
- Search by keyword
- Search by citation
Page 1 of 2

Metric-centered and technology-independent architectural views for software comprehension
The maintenance of applications is a crucial activity in the software industry. The high cost of this process is due to the effort invested on software comprehension since, in most of cases, there is no up-to-...
- View Full Text
Back to the future: origins and directions of the “Agile Manifesto” – views of the originators
In 2001, seventeen professionals set up the manifesto for agile software development. They wanted to define values and basic principles for better software development. On top of being brought into focus, the ...
Investigating the effectiveness of peer code review in distributed software development based on objective and subjective data
Code review is a potential means of improving software quality. To be effective, it depends on different factors, and many have been investigated in the literature to identify the scenarios in which it adds qu...
On the benefits and challenges of using kanban in software engineering: a structured synthesis study
Kanban is increasingly being used in diverse software organizations. There is extensive research regarding its benefits and challenges in Software Engineering, reported in both primary and secondary studies. H...
Challenges on applying genetic improvement in JavaScript using a high-performance computer
Genetic Improvement is an area of Search Based Software Engineering that aims to apply evolutionary computing operators to the software source code to improve it according to one or more quality metrics. This ...
Actor’s social complexity: a proposal for managing the iStar model
Complex systems are inherent to modern society, in which individuals, organizations, and computational elements relate with each other to achieve a predefined purpose, which transcends individual goals. In thi...
Investigating measures for applying statistical process control in software organizations
The growing interest in improving software processes has led organizations to aim for high maturity, where statistical process control (SPC) is required. SPC makes it possible to analyze process behavior, pred...
An approach for applying Test-Driven Development (TDD) in the development of randomized algorithms
TDD is a technique traditionally applied in applications with deterministic algorithms, in which the input and the expected result are known. However, the application of TDD with randomized algorithms have bee...
Supporting governance of mobile application developers from mining and analyzing technical questions in stack overflow
There is a need to improve the direct communication between large organizations that maintain mobile platforms (e.g. Apple, Google, and Microsoft) and third-party developers to solve technical questions that e...
Working software over comprehensive documentation – Rationales of agile teams for artefacts usage
Agile software development (ASD) promotes working software over comprehensive documentation. Still, recent research has shown agile teams to use quite a number of artefacts. Whereas some artefacts may be adopt...
Development as a journey: factors supporting the adoption and use of software frameworks
From the point of view of the software framework owner, attracting new and supporting existing application developers is crucial for the long-term success of the framework. This mixed-methods study explores th...
Applying user-centered techniques to analyze and design a mobile application
Techniques that help in understanding and designing user needs are increasingly being used in Software Engineering to improve the acceptance of applications. Among these techniques we can cite personas, scenar...
A measurement model to analyze the effect of agile enterprise architecture on geographically distributed agile development
Efficient and effective communication (active communication) among stakeholders is thought to be central to agile development. However, in geographically distributed agile development (GDAD) environments, it c...
A survey of search-based refactoring for software maintenance
This survey reviews published materials related to the specific area of Search-Based Software Engineering that concerns software maintenance and, in particular, refactoring. The survey aims to give a comprehen...
Guest editorial foreword for the special issue on automated software testing: trends and evidence
Similarity testing for role-based access control systems.
Access control systems demand rigorous verification and validation approaches, otherwise, they can end up with security breaches. Finite state machines based testing has been successfully applied to RBAC syste...
An algorithm for combinatorial interaction testing: definitions and rigorous evaluations
Combinatorial Interaction Testing (CIT) approaches have drawn attention of the software testing community to generate sets of smaller, efficient, and effective test cases where they have been successful in det...
How diverse is your team? Investigating gender and nationality diversity in GitHub teams
Building an effective team of developers is a complex task faced by both software companies and open source communities. The problem of forming a “dream”
Investigating factors that affect the human perception on god class detection: an analysis based on a family of four controlled experiments
Evaluation of design problems in object oriented systems, which we call code smells, is mostly a human-based task. Several studies have investigated the impact of code smells in practice. Studies focusing on h...
On the evaluation of code smells and detection tools
Code smells refer to any symptom in the source code of a program that possibly indicates a deeper problem, hindering software maintenance and evolution. Detection of code smells is challenging for developers a...
On the influence of program constructs on bug localization effectiveness
Software projects often reach hundreds or thousands of files. Therefore, manually searching for code elements that should be changed to fix a failure is a difficult task. Static bug localization techniques pro...
