subordinates helps those in authority maintain their own dominant positions (Social Sciences and Humanities Research Council of Canada n.d.). Smith’s three major works explored what she called “the conceptual practices of power” and are still considered seminal works in feminist theory and ethnography (Fensternmaker n.d.).
Sociological Research
The making of middletown: a study in modern u.s. culture.
In 1924, a young married couple named Robert and Helen Lynd undertook an unprecedented ethnography: to apply sociological methods to the study of one U.S. city in order to discover what “ordinary” people in the United States did and believed. Choosing Muncie, Indiana (population about 30,000) as their subject, they moved to the small town and lived there for eighteen months.
Ethnographers had been examining other cultures for decades—groups considered minorities or outsiders—like gangs, immigrants, and the poor. But no one had studied the so-called average American.
Recording interviews and using surveys to gather data, the Lynds objectively described what they observed. Researching existing sources, they compared Muncie in 1890 to the Muncie they observed in 1924. Most Muncie adults, they found, had grown up on farms but now lived in homes inside the city. As a result, the Lynds focused their study on the impact of industrialization and urbanization.
They observed that Muncie was divided into business and working class groups. They defined business class as dealing with abstract concepts and symbols, while working class people used tools to create concrete objects. The two classes led different lives with different goals and hopes. However, the Lynds observed, mass production offered both classes the same amenities. Like wealthy families, the working class was now able to own radios, cars, washing machines, telephones, vacuum cleaners, and refrigerators. This was an emerging material reality of the 1920s.
As the Lynds worked, they divided their manuscript into six chapters: Getting a Living, Making a Home, Training the Young, Using Leisure, Engaging in Religious Practices, and Engaging in Community Activities.
When the study was completed, the Lynds encountered a big problem. The Rockefeller Foundation, which had commissioned the book, claimed it was useless and refused to publish it. The Lynds asked if they could seek a publisher themselves.
Middletown: A Study in Modern American Culture was not only published in 1929 but also became an instant bestseller, a status unheard of for a sociological study. The book sold out six printings in its first year of publication, and has never gone out of print (Caplow, Hicks, & Wattenberg. 2000).
Nothing like it had ever been done before. Middletown was reviewed on the front page of the New York Times. Readers in the 1920s and 1930s identified with the citizens of Muncie, Indiana, but they were equally fascinated by the sociological methods and the use of scientific data to define ordinary people in the United States. The book was proof that social data was important—and interesting—to the U.S. public.
Sometimes a researcher wants to study one specific person or event. A case study is an in-depth analysis of a single event, situation, or individual. To conduct a case study, a researcher examines existing sources like documents and archival records, conducts interviews, engages in direct observation and even participant observation, if possible.
Researchers might use this method to study a single case of a foster child, drug lord, cancer patient, criminal, or rape victim. However, a major criticism of the case study as a method is that while offering depth on a topic, it does not provide enough evidence to form a generalized conclusion. In other words, it is difficult to make universal claims based on just one person, since one person does not verify a pattern. This is why most sociologists do not use case studies as a primary research method.
However, case studies are useful when the single case is unique. In these instances, a single case study can contribute tremendous insight. For example, a feral child, also called “wild child,” is one who grows up isolated from human beings. Feral children grow up without social contact and language, which are elements crucial to a “civilized” child’s development. These children mimic the behaviors and movements of animals, and often invent their own language. There are only about one hundred cases of “feral children” in the world.
As you may imagine, a feral child is a subject of great interest to researchers. Feral children provide unique information about child development because they have grown up outside of the parameters of “normal” growth and nurturing. And since there are very few feral children, the case study is the most appropriate method for researchers to use in studying the subject.
At age three, a Ukranian girl named Oxana Malaya suffered severe parental neglect. She lived in a shed with dogs, and she ate raw meat and scraps. Five years later, a neighbor called authorities and reported seeing a girl who ran on all fours, barking. Officials brought Oxana into society, where she was cared for and taught some human behaviors, but she never became fully socialized. She has been designated as unable to support herself and now lives in a mental institution (Grice 2011). Case studies like this offer a way for sociologists to collect data that may not be obtained by any other method.
Experiments
You have probably tested some of your own personal social theories. “If I study at night and review in the morning, I’ll improve my retention skills.” Or, “If I stop drinking soda, I’ll feel better.” Cause and effect. If this, then that. When you test the theory, your results either prove or disprove your hypothesis.
One way researchers test social theories is by conducting an experiment , meaning they investigate relationships to test a hypothesis—a scientific approach.
There are two main types of experiments: lab-based experiments and natural or field experiments. In a lab setting, the research can be controlled so that more data can be recorded in a limited amount of time. In a natural or field- based experiment, the time it takes to gather the data cannot be controlled but the information might be considered more accurate since it was collected without interference or intervention by the researcher.
As a research method, either type of sociological experiment is useful for testing if-then statements: if a particular thing happens (cause), then another particular thing will result (effect). To set up a lab-based experiment, sociologists create artificial situations that allow them to manipulate variables.
Classically, the sociologist selects a set of people with similar characteristics, such as age, class, race, or education. Those people are divided into two groups. One is the experimental group and the other is the control group. The experimental group is exposed to the independent variable(s) and the control group is not. To test the benefits of tutoring, for example, the sociologist might provide tutoring to the experimental group of students but not to the control group. Then both groups would be tested for differences in performance to see if tutoring had an effect on the experimental group of students. As you can imagine, in a case like this, the researcher would not want to jeopardize the accomplishments of either group of students, so the setting would be somewhat artificial. The test would not be for a grade reflected on their permanent record of a student, for example.
And if a researcher told the students they would be observed as part of a study on measuring the effectiveness of tutoring, the students might not behave naturally. This is called the Hawthorne effect —which occurs when people change their behavior because they know they are being watched as part of a study. The Hawthorne effect is unavoidable in some research studies because sociologists have to make the purpose of the study known. Subjects must be aware that they are being observed, and a certain amount of artificiality may result (Sonnenfeld 1985).
A real-life example will help illustrate the process. In 1971, Frances Heussenstamm, a sociology professor at California State University at Los Angeles, had a theory about police prejudice. To test her theory, she conducted research. She chose fifteen students from three ethnic backgrounds: Black, White, and Hispanic. She chose students who routinely drove to and from campus along Los Angeles freeway routes, and who had had perfect driving records for longer than a year.
Next, she placed a Black Panther bumper sticker on each car. That sticker, a representation of a social value, was the independent variable. In the 1970s, the Black Panthers were a revolutionary group actively fighting racism. Heussenstamm asked the students to follow their normal driving patterns. She wanted to see whether seeming support for the Black Panthers would change how these good drivers were treated by the police patrolling the highways. The dependent variable would be the number of traffic stops/citations.
The first arrest, for an incorrect lane change, was made two hours after the experiment began. One participant was pulled over three times in three days. He quit the study. After seventeen days, the fifteen drivers had collected a total of thirty-three traffic citations. The research was halted. The funding to pay traffic fines had run out, and so had the enthusiasm of the participants (Heussenstamm, 1971).
Secondary Data Analysis
While sociologists often engage in original research studies, they also contribute knowledge to the discipline through secondary data analysis . Secondary data does not result from firsthand research collected from primary sources, but are the already completed work of other researchers or data collected by an agency or organization. Sociologists might study works written by historians, economists, teachers, or early sociologists. They might search through periodicals, newspapers, or magazines, or organizational data from any period in history.
Using available information not only saves time and money but can also add depth to a study. Sociologists often interpret findings in a new way, a way that was not part of an author’s original purpose or intention. To study how women were encouraged to act and behave in the 1960s, for example, a researcher might watch movies, televisions shows, and situation comedies from that period. Or to research changes in behavior and attitudes due to the emergence of television in the late 1950s and early 1960s, a sociologist would rely on new interpretations of secondary data. Decades from now, researchers will most likely conduct similar studies on the advent of mobile phones, the Internet, or social media.
Social scientists also learn by analyzing the research of a variety of agencies. Governmental departments and global groups, like the U.S. Bureau of Labor Statistics or the World Health Organization (WHO), publish studies with findings that are useful to sociologists. A public statistic like the foreclosure rate might be useful for studying the effects of a recession. A racial demographic profile might be compared with data on education funding to examine the resources accessible by different groups.
One of the advantages of secondary data like old movies or WHO statistics is that it is nonreactive research (or unobtrusive research), meaning that it does not involve direct contact with subjects and will not alter or influence people’s behaviors. Unlike studies requiring direct contact with people, using previously published data does not require entering a population and the investment and risks inherent in that research process.
Using available data does have its challenges. Public records are not always easy to access. A researcher will need to do some legwork to track them down and gain access to records. To guide the search through a vast library of materials and avoid wasting time reading unrelated sources, sociologists employ content analysis , applying a systematic approach to record and value information gleaned from secondary data as they relate to the study at hand.
Also, in some cases, there is no way to verify the accuracy of existing data. It is easy to count how many drunk drivers, for example, are pulled over by the police. But how many are not? While it’s possible to discover the percentage of teenage students who drop out of high school, it might be more challenging to determine the number who return to school or get their GED later.
Another problem arises when data are unavailable in the exact form needed or do not survey the topic from the precise angle the researcher seeks. For example, the average salaries paid to professors at a public school is public record. But these figures do not necessarily reveal how long it took each professor to reach the salary range, what their educational backgrounds are, or how long they’ve been teaching.
When conducting content analysis, it is important to consider the date of publication of an existing source and to take into account attitudes and common cultural ideals that may have influenced the research. For example, when Robert S. Lynd and Helen Merrell Lynd gathered research in the 1920s, attitudes and cultural norms were vastly different then than they are now. Beliefs about gender roles, race, education, and work have changed significantly since then. At the time, the study’s purpose was to reveal insights about small U.S. communities. Today, it is an illustration of 1920s attitudes and values.
As an Amazon Associate we earn from qualifying purchases.
This book may not be used in the training of large language models or otherwise be ingested into large language models or generative AI offerings without OpenStax's permission.
Want to cite, share, or modify this book? This book uses the Creative Commons Attribution License and you must attribute OpenStax.
Access for free at https://openstax.org/books/introduction-sociology-3e/pages/1-introduction
- Authors: Tonja R. Conerly, Kathleen Holmes, Asha Lal Tamang
- Publisher/website: OpenStax
- Book title: Introduction to Sociology 3e
- Publication date: Jun 3, 2021
- Location: Houston, Texas
- Book URL: https://openstax.org/books/introduction-sociology-3e/pages/1-introduction
- Section URL: https://openstax.org/books/introduction-sociology-3e/pages/2-2-research-methods
© Jan 18, 2024 OpenStax. Textbook content produced by OpenStax is licensed under a Creative Commons Attribution License . The OpenStax name, OpenStax logo, OpenStax book covers, OpenStax CNX name, and OpenStax CNX logo are not subject to the Creative Commons license and may not be reproduced without the prior and express written consent of Rice University.
Learning Goals
- Learn the basics of correlational research.
Research Methods in Psychology
Correlational research.
What Is Correlational Research?
Correlational research is a type of non-experimental research in which the researcher measures two variables and assesses the statistical relationship (i.e., the correlation) between them with little or no effort to control extraneous variables. There are essentially two reasons that researchers interested in statistical relationships between variables would choose to conduct a correlational study rather than an experiment. The first is that they do not believe that the statistical relationship is a causal one, meaning that one variable is responsible for creating a change in a second variable. For example, a researcher might evaluate the validity of a brief extraversion test by administering it to a large group of participants along with a longer extraversion test that has already been shown to be valid. This researcher might then check to see whether participants’ scores on the brief test are strongly correlated with their scores on the longer one. Neither test score is thought to cause the other, so there is no independent variable to manipulate. In fact, the terms independent variable and dependent variable do not apply to this kind of research.