DyeVC: an approach for monitoring and visualizing distributed repositories
Software development using distributed version control systems has become more frequent recently. Such systems bring more flexibility, but also greater complexity to manage and monitor multiple existing reposi...
A genetic algorithm based framework for software effort prediction
Several prediction models have been proposed in the literature using different techniques obtaining different results in different contexts. The need for accurate effort predictions for projects is one of the ...
Elaboration of software requirements documents by means of patterns instantiation
Studies show that problems associated with the requirements specifications are widely recognized for affecting software quality and impacting effectiveness of its development process. The reuse of knowledge ob...
ArchReco: a software tool to assist software design based on context aware recommendations of design patterns
This work describes the design, development and evaluation of a software Prototype, named ArchReco, an educational tool that employs two types of Context-aware Recommendations of Design Patterns, to support us...
On multi-language software development, cross-language links and accompanying tools: a survey of professional software developers
Non-trivial software systems are written using multiple (programming) languages, which are connected by cross-language links. The existence of such links may lead to various problems during software developmen...
SoftCoDeR approach: promoting Software Engineering Academia-Industry partnership using CMD, DSR and ESE
The Academia-Industry partnership has been increasingly encouraged in the software development field. The main focus of the initiatives is driven by the collaborative work where the scientific research work me...
Issues on developing interoperable cloud applications: definitions, concepts, approaches, requirements, characteristics and evaluation models
Among research opportunities in software engineering for cloud computing model, interoperability stands out. We found that the dynamic nature of cloud technologies and the battle for market domination make clo...
Game development software engineering process life cycle: a systematic review
Software game is a kind of application that is used not only for entertainment, but also for serious purposes that can be applicable to different domains such as education, business, and health care. Multidisc...
Correlating automatic static analysis and mutation testing: towards incremental strategies
Traditionally, mutation testing is used as test set generation and/or test evaluation criteria once it is considered a good fault model. This paper uses mutation testing for evaluating an automated static anal...
A multi-objective test data generation approach for mutation testing of feature models
Mutation approaches have been recently applied for feature testing of Software Product Lines (SPLs). The idea is to select products, associated to mutation operators that describe possible faults in the Featur...
An extended global software engineering taxonomy
In Global Software Engineering (GSE), the need for a common terminology and knowledge classification has been identified to facilitate the sharing and combination of knowledge by GSE researchers and practition...
A systematic process for obtaining the behavior of context-sensitive systems
Context-sensitive systems use contextual information in order to adapt to the user’s current needs or requirements failure. Therefore, they need to dynamically adapt their behavior. It is of paramount importan...
Distinguishing extended finite state machine configurations using predicate abstraction
Extended Finite State Machines (EFSMs) provide a powerful model for the derivation of functional tests for software systems and protocols. Many EFSM based testing problems, such as mutation testing, fault diag...
Extending statecharts to model system interactions
Statecharts are diagrams comprised of visual elements that can improve the modeling of reactive system behaviors. They extend conventional state diagrams with the notions of hierarchy, concurrency and communic...
On the relationship of code-anomaly agglomerations and architectural problems
Several projects have been discontinued in the history of the software industry due to the presence of software architecture problems. The identification of such problems in source code is often required in re...
An approach based on feature models and quality criteria for adapting component-based systems
Feature modeling has been widely used in domain engineering for the development and configuration of software product lines. A feature model represents the set of possible products or configurations to apply i...
Patch rejection in Firefox: negative reviews, backouts, and issue reopening
Writing patches to fix bugs or implement new features is an important software development task, as it contributes to raise the quality of a software system. Not all patches are accepted in the first attempt, ...
Investigating probabilistic sampling approaches for large-scale surveys in software engineering
Establishing representative samples for Software Engineering surveys is still considered a challenge. Specialized literature often presents limitations on interpreting surveys’ results, mainly due to the use o...
Characterising the state of the practice in software testing through a TMMi-based process
The software testing phase, despite its importance, is usually compromised by the lack of planning and resources in industry. This can risk the quality of the derived products. The identification of mandatory ...
Self-adaptation by coordination-targeted reconfigurations
A software system is self-adaptive when it is able to dynamically and autonomously respond to changes detected either in its internal components or in its deployment environment. This response is expected to ensu...