The other reason that researchers would choose to use a correlational study rather than an experiment is that the statistical relationship of interest is thought to be causal, but the researcher cannot manipulate the independent variable because it is impossible, impractical, or unethical. For example, Allen Kanner and his colleagues thought that the number of “daily hassles” (e.g., rude salespeople, heavy traffic) that people experience affects the number of physical and psychological symptoms they have (Kanner, Coyne, Schaefer, & Lazarus, 1981). But because they could not manipulate the number of daily hassles their participants experienced, they had to settle for measuring the number of daily hassles—along with the number of symptoms—using self-report questionnaires. Although the strong positive relationship they found between these two variables is consistent with their idea that hassles cause symptoms, it is also consistent with the idea that symptoms cause hassles or that some third variable (e.g., neuroticism) causes both.
A common misconception among beginning researchers is that correlational research must involve two quantitative variables, such as scores on two extraversion tests or the number of hassles and number of symptoms people have experienced. However, the defining feature of correlational research is that the two variables are measured—neither one is manipulated—and this is true regardless of whether the variables are quantitative or categorical. Imagine, for example, that a researcher administers the Rosenberg Self-Esteem Scale to 50 American college students and 50 Japanese college students. Although this “feels” like a between-subjects experiment, it is a correlational study because the researcher did not manipulate the students’ nationalities. The same is true of the study by Cacioppo and Petty comparing college faculty and factory workers in terms of their need for cognition. It is a correlational study because the researchers did not manipulate the participants’ occupations.
Consider a hypothetical study on the relationship between whether people make a daily list of things to do (a “to-do list”) and stress. Notice that it is unclear whether this is an experiment or a correlational study because it is unclear whether the independent variable was manipulated. If the researcher randomly assigned some participants to make daily to-do lists and others not to, then it is an experiment. If the researcher simply asked participants whether they made daily to-do lists, then it is a correlational study. The distinction is important because if the study was an experiment, then it could be concluded that making the daily to-do lists reduced participants’ stress. But if it was a correlational study, it could only be concluded that these variables are statistically related. Perhaps being stressed has a negative effect on people’s ability to plan ahead (the directionality problem). Or perhaps people who are more conscientious are more likely to make to-do lists and less likely to be stressed (the third-variable problem). The crucial point is that what defines a study as experimental or correlational is not the variables being studied, nor whether the variables are quantitative or categorical, nor the type of graph or statistics used to analyze the data. It is how the study is conducted.
8.1 Data Collection in Correlational Research
Again, the defining feature of correlational research is that neither variable is manipulated. It does not matter how or where the variables are measured. A researcher could have participants come to a laboratory to complete a computerized backward digit span task and a computerized risky decision-making task and then assess the relationship between participants’ scores on the two tasks. Or a researcher could go to a shopping mall to ask people about their attitudes toward the environment and their shopping habits and then assess the relationship between these two variables. Both of these studies would be correlational because no independent variable is manipulated. However, because some approaches to data collection are strongly associated with correlational research, it makes sense to discuss them here. The two we will focus on are naturalistic observation and archival data. A third, survey research, is discussed in its own chapter.
Naturalistic Observation
Naturalistic observation is an approach to data collection that involves observing people’s behavior in the environment in which it typically occurs. Thus naturalistic observation is a type of field research (as opposed to a type of laboratory research). It could involve observing shoppers in a grocery store, children on a school playground, or psychiatric inpatients in their wards. Researchers engaged in naturalistic observation usually make their observations as unobtrusively as possible so that participants are often not aware that they are being studied. Ethically, this is considered to be acceptable if the participants remain anonymous and the behavior occurs in a public setting where people would not normally have an expectation of privacy. Grocery shoppers putting items into their shopping carts, for example, are engaged in public behavior that is easily observable by store employees and other shoppers. For this reason, most researchers would consider it ethically acceptable to observe them for a study. On the other hand, one of the arguments against the ethicality of the naturalistic observation of “bathroom behavior” discussed earlier in the book is that people have a reasonable expectation of privacy even in a public restroom and that this expectation was violated.
Researchers Robert Levine and Ara Norenzayan used naturalistic observation to study differences in the “pace of life” across countries (Levine & Norenzayan, 1999). One of their measures involved observing pedestrians in a large city to see how long it took them to walk 60 feet. They found that people in some countries walked reliably faster than people in other countries. For example, people in the United States and Japan covered 60 feet in about 12 seconds on average, while people in Brazil and Romania took close to 17 seconds.
Because naturalistic observation takes place in the complex and even chaotic “real world,” there are two closely related issues that researchers must deal with before collecting data. The first is sampling. When, where, and under what conditions will the observations be made, and who exactly will be observed? Levine and Norenzayan described their sampling process as follows:
Male and female walking speed over a distance of 60 feet was measured in at least two locations in main downtown areas in each city. Measurements were taken during main business hours on clear summer days. All locations were flat, unobstructed, had broad sidewalks, and were sufficiently uncrowded to allow pedestrians to move at potentially maximum speeds. To control for the effects of socializing, only pedestrians walking alone were used. Children, individuals with obvious physical handicaps, and window-shoppers were not timed. Thirty-five men and 35 women were timed in most cities. (p. 186)
Precise specification of the sampling process in this way makes data collection manageable for the observers, and it also provides some control over important extraneous variables. For example, by making their observations on clear summer days in all countries, Levine and Norenzayan controlled for effects of the weather on people’s walking speeds.
The second issue is measurement. What specific behaviors will be observed? In Levine and Norenzayan’s study, measurement was relatively straightforward. They simply measured out a 60-foot distance along a city sidewalk and then used a stopwatch to time participants as they walked over that distance. Often, however, the behaviors of interest are not so obvious or objective. For example, researchers Robert Kraut and Robert Johnston wanted to study bowlers’ reactions to their shots, both when they were facing the pins and then when they turned toward their companions (Kraut & Johnston, 1979). But what “reactions” should they observe? Based on previous research and their own pilot testing, Kraut and Johnston created a list of reactions that included “closed smile,” “open smile,” “laugh,” “neutral face,” “look down,” “look away,” and “face cover” (covering one’s face with one’s hands). The observers committed this list to memory and then practiced by coding the reactions of bowlers who had been videotaped. During the actual study, the observers spoke into an audio recorder, describing the reactions they observed. Among the most interesting results of this study was that bowlers rarely smiled while they still faced the pins. They were much more likely to smile after they turned toward their companions, suggesting that smiling is not purely an expression of happiness but also a form of social communication.
Naturalistic observation has revealed that bowlers tend to smile when they turn away from the pins and toward their companions, suggesting that smiling is not purely an expression of happiness but also a form of social communication.
When the observations require a judgment on the part of the observers—as in Kraut and Johnston’s study—this process is often described as coding. Coding generally requires clearly defining a set of target behaviors. The observers then categorize participants individually in terms of which behavior they have engaged in and the number of times they engaged in each behavior. The observers might even record the duration of each behavior. The target behaviors must be defined in such a way that different observers code them in the same way. This is the issue of inter-rater reliability. Researchers are expected to demonstrate the inter-rater reliability of their coding procedure by having multiple raters code the same behaviors independently and then showing that the different observers are in close agreement. Kraut and Johnston, for example, video recorded a subset of their participants’ reactions and had two observers independently code them. The two observers showed that they agreed on the reactions that were exhibited 97% of the time, indicating good inter-rater reliability.
Archival Data
Another approach to correlational research is the use of archival data, which are data that have already been collected for some other purpose. An example is a study by Brett Pelham and his colleagues on “implicit egotism”—the tendency for people to prefer people, places, and things that are similar to themselves (Pelham, Carvallo, & Jones, 2005). In one study, they examined Social Security records to show that women with the names Virginia, Georgia, Louise, and Florence were especially likely to have moved to the states of Virginia, Georgia, Louisiana, and Florida, respectively.
As with naturalistic observation, measurement can be more or less straightforward when working with archival data. For example, counting the number of people named Virginia who live in various states based on Social Security records is relatively straightforward. But consider a study by Christopher Peterson and his colleagues on the relationship between optimism and health using data that had been collected many years before for a study on adult development (Peterson, Seligman, & Vaillant, 1988). In the 1940s, healthy male college students had completed an open-ended questionnaire about difficult wartime experiences. In the late 1980s, Peterson and his colleagues reviewed the men’s questionnaire responses to obtain a measure of explanatory style—their habitual ways of explaining bad events that happen to them. More pessimistic people tend to blame themselves and expect long-term negative consequences that affect many aspects of their lives, while more optimistic people tend to blame outside forces and expect limited negative consequences. To obtain a measure of explanatory style for each participant, the researchers used a procedure in which all negative events mentioned in the questionnaire responses, and any causal explanations for them, were identified and written on index cards. These were given to a separate group of raters who rated each explanation in terms of three separate dimensions of optimism-pessimism. These ratings were then averaged to produce an explanatory style score for each participant. The researchers then assessed the statistical relationship between the men’s explanatory style as college students and archival measures of their health at approximately 60 years of age. The primary result was that the more optimistic the men were as college students, the healthier they were as older men. Pearson’s r was +.25.
This is an example of content analysis—a family of systematic approaches to measurement using complex archival data. Just as naturalistic observation requires specifying the behaviors of interest and then noting them as they occur, content analysis requires specifying keywords, phrases, or ideas and then finding all occurrences of them in the data. These occurrences can then be counted, timed (e.g., the amount of time devoted to entertainment topics on the nightly news show), or analyzed in a variety of other ways.
Key Takeaways
· Correlational research involves measuring two variables and assessing the relationship between them, with no manipulation of an independent variable.
· Correlational research is not defined by where or how the data are collected. However, some approaches to data collection are strongly associated with correlational research. These include naturalistic observation (in which researchers observe people’s behavior in the context in which it normally occurs) and the use of archival data that were already collected for some other purpose.
8.2 Assessing Relationships among Multiple Variables
Most complex correlational research involves measuring several variables—often both categorical and quantitative—and then assessing the statistical relationships among them. For example, researchers Nathan Radcliffe and William Klein studied a sample of middle-aged adults to see how their level of optimism (measured by using a short questionnaire called the Life Orientation Test) relates to several other variables related to having a heart attack (Radcliffe & Klein, 2002). These included their health, their knowledge of heart attack risk factors, and their beliefs about their own risk of having a heart attack. They found that more optimistic participants were healthier (e.g., they exercised more and had lower blood pressure), knew about heart attack risk factors, and correctly believed their own risk to be lower than that of their peers.
This approach is often used to assess the validity of new psychological measures. For example, when John Cacioppo and Richard Petty created their Need for Cognition Scale—a measure of the extent to which people like to think and value thinking—they used it to measure the need for cognition for a large sample of college students, along with three other variables: intelligence, socially desirable responding (the tendency to give what one thinks is the “appropriate” response), and dogmatism (Caccioppo & Petty, 1982). The results of this study are summarized in Table 8.2 “Correlation Matrix Showing Correlations Among the Need for Cognition and Three Other Variables Based on Research by Cacioppo and Petty”, which is a correlation matrix showing the correlation (Pearson’s r) between every possible pair of variables in the study. For example, the correlation between the need for cognition and intelligence was +.39, the correlation between intelligence and socially desirable responding was −.02, and so on. (Only half the matrix is filled in because the other half would contain exactly the same information. Also, because the correlation between a variable and itself is always +1.00, these values are replaced with dashes throughout the matrix.) In this case, the overall pattern of correlations was consistent with the researchers’ ideas about how scores on the need for cognition should be related to these other constructs.