Templates for textual use cases of software product lines: results from a systematic mapping study and a controlled experiment
Use case templates can be used to describe functional requirements of a Software Product Line. However, to the best of our knowledge, no efforts have been made to collect and summarize these existing templates...
F3T: a tool to support the F3 approach on the development and reuse of frameworks
Frameworks are used to enhance the quality of applications and the productivity of the development process, since applications may be designed and implemented by reusing framework classes. However, frameworks ...
NextBug: a Bugzilla extension for recommending similar bugs
Due to the characteristics of the maintenance process followed in open source systems, developers are usually overwhelmed with a great amount of bugs. For instance, in 2012, approximately 7,600 bugs/month were...
Assessing the benefits of search-based approaches when designing self-adaptive systems: a controlled experiment
The well-orchestrated use of distilled experience, domain-specific knowledge, and well-informed trade-off decisions is imperative if we are to design effective architectures for complex software-intensive syst...
Revealing influence of model structure and test case profile on the prioritization of test cases in the context of model-based testing
Test case prioritization techniques aim at defining an order of test cases that favor the achievement of a goal during test execution, such as revealing failures as earlier as possible. A number of techniques ...
A metrics suite for JUnit test code: a multiple case study on open source software
The code of JUnit test cases is commonly used to characterize software testing effort. Different metrics have been proposed in literature to measure various perspectives of the size of JUnit test cases. Unfort...
Designing fault-tolerant SOA based on design diversity
Over recent years, software developers have been evaluating the benefits of both Service-Oriented Architecture (SOA) and software fault tolerance techniques based on design diversity. This is achieved by creat...
Method-level code clone detection through LWH (Light Weight Hybrid) approach
Many researchers have investigated different techniques to automatically detect duplicate code in programs exceeding thousand lines of code. These techniques have limitations in finding either the structural o...
The problem of conceptualization in god class detection: agreement, strategies and decision drivers
The concept of code smells is widespread in Software Engineering. Despite the empirical studies addressing the topic, the set of context-dependent issues that impacts the human perception of what is a code sme...
- Editorial Board
- Sign up for article alerts and news from this journal
software engineering Recently Published Documents
Total documents.
- Latest Documents
- Most Cited Documents
- Contributed Authors
- Related Sources
- Related Keywords
Identifying Non-Technical Skill Gaps in Software Engineering Education: What Experts Expect But Students Don’t Learn
As the importance of non-technical skills in the software engineering industry increases, the skill sets of graduates match less and less with industry expectations. A growing body of research exists that attempts to identify this skill gap. However, only few so far explicitly compare opinions of the industry with what is currently being taught in academia. By aggregating data from three previous works, we identify the three biggest non-technical skill gaps between industry and academia for the field of software engineering: devoting oneself to continuous learning , being creative by approaching a problem from different angles , and thinking in a solution-oriented way by favoring outcome over ego . Eight follow-up interviews were conducted to further explore how the industry perceives these skill gaps, yielding 26 sub-themes grouped into six bigger themes: stimulating continuous learning , stimulating creativity , creative techniques , addressing the gap in education , skill requirements in industry , and the industry selection process . With this work, we hope to inspire educators to give the necessary attention to the uncovered skills, further mitigating the gap between the industry and the academic world.
Opportunities and Challenges in Code Search Tools
Code search is a core software engineering task. Effective code search tools can help developers substantially improve their software development efficiency and effectiveness. In recent years, many code search studies have leveraged different techniques, such as deep learning and information retrieval approaches, to retrieve expected code from a large-scale codebase. However, there is a lack of a comprehensive comparative summary of existing code search approaches. To understand the research trends in existing code search studies, we systematically reviewed 81 relevant studies. We investigated the publication trends of code search studies, analyzed key components, such as codebase, query, and modeling technique used to build code search tools, and classified existing tools into focusing on supporting seven different search tasks. Based on our findings, we identified a set of outstanding challenges in existing studies and a research roadmap for future code search research.
Psychometrics in Behavioral Software Engineering: A Methodological Introduction with Guidelines
A meaningful and deep understanding of the human aspects of software engineering (SE) requires psychological constructs to be considered. Psychology theory can facilitate the systematic and sound development as well as the adoption of instruments (e.g., psychological tests, questionnaires) to assess these constructs. In particular, to ensure high quality, the psychometric properties of instruments need evaluation. In this article, we provide an introduction to psychometric theory for the evaluation of measurement instruments for SE researchers. We present guidelines that enable using existing instruments and developing new ones adequately. We conducted a comprehensive review of the psychology literature framed by the Standards for Educational and Psychological Testing. We detail activities used when operationalizing new psychological constructs, such as item pooling, item review, pilot testing, item analysis, factor analysis, statistical property of items, reliability, validity, and fairness in testing and test bias. We provide an openly available example of a psychometric evaluation based on our guideline. We hope to encourage a culture change in SE research towards the adoption of established methods from psychology. To improve the quality of behavioral research in SE, studies focusing on introducing, validating, and then using psychometric instruments need to be more common.