Table 8.2 Correlation Matrix Showing Correlations Among the Need for Cognition and Three Other Variables Based on Research by Cacioppo and Petty
When researchers study relationships among a large number of conceptually similar variables, they often use a complex statistical technique called factor analysis. In essence, factor analysis organizes the variables into a smaller number of clusters, such that they are strongly correlated within each cluster but weakly correlated between clusters. Each cluster is then interpreted as multiple measures of the same underlying construct. These underlying constructs are also called “factors.” For example, when people perform a wide variety of mental tasks, factor analysis typically organizes them into two main factors—one that researchers interpret as mathematical intelligence (arithmetic, quantitative estimation, spatial reasoning, and so on) and another that they interpret as verbal intelligence (grammar, reading comprehension, vocabulary, and so on). The Big Five personality factors have been identified through factor analyses of people’s scores on a large number of more specific traits. For example, measures of warmth, gregariousness, activity level, and positive emotions tend to be highly correlated with each other and are interpreted as representing the construct of extroversion. As a final example, researchers Peter Rentfrow and Samuel Gosling asked more than 1,700 college students to rate how much they liked 14 different popular genres of music (Rentfrow & Gosling, 2008). They then submitted these 14 variables to a factor analysis, which identified four distinct factors. The researchers called them Reflective and Complex (blues, jazz, classical, and folk), Intense and Rebellious (rock, alternative, and heavy metal), Upbeat and Conventional (country, soundtrack, religious, pop), and Energetic and Rhythmic (rap/hip-hop, soul/funk, and electronica).
Two additional points about factor analysis are worth making here. One is that factors are not categories. Factor analysis does not tell us that people are either extroverted or conscientious or that they like either “reflective and complex” music or “intense and rebellious” music. Instead, factors are constructs that operate independently of each other. So people who are high in extroversion might be high or low in conscientiousness, and people who like reflective and complex music might or might not also like intense and rebellious music. The second point is that factor analysis reveals only the underlying structure of the variables. It is up to researchers to interpret and label the factors and to explain the origin of that particular factor structure. For example, one reason that extroversion and the other Big Five operate as separate factors is that they appear to be controlled by different genes (Plomin, DeFries, McClean, & McGuffin, 2008).
8.3 Exploring Causal Relationships
Another important use of complex correlational research is to explore possible causal relationships among variables. This might seem surprising given that “correlation does not imply causation.” It is true that correlational research cannot unambiguously establish that one variable causes another. Complex correlational research, however, can often be used to rule out other plausible interpretations.
The primary way of doing this is through the statistical control of potential third variables. Instead of controlling these variables by random assignment or by holding them constant as in an experiment, the researcher measures them and includes them in the statistical analysis. Consider some research by Paul Piff and his colleagues, who hypothesized that being lower in socioeconomic status (SES) causes people to be more generous (Piff, Kraus, Côté, Hayden Cheng, & Keltner, 2011). They measured their participants’ SES and had them play the “dictator game.” They told participants that each would be paired with another participant in a different room. (In reality, there was no other participant.) Then they gave each participant 10 points (which could later be converted to money) to split with the “partner” in whatever way he or she decided. Because the participants were the “dictators,” they could even keep all 10 points for themselves if they wanted to.
As these researchers expected, participants who were lower in SES tended to give away more of their points than participants who were higher in SES. This is consistent with the idea that being lower in SES causes people to be more generous. But there are also plausible third variables that could explain this relationship. It could be, for example, that people who are lower in SES tend to be more religious and that it is their greater religiosity that causes them to be more generous. Or it could be that people who are lower in SES tend to come from ethnic groups that emphasize generosity more than other ethnic groups. The researchers dealt with these potential third variables, however, by measuring them and including them in their statistical analyses. They found that neither religiosity nor ethnicity was correlated with generosity and were therefore able to rule them out as third variables. This does not prove that SES causes greater generosity because there could still be other third variables that the researchers did not measure. But by ruling out some of the most plausible third variables, the researchers made a stronger case for SES as the cause of the greater generosity.
Many studies of this type use a statistical technique called multiple regression. This involves measuring several independent variables (X1, X2, X3,…Xi), all of which are possible causes of a single dependent variable (Y). The result of a multiple regression analysis is an equation that expresses the dependent variable as an additive combination of the independent variables. This regression equation has the following general form:
b1X1+ b2X2+ b3X3+ … + biXi= Y.
The quantities b1, b2, and so on are regression weights that indicate how large a contribution an independent variable makes, on average, to the dependent variable. Specifically, they indicate how much the dependent variable changes for each one-unit change in the independent variable.
The advantage of multiple regression is that it can show whether an independent variable makes a contribution to a dependent variable over and above the contributions made by other independent variables. As a hypothetical example, imagine that a researcher wants to know how the independent variables of income and health relate to the dependent variable of happiness. This is tricky because income and health are themselves related to each other. Thus if people with greater incomes tend to be happier, then perhaps this is only because they tend to be healthier. Likewise, if people who are healthier tend to be happier, perhaps this is only because they tend to make more money. But a multiple regression analysis including both income and happiness as independent variables would show whether each one makes a contribution to happiness when the other is taken into account. Research like this, by the way, has shown both income and health make extremely small contributions to happiness except in the case of severe poverty or illness (Diener, 2000).
The examples discussed in this section only scratch the surface of how researchers use complex correlational research to explore possible causal relationships among variables. It is important to keep in mind, however, that purely correlational approaches cannot unambiguously establish that one variable causes another. The best they can do is show patterns of relationships that are consistent with some causal interpretations and inconsistent with others.
· Researchers often use complex correlational research to explore relationships among several variables in the same study.
· Complex correlational research can be used to explore possible causal relationships among variables using techniques such as multiple regression. Such designs can show patterns of relationships that are consistent with some causal interpretations and inconsistent with others, but they cannot unambiguously establish that one variable causes another.
References from Chapter 8
Cacioppo, J. T., & Petty, R. E. (1982). The need for cognition. Journal of Personality and Social Psychology, 42, 116–131.
Diener, E. (2000). Subjective well-being: The science of happiness, and a proposal for a national index. American Psychologist, 55, 34–43.
Kanner, A. D., Coyne, J. C., Schaefer, C., & Lazarus, R. S. (1981). Comparison of two modes of stress measurement: Daily hassles and uplifts versus major life events. Journal of Behavioral Medicine, 4, 1–39.
Kraut, R. E., & Johnston, R. E. (1979). Social and emotional messages of smiling: An ethological approach. Journal of Personality and Social Psychology, 37, 1539–1553.
Levine, R. V., & Norenzayan, A. (1999). The pace of life in 31 countries. Journal of Cross-Cultural Psychology, 30, 178–205.
MacDonald, T. K., & Martineau, A. M. (2002). Self-esteem, mood, and intentions to use condoms: When does low self-esteem lead to risky health behaviors? Journal of Experimental Social Psychology, 38, 299–306.
Pelham, B. W., Carvallo, M., & Jones, J. T. (2005). Implicit egotism. Current Directions in Psychological Science, 14, 106–110.
Peterson, C., Seligman, M. E. P., & Vaillant, G. E. (1988). Pessimistic explanatory style is a risk factor for physical illness: A thirty-five year longitudinal study. Journal of Personality and Social Psychology, 55, 23–27.
Piff, P. K., Kraus, M. W., Côté, S., Hayden Cheng, B., & Keltner, D. (2011). Having less, giving more: The influence of social class on prosocial behavior. Journal of Personality and Social Psychology, 99, 771–784.
Plomin, R., DeFries, J. C., McClearn, G. E., & McGuffin, P. (2008). Behavioral genetics (5th ed.). New York, NY: Worth.
Radcliffe, N. M., & Klein, W. M. P. (2002). Dispositional, unrealistic, and comparative optimism: Differential relations with knowledge and processing of risk information and beliefs about personal risk. Personality and Social Psychology Bulletin, 28, 836–846.
Rentfrow, P. J., & Gosling, S. D. (2008). The do re mi’s of everyday life: The structure and personality correlates of music preferences. Journal of Personality and Social Psychology, 84, 1236–1256.
No Alignments yet.
Cite this work

- school Campus Bookshelves
- menu_book Bookshelves
- perm_media Learning Objects
- login Login
- how_to_reg Request Instructor Account
- hub Instructor Commons
Margin Size
- Download Page (PDF)
- Download Full Book (PDF)
- Periodic Table
- Physics Constants
- Scientific Calculator
- Reference & Cite
- Tools expand_more
- Readability
selected template will load here
This action is not available.
1.10: Chapter 10 Experimental Research
- Last updated
- Save as PDF
- Page ID 84786

- William Pelz
- Herkimer College via Lumen Learning
\( \newcommand{\vecs}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vecd}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash {#1}}} \)
\( \newcommand{\id}{\mathrm{id}}\) \( \newcommand{\Span}{\mathrm{span}}\)
( \newcommand{\kernel}{\mathrm{null}\,}\) \( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\) \( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\) \( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\inner}[2]{\langle #1, #2 \rangle}\)
\( \newcommand{\Span}{\mathrm{span}}\)
\( \newcommand{\id}{\mathrm{id}}\)
\( \newcommand{\kernel}{\mathrm{null}\,}\)
\( \newcommand{\range}{\mathrm{range}\,}\)
\( \newcommand{\RealPart}{\mathrm{Re}}\)
\( \newcommand{\ImaginaryPart}{\mathrm{Im}}\)
\( \newcommand{\Argument}{\mathrm{Arg}}\)
\( \newcommand{\norm}[1]{\| #1 \|}\)
\( \newcommand{\Span}{\mathrm{span}}\) \( \newcommand{\AA}{\unicode[.8,0]{x212B}}\)
\( \newcommand{\vectorA}[1]{\vec{#1}} % arrow\)
\( \newcommand{\vectorAt}[1]{\vec{\text{#1}}} % arrow\)
\( \newcommand{\vectorB}[1]{\overset { \scriptstyle \rightharpoonup} {\mathbf{#1}} } \)
\( \newcommand{\vectorC}[1]{\textbf{#1}} \)
\( \newcommand{\vectorD}[1]{\overrightarrow{#1}} \)
\( \newcommand{\vectorDt}[1]{\overrightarrow{\text{#1}}} \)
\( \newcommand{\vectE}[1]{\overset{-\!-\!\rightharpoonup}{\vphantom{a}\smash{\mathbf {#1}}}} \)
Experimental research, often considered to be the “gold standard” in research designs, is one of the most rigorous of all research designs. In this design, one or more independent variables are manipulated by the researcher (as treatments), subjects are randomly assigned to different treatment levels (random assignment), and the results of the treatments on outcomes (dependent variables) are observed. The unique strength of experimental research is its internal validity (causality) due to its ability to link cause and effect through treatment manipulation, while controlling for the spurious effect of extraneous variable.
Experimental research is best suited for explanatory research (rather than for descriptive or exploratory research), where the goal of the study is to examine cause-effect relationships. It also works well for research that involves a relatively limited and well-defined set of independent variables that can either be manipulated or controlled. Experimental research can be conducted in laboratory or field settings. Laboratory experiments , conducted in laboratory (artificial) settings, tend to be high in internal validity, but this comes at the cost of low external validity (generalizability), because the artificial (laboratory) setting in which the study is conducted may not reflect the real world. Field experiments , conducted in field settings such as in a real organization, and high in both internal and external validity. But such experiments are relatively rare, because of the difficulties associated with manipulating treatments and controlling for extraneous effects in a field setting.