Towards an Anatomy of Software Craftsmanship
Context: The concept of software craftsmanship has early roots in computing, and in 2009, the Manifesto for Software Craftsmanship was formulated as a reaction to how the Agile methods were practiced and taught. But software craftsmanship has seldom been studied from a software engineering perspective. Objective: The objective of this article is to systematize an anatomy of software craftsmanship through literature studies and a longitudinal case study. Method: We performed a snowballing literature review based on an initial set of nine papers, resulting in 18 papers and 11 books. We also performed a case study following seven years of software development of a product for the financial market, eliciting qualitative, and quantitative results. We used thematic coding to synthesize the results into categories. Results: The resulting anatomy is centered around four themes, containing 17 principles and 47 hierarchical practices connected to the principles. We present the identified practices based on the experiences gathered from the case study, triangulating with the literature results. Conclusion: We provide our systematically derived anatomy of software craftsmanship with the goal of inspiring more research into the principles and practices of software craftsmanship and how these relate to other principles within software engineering in general.
On the Reproducibility and Replicability of Deep Learning in Software Engineering
Context: Deep learning (DL) techniques have gained significant popularity among software engineering (SE) researchers in recent years. This is because they can often solve many SE challenges without enormous manual feature engineering effort and complex domain knowledge. Objective: Although many DL studies have reported substantial advantages over other state-of-the-art models on effectiveness, they often ignore two factors: (1) reproducibility —whether the reported experimental results can be obtained by other researchers using authors’ artifacts (i.e., source code and datasets) with the same experimental setup; and (2) replicability —whether the reported experimental result can be obtained by other researchers using their re-implemented artifacts with a different experimental setup. We observed that DL studies commonly overlook these two factors and declare them as minor threats or leave them for future work. This is mainly due to high model complexity with many manually set parameters and the time-consuming optimization process, unlike classical supervised machine learning (ML) methods (e.g., random forest). This study aims to investigate the urgency and importance of reproducibility and replicability for DL studies on SE tasks. Method: In this study, we conducted a literature review on 147 DL studies recently published in 20 SE venues and 20 AI (Artificial Intelligence) venues to investigate these issues. We also re-ran four representative DL models in SE to investigate important factors that may strongly affect the reproducibility and replicability of a study. Results: Our statistics show the urgency of investigating these two factors in SE, where only 10.2% of the studies investigate any research question to show that their models can address at least one issue of replicability and/or reproducibility. More than 62.6% of the studies do not even share high-quality source code or complete data to support the reproducibility of their complex models. Meanwhile, our experimental results show the importance of reproducibility and replicability, where the reported performance of a DL model could not be reproduced for an unstable optimization process. Replicability could be substantially compromised if the model training is not convergent, or if performance is sensitive to the size of vocabulary and testing data. Conclusion: It is urgent for the SE community to provide a long-lasting link to a high-quality reproduction package, enhance DL-based solution stability and convergence, and avoid performance sensitivity on different sampled data.
Predictive Software Engineering: Transform Custom Software Development into Effective Business Solutions
The paper examines the principles of the Predictive Software Engineering (PSE) framework. The authors examine how PSE enables custom software development companies to offer transparent services and products while staying within the intended budget and a guaranteed budget. The paper will cover all 7 principles of PSE: (1) Meaningful Customer Care, (2) Transparent End-to-End Control, (3) Proven Productivity, (4) Efficient Distributed Teams, (5) Disciplined Agile Delivery Process, (6) Measurable Quality Management and Technical Debt Reduction, and (7) Sound Human Development.
Software—A New Open Access Journal on Software Engineering
Software (ISSN: 2674-113X) [...]