Experimental research can be grouped into two broad categories: true experimental designs and quasi-experimental designs. Both designs require treatment manipulation, but while true experiments also require random assignment, quasi-experiments do not. Sometimes, we also refer to non-experimental research, which is not really a research design, but an all-inclusive term that includes all types of research that do not employ treatment manipulation or random assignment, such as survey research, observational research, and correlational studies.
Basic Concepts
Treatment and control groups. In experimental research, some subjects are administered one or more experimental stimulus called a treatment (the treatment group ) while other subjects are not given such a stimulus (the control group ). The treatment may be considered successful if subjects in the treatment group rate more favorably on outcome variables than control group subjects. Multiple levels of experimental stimulus may be administered, in which case, there may be more than one treatment group. For example, in order to test the effects of a new drug intended to treat a certain medical condition like dementia, if a sample of dementia patients is randomly divided into three groups, with the first group receiving a high dosage of the drug, the second group receiving a low dosage, and the third group receives a placebo such as a sugar pill (control group), then the first two groups are experimental groups and the third group is a control group. After administering the drug for a period of time, if the condition of the experimental group subjects improved significantly more than the control group subjects, we can say that the drug is effective. We can also compare the conditions of the high and low dosage experimental groups to determine if the high dose is more effective than the low dose.
Treatment manipulation. Treatments are the unique feature of experimental research that sets this design apart from all other research methods. Treatment manipulation helps control for the “cause” in cause-effect relationships. Naturally, the validity of experimental research depends on how well the treatment was manipulated. Treatment manipulation must be checked using pretests and pilot tests prior to the experimental study. Any measurements conducted before the treatment is administered are called pretest measures , while those conducted after the treatment are posttest measures.
Random selection and assignment. Random selection is the process of randomly drawing a sample from a population or a sampling frame. This approach is typically employed in survey research, and assures that each unit in the population has a positive chance of being selected into the sample. Random assignment is however a process of randomly assigning subjects to experimental or control groups. This is a standard practice in true experimental research to ensure that treatment groups are similar (equivalent) to each other and to the control group, prior to treatment administration. Random selection is related to sampling, and is therefore, more closely related to the external validity (generalizability) of findings. However, random assignment is related to design, and is therefore most related to internal validity. It is possible to have both random selection and random assignment in well-designed experimental research, but quasi-experimental research involves neither random selection nor random assignment.
Threats to internal validity. Although experimental designs are considered more rigorous than other research methods in terms of the internal validity of their inferences (by virtue of their ability to control causes through treatment manipulation), they are not immune to internal validity threats. Some of these threats to internal validity are described below, within the context of a study of the impact of a special remedial math tutoring program for improving the math abilities of high school students.
- History threat is the possibility that the observed effects (dependent variables) are caused by extraneous or historical events rather than by the experimental treatment. For instance, students’ post-remedial math score improvement may have been caused by their preparation for a math exam at their school, rather than the remedial math program.
- Maturation threat refers to the possibility that observed effects are caused by natural maturation of subjects (e.g., a general improvement in their intellectual ability to understand complex concepts) rather than the experimental treatment.
- Testing threat is a threat in pre-post designs where subjects’ posttest responses are conditioned by their pretest responses. For instance, if students remember their answers from the pretest evaluation, they may tend to repeat them in the posttest exam. Not conducting a pretest can help avoid this threat.
- Instrumentation threat , which also occurs in pre-post designs, refers to the possibility that the difference between pretest and posttest scores is not due to the remedial math program, but due to changes in the administered test, such as the posttest having a higher or lower degree of difficulty than the pretest.
- Mortality threat refers to the possibility that subjects may be dropping out of the study at differential rates between the treatment and control groups due to a systematic reason, such that the dropouts were mostly students who scored low on the pretest. If the low-performing students drop out, the results of the posttest will be artificially inflated by the preponderance of high-performing students.
- Regression threat , also called a regression to the mean, refers to the statistical tendency of a group’s overall performance on a measure during a posttest to regress toward the mean of that measure rather than in the anticipated direction. For instance, if subjects scored high on a pretest, they will have a tendency to score lower on the posttest (closer to the mean) because their high scores (away from the mean) during the pretest was possibly a statistical aberration. This problem tends to be more prevalent in non-random samples and when the two measures are imperfectly correlated.
Two-Group Experimental Designs
The simplest true experimental designs are two group designs involving one treatment group and one control group, and are ideally suited for testing the effects of a single independent variable that can be manipulated as a treatment. The two basic two-group designs are the pretest-posttest control group design and the posttest-only control group design, while variations may include covariance designs. These designs are often depicted using a standardized design notation, where R represents random assignment of subjects to groups, X represents the treatment administered to the treatment group, and O represents pretest or posttest observations of the dependent variable (with different subscripts to distinguish between pretest and posttest observations of treatment and control groups).
Pretest-posttest control group design. In this design, subjects are randomly assigned to treatment and control groups, subjected to an initial (pretest) measurement of the dependent variables of interest, the treatment group is administered a treatment (representing the independent variable of interest), and the dependent variables measured again (posttest). The notation of this design is shown in Figure 10.1.

IMAGES
VIDEO
COMMENTS
covariance. power. effect size. statistical validity. power. All of the following are advantages of within-groups designs EXCEPT: -participants in the treatment/control groups will be equivalent. -It is less time-consuming for the participants. -It gives researchers more power to find differences between conditions.
assignment measure. measure used to assign participants to experimental and control groups. Those with scores below the cutoff score are assigned to one group, and those with scores above the cutoff are assigned to the other group. Chapter 10 Vocabulary Learn with flashcards, games, and more — for free.