Improving bioinformatics software quality through incorporation of software engineering practices
Background Bioinformatics software is developed for collecting, analyzing, integrating, and interpreting life science datasets that are often enormous. Bioinformatics engineers often lack the software engineering skills necessary for developing robust, maintainable, reusable software. This study presents review and discussion of the findings and efforts made to improve the quality of bioinformatics software. Methodology A systematic review was conducted of related literature that identifies core software engineering concepts for improving bioinformatics software development: requirements gathering, documentation, testing, and integration. The findings are presented with the aim of illuminating trends within the research that could lead to viable solutions to the struggles faced by bioinformatics engineers when developing scientific software. Results The findings suggest that bioinformatics engineers could significantly benefit from the incorporation of software engineering principles into their development efforts. This leads to suggestion of both cultural changes within bioinformatics research communities as well as adoption of software engineering disciplines into the formal education of bioinformatics engineers. Open management of scientific bioinformatics development projects can result in improved software quality through collaboration amongst both bioinformatics engineers and software engineers. Conclusions While strides have been made both in identification and solution of issues of particular import to bioinformatics software development, there is still room for improvement in terms of shifts in both the formal education of bioinformatics engineers as well as the culture and approaches of managing scientific bioinformatics research and development efforts.
Inter-team communication in large-scale co-located software engineering: a case study
AbstractLarge-scale software engineering is a collaborative effort where teams need to communicate to develop software products. Managers face the challenge of how to organise work to facilitate necessary communication between teams and individuals. This includes a range of decisions from distributing work over teams located in multiple buildings and sites, through work processes and tools for coordinating work, to softer issues including ensuring well-functioning teams. In this case study, we focus on inter-team communication by considering geographical, cognitive and psychological distances between teams, and factors and strategies that can affect this communication. Data was collected for ten test teams within a large development organisation, in two main phases: (1) measuring cognitive and psychological distance between teams using interactive posters, and (2) five focus group sessions where the obtained distance measurements were discussed. We present ten factors and five strategies, and how these relate to inter-team communication. We see three types of arenas that facilitate inter-team communication, namely physical, virtual and organisational arenas. Our findings can support managers in assessing and improving communication within large development organisations. In addition, the findings can provide insights into factors that may explain the challenges of scaling development organisations, in particular agile organisations that place a large emphasis on direct communication over written documentation.
Aligning Software Engineering and Artificial Intelligence With Transdisciplinary
Study examined AI and SE transdisciplinarity to find ways of aligning them to enable development of AI-SE transdisciplinary theory. Literature review and analysis method was used. The findings are AI and SE transdisciplinarity is tacit with islands within and between them that can be linked to accelerate their transdisciplinary orientation by codification, internally developing and externally borrowing and adapting transdisciplinary theories. Lack of theory has been identified as the major barrier toward towards maturing the two disciplines as engineering disciplines. Creating AI and SE transdisciplinary theory would contribute to maturing AI and SE engineering disciplines. Implications of study are transdisciplinary theory can support mode 2 and 3 AI and SE innovations; provide an alternative for maturing two disciplines as engineering disciplines. Study’s originality it’s first in SE, AI or their intersections.
Export Citation Format
Share document.

Navigation Menu
Search code, repositories, users, issues, pull requests..., provide feedback.
We read every piece of feedback, and take your input very seriously.
Saved searches
Use saved searches to filter your results more quickly.
To see all available qualifiers, see our documentation .
- Notifications You must be signed in to change notification settings
📚 A curated list of papers for Software Engineers
facundoolano/software-papers
Folders and files.
| Name | Name | |||
|---|---|---|---|---|
| 150 Commits | ||||
Repository files navigation
Papers for software engineers.
A curated list of papers that may be of interest to Software Engineering students or professionals. See the sources and selection criteria below.
Von Neumann's First Computer Program. Knuth (1970) . Computer History; Early Programming
- The Education of a Computer. Hopper (1952) .
- Recursive Programming. Dijkstra (1960) .
- Programming Considered as a Human Activity. Dijkstra (1965) .
- Goto Statement Considered Harmful. Dijkstra (1968) .
- Program development by stepwise refinement. Wirth (1971) .
- The Humble Programmer. Dijkstra (1972) .
- Computer Programming as an Art. Knuth (1974) .
- The paradigms of programming. Floyd (1979) .
- Literate Programming. Knuth (1984) .
Computing Machinery and Intelligence. Turing (1950) . Early Artificial Intelligence
- Some Moral and Technical Consequences of Automation. Wiener (1960) .
- Steps towards Artificial Intelligence. Minsky (1960) .