Study with Quizlet and memorize flashcards containing terms like carryover effect, comparison group, concurrent-measures design and more. ... Chapter 10( Research Methods) 32 terms. mlamo011. Preview. Final Exam Psychology 150 (Dr. Kelly) 200 terms. quizlette2786081. Preview. Testing and differences . 26 terms. Bfrias23. Preview. Quiz 14.
luis_herrera5. research methods chapter 10. 22 terms. fcolorad. 1 / 6. Study with Quizlet and memorize flashcards containing terms like What is an experimental design?, What is the principle of parsimony (Occam's razor)?, When can you use a t-test? when between subjects? when within subjects? and more.
Factorial Designs. study the combined effect of two or more independent variables (or factors)simultaneously. Two-way factorial designs. include two independent variables or factors. Meaning of 2x2 vs 3x3 vs 4x2• 2x2: the experiment has two factors, each of which as two levels. • 3x3: the experiment has two factors, each of which as three ...
Introduction to Research Methods Chapter 10. Get a hint. researchers manipulated at least one variable and measured another. - establish covariance, temporal precedence (manipulated variable always comes before measured variable), and can have strong internal validity that rule out any other explanations. Click the card to flip 👆.
Situation noise. A third factor that could cause variability within groups and obscure true group differences. Notes from Research Methods in Psychology, written by Beth Morling- Chapter 10: More on Experiments: Confounding and Obscuring Variables.
Chapter 10 Experimental Research. Experimental research, often considered to be the "gold standard" in research designs, is one of the most rigorous of all research designs. In this design, one or more independent variables are manipulated by the researcher (as treatments), subjects are randomly assigned to different treatment levels ...
Chapter 10: Single-Subject Research. 10.1 Overview of Single-Subject Research. 10.2 Single-Subject Research Designs. 10.3 The Single-Subject Versus Group "Debate". Previous: 9.3 Conducting Surveys.
Research Methods in Psychology is intended to provide a fundamental understanding of the basics of experimental research in the psychological sciences. Research Methods in Psychology adapted by Michael G. Dudley is licensed under Creative Commons Attribution-NonCommercial-ShareAlike 4.0 license. Research Methods in Psychology is adapted from a work produced and distributed under a Creative ...
One of the most rewarding is: providing them with a stake in the project The relationship between synchronic questions and time is: nonexistent A focus group is typically classified as a type of: qualitative interview 11/6/21, 8 : 06 PM Research Methods Chapter 10 Flashcards | Quizlet Page 3 of 3 ____ is the most open style of interviewing ...
Revise your knowledge with these multiple choice quiz questions. Chapter 2: Research in Psychology: Objectives and Ideals. Chapter 3: Research Methods. Chapter 4: Experimental Design. Chapter 5: Survey Design. Chapter 6: Descriptive Statistics. Chapter 7: Some Principles of Statistical Inference. Chapter 8: Examining Differences between Means ...
Chapter 17: Research Methods in the Real World. 17.1 Doing Research for a Living. 17.2 Doing Research for a Cause. 17.3 Revisiting an Earlier Question: Why Should We Care? ... Research Methods for the Social Sciences: An Introduction. Chapter 10: Qualitative Data Collection & Analysis Methods Learning Objectives. Describe the circumstances ...
Our mission is to improve educational access and learning for everyone. OpenStax is part of Rice University, which is a 501 (c) (3) nonprofit. Give today and help us reach more students. Help. OpenStax. This free textbook is an OpenStax resource written to increase student access to high-quality, peer-reviewed learning materials.
Research Methods Lecture; Test 1 study guide - Lecture notes 1-5; Class 1 - Lecture notes 1; Class 2 - Lecture notes 2; Class 3 - Lecture notes 3; Related documents. 8 29 22- Lecture 2 Chapter 2; 8 31 22- Lecture 3-Chapter 3; 11 7 22 - lecture notes fall; ... Chapter 10- Chapter 10: Introduction to Simple Experiments Two Examples of Simple ...
A correlational study is uniquely useful for meeting which of the following goals of the scientific method? A) description: B) creating change ... or things vary together. C) one study uses applied research and a second study uses basic research. D) a measurement is both reliable and valid. 7. ... Home > Chapter 2 > Multiple Choice Quiz I ...
Research Methods in Psychology is intended to provide a fundamental understanding of the basics of experimental research in the psychological sciences. Research Methods in Psychology adapted by Michael G. Dudley is licensed under Creative Commons Attribution-NonCommercial-ShareAlike 4.0 license. Research Methods in Psychology is adapted from a work produced and distributed under a Creative ...
Research Methods Chapter 1 notes; Exam one notes psy; 3.1 notes psy; 1.2 notes psy; Show 8 more documents Show all 35 documents... Practice materials. Date Rating. year. Ratings. Research Methods Exam 2 Study Guide. 5 pages 2019/2020 100% (6) 2019/2020 100% (6) Save. Research Methods Exam 3 Study Guide. 5 pages 2019/2020 100% (3)
Robert Allen "Laud" Humphreys is an American sociologist and author, who is best known for his Ph.D. dissertation, Tearoom Trade , published in 1970. This book is an ethnographic account of anonymous male homosexual encounters in public toilets in parks - a practice known as "tea-rooming" in U.S. gay slang.
Research Methods in Psychology is intended to provide a fundamental understanding of the basics of experimental research in the psychological sciences. Research Methods in Psychology adapted by Michael G. Dudley is licensed under Creative Commons Attribution-NonCommercial-ShareAlike 4.0 license. Research Methods in Psychology is adapted from a work produced and distributed under a Creative ...
E = O1-O2 (1.10.2) (1.10.2) E = O 1 - O 2. Due to the presence of covariates, the right statistical analysis of this design is a two-group analysis of covariance (ANCOVA). This design has all the advantages of post-test only design, but with internal validity due to the controlling of covariates.
Introducing Key Terms in this Chapter Research has its own language, and it is important to understand key terms to use in a study. The title of this book uses the term, research approaches. Research approaches (or methodologies) are procedures for research that span the steps from broad assumptions to detailed methods of data collec-