- ELIZA—a computer program for the study of natural language communication between man and machine. Weizenbaum (1966) .
- A Theory of the Learnable. Valiant (1984) .
A Method for the Construction of Minimum-Redundancy Codes. Huffman (1952) . Information Theory
- A Universal Algorithm for Sequential Data Compression. Ziv, Lempel (1977) .
- Fifty Years of Shannon Theory. Verdú (1998) .
Engineering a Sort Function. Bentley, McIlroy (1993) . Data Structures; Algorithms
- On the Shortest Spanning Subtree of a Graph and the Traveling Salesman Problem. Kruskal (1956) .
- A Note on Two Problems in Connexion with Graphs. Dijkstra (1959) .
- Quicksort. Hoare (1962) .
- Space/Time Trade-offs in Hash Coding with Allowable Errors. Bloom (1970) .
- The Ubiquitous B-Tree. Comer (1979) .
- Programming pearls: Algorithm design techniques. Bentley (1984) .
- Programming pearls: The back of the envelope. Bentley (1984) .
- Making data structures persistent. Driscoll et al (1986) .
A Design Methodology for Reliable Software Systems. Liskov (1972) . Software Design
- On the Criteria To Be Used in Decomposing Systems into Modules. Parnas (1971) .
- Information Distribution Aspects of Design Methodology. Parnas (1972) .
- Designing Software for Ease of Extension and Contraction. Parnas (1979) .
- Programming as Theory Building. Naur (1985) .
- Software Aging. Parnas (1994) .
- Towards a Theory of Conceptual Design for Software. Jackson (2015) .
Programming with Abstract Data Types. Liskov, Zilles (1974) . Abstract Data Types; Object-Oriented Programming
- The Smalltalk-76 Programming System Design and Implementation. Ingalls (1978) .
- A Theory of Type Polymorphism in Programming. Milner (1978) .
- On understanding types, data abstraction, and polymorphism. Cardelli, Wegner (1985) .
- SELF: The Power of Simplicity. Ungar, Smith (1991) .
Why Functional Programming Matters. Hughes (1990) . Functional Programming
- Recursive Functions of Symbolic Expressions and Their Computation by Machine. McCarthy (1960) .
- The Semantics of Predicate Logic as a Programming Language. Van Emden, Kowalski (1976) .
- Can Programming Be Liberated from the von Neumann Style? Backus (1978) .
- The Semantic Elegance of Applicative Languages. Turner (1981) .
- The essence of functional programming. Wadler (1992) .
- QuickCheck: A Lightweight Tool for Random Testing of Haskell Programs. Claessen, Hughes (2000) .
- Church's Thesis and Functional Programming. Turner (2006) .
An Incremental Approach to Compiler Construction. Ghuloum (2006) . Language Design; Compilers
- The Next 700 Programming Languages. Landin (1966) .
- Programming pearls: little languages. Bentley (1986) .
- The Essence of Compiling with Continuations. Flanagan et al (1993) .
- A Brief History of Just-In-Time. Aycock (2003) .
- LLVM: A Compilation Framework for Lifelong Program Analysis & Transformation. Lattner, Adve (2004) .
- A Unified Theory of Garbage Collection. Bacon, Cheng, Rajan (2004) .
- A Nanopass Framework for Compiler Education. Sarkar, Waddell, Dybvig (2005) .
- Bringing the Web up to Speed with WebAssembly. Haas (2017) .
No Silver Bullet: Essence and Accidents of Software Engineering. Brooks (1987) . Software Engineering; Project Management
- How do committees invent? Conway (1968) .
- Managing the Development of Large Software Systems. Royce (1970) .
- The Mythical Man Month. Brooks (1975) .
- On Building Systems That Will Fail. Corbató (1991) .
- The Cathedral and the Bazaar. Raymond (1998) .
- Out of the Tar Pit. Moseley, Marks (2006) .
Communicating sequential processes. Hoare (1978) . Concurrency
- Solution Of a Problem in Concurrent Program Control. Dijkstra (1965) .
- Monitors: An operating system structuring concept. Hoare (1974) .
- On the Duality of Operating System Structures. Lauer, Needham (1978) .
- Software Transactional Memory. Shavit, Touitou (1997) .
The UNIX Time- Sharing System. Ritchie, Thompson (1974) . Operating Systems
- An Experimental Time-Sharing System. Corbató, Merwin Daggett, Daley (1962) .
- The Structure of the "THE"-Multiprogramming System. Dijkstra (1968) .
- The nucleus of a multiprogramming system. Hansen (1970) .
- Reflections on Trusting Trust. Thompson (1984) .
- The Design and Implementation of a Log-Structured File System. Rosenblum, Ousterhout (1991) .
A Relational Model of Data for Large Shared Data Banks. Codd (1970) . Databases
- Granularity of Locks and Degrees of Consistency in a Shared Data Base. Gray et al (1975) .
- Access Path Selection in a Relational Database Management System. Selinger et al (1979) .
- The Transaction Concept: Virtues and Limitations. Gray (1981) .
- The design of POSTGRES. Stonebraker, Rowe (1986) .
- Rules of Thumb in Data Engineering. Gray, Shenay (1999) .
A Protocol for Packet Network Intercommunication. Cerf, Kahn (1974) . Networking
- Ethernet: Distributed packet switching for local computer networks. Metcalfe, Boggs (1978) .
- End-To-End Arguments in System Design. Saltzer, Reed, Clark (1984) .
- An algorithm for distributed computation of a Spanning Tree in an Extended LAN. Perlman (1985) .
- The Design Philosophy of the DARPA Internet Protocols. Clark (1988) .
- TOR: The second generation onion router. Dingledine et al (2004) .
- Why the Internet only just works. Handley (2006) .
- The Network is Reliable. Bailis, Kingsbury (2014) .
New Directions in Cryptography. Diffie, Hellman (1976) . Cryptography
- A Method for Obtaining Digital Signatures and Public-Key Cryptosystems. Rivest, Shamir, Adleman (1978) .
- How To Share A Secret. Shamir (1979) .
- A Digital Signature Based on a Conventional Encryption Function. Merkle (1987) .
- The Salsa20 family of stream ciphers. Bernstein (2007) .
Time, Clocks, and the Ordering of Events in a Distributed System. Lamport (1978) . Distributed Systems
- Self-stabilizing systems in spite of distributed control. Dijkstra (1974) .
- The Byzantine Generals Problem. Lamport, Shostak, Pease (1982) .
- Impossibility of Distributed Consensus With One Faulty Process. Fisher, Lynch, Patterson (1985) .
- Implementing Fault-Tolerant Services Using the State Machine Approach: A Tutorial. Schneider (1990) .
- Practical Byzantine Fault Tolerance. Castro, Liskov (1999) .
- Paxos made simple. Lamport (2001) .
- Paxos made live - An Engineering Perspective. Chandra, Griesemer, Redstone (2007) .
- In Search of an Understandable Consensus Algorithm. Ongaro, Ousterhout (2014) .
Designing for Usability: Key Principles and What Designers Think. Gould, Lewis (1985) . Human-Computer Interaction; User Interfaces
- As We May Think. Bush (1945) .
- Man-Computer symbiosis. Licklider (1958) .
- Some Thoughts About the Social Implications of Accessible Computing. David, Fano (1965) .
- Tutorials for the First-Time Computer User. Al-Awar, Chapanis, Ford (1981) .
- The star user interface: an overview. Smith, Irby, Kimball (1982) .
- Design Principles for Human-Computer Interfaces. Norman (1983) .
- Human-Computer Interaction: Psychology as a Science of Design. Carroll (1997) .
The anatomy of a large-scale hypertextual Web search engine. Brin, Page (1998) . Information Retrieval; World-Wide Web
- A Statistical Interpretation of Term Specificity in Retrieval. Spärck Jones (1972) .
- World-Wide Web: Information Universe. Berners-Lee et al (1992) .
- The PageRank Citation Ranking: Bringing Order to the Web. Page, Brin, Motwani (1998) .
Dynamo, Amazon’s Highly Available Key-value store. DeCandia et al (2007) . Internet Scale Data Systems
- The Google File System. Ghemawat, Gobioff, Leung (2003) .
- MapReduce: Simplified Data Processing on Large Clusters. Dean, Ghemawat (2004) .
- Bigtable: A Distributed Storage System for Structured Data. Chang et al (2006) .
- ZooKeeper: wait-free coordination for internet scale systems. Hunt et al (2010) .
- The Hadoop Distributed File System. Shvachko et al (2010) .
- Kafka: a Distributed Messaging System for Log Processing. Kreps, Narkhede, Rao (2011) .
- CAP Twelve Years Later: How the "Rules" Have Changed. Brewer (2012) .
- Amazon Aurora: Design Considerations for High Throughput Cloud-Native Relational Databases. Verbitski et al (2017) .
On Designing and Deploying Internet Scale Services. Hamilton (2007) . Operations; Reliability; Fault-tolerance
- Ironies of Automation. Bainbridge (1983) .
- Why do computers stop and what can be done about it? Gray (1985) .
- Recovery Oriented Computing (ROC): Motivation, Definition, Techniques, and Case Studies. Patterson et al (2002) .
- Crash-Only Software. Candea, Fox (2003) .
- Building on Quicksand. Helland, Campbell (2009) .
Thinking Methodically about Performance. Gregg (2012) . Performance
- Performance Anti-Patterns. Smaalders (2006) .
- Thinking Clearly about Performance. Millsap (2010) .
Bitcoin, A peer-to-peer electronic cash system. Nakamoto (2008) . Decentralized Distributed Systems; Peer-to-peer systems
- Operational transformation in real-time group editors: issues, algorithms, and achievements. Sun, Ellis (1998) .
- Kademlia: A Peer-to-Peer Information System Based on the XOR Metric. Maymounkov, Mazières (2002) .
- Incentives Build Robustness in BitTorrent. Cohen (2003) .
- Conflict-free Replicated Data Types. Shapiro et al (2011) .
- IPFS - Content Addressed, Versioned, P2P File System. Benet (2014) .
- Ethereum: A Next-Generation Smart Contract and Decentralized Application Platform. Buterin (2014) .
- Local-First Software: You Own Your Data, in spite of the Cloud. Kleppmann et al (2019) .
A Few Useful Things to Know About Machine Learning. Domingos (2012) . Machine Learning
- Statistical Modeling: The Two Cultures. Breiman (2001) .
- The Unreasonable Effectiveness of Data. Halevy, Norvig, Pereira (2009) .
- ImageNet Classification with Deep Convolutional Neural Networks. Krizhevsky, Sutskever, Hinton (2012) .
- Playing Atari with Deep Reinforcement Learning. Mnih et al (2013) .
- Generative Adversarial Nets. Goodfellow et al (2014) .
- Deep Learning. LeCun, Bengio, Hinton (2015) .
- Attention Is All You Need. Vaswani et al (2017) .
- Von Neumann's First Computer Program. Knuth (1970) .
- Computing Machinery and Intelligence. Turing (1950) .
- A Method for the Construction of Minimum-Redundancy Codes. Huffman (1952) .
- Engineering a Sort Function. Bentley, McIlroy (1993) .
- A Design Methodology for Reliable Software Systems. Liskov (1972) .
- Programming with Abstract Data Types. Liskov, Zilles (1974) .
- Why Functional Programming Matters. Hughes (1990) .
- An Incremental Approach to Compiler Construction. Ghuloum (2006) .
- No Silver Bullet: Essence and Accidents of Software Engineering. Brooks (1987) .
- Communicating sequential processes. Hoare (1978) .
- The UNIX Time- Sharing System. Ritchie, Thompson (1974) .
- A Relational Model of Data for Large Shared Data Banks. Codd (1970) .
- A Protocol for Packet Network Intercommunication. Cerf, Kahn (1974) .
- New Directions in Cryptography. Diffie, Hellman (1976) .
- Time, Clocks, and the Ordering of Events in a Distributed System. Lamport (1978) .
- Designing for Usability: Key Principles and What Designers Think. Gould, Lewis (1985) .
- The anatomy of a large-scale hypertextual Web search engine. Brin, Page (1998) .
- Dynamo, Amazon’s Highly Available Key-value store. DeCandia et al (2007) .
- On Designing and Deploying Internet Scale Services. Hamilton (2007) .
- Thinking Methodically about Performance. Gregg (2012) .
- Bitcoin, A peer-to-peer electronic cash system. Nakamoto (2008) .
- A Few Useful Things to Know About Machine Learning. Domingos (2012) .
This list was inspired by (and draws from) several books and paper collections:
- Papers We Love
- Ideas That Created the Future
- The Innovators
- The morning paper
- Distributed systems for fun and profit
- Readings in Database Systems (the Red Book)
- Fermat's Library
- Classics in Human-Computer Interaction
- Awesome Compilers
- Distributed Consensus Reading List
- The Decade of Deep Learning
A few interesting resources about reading papers from Papers We Love and elsewhere:
- Should I read papers?
- How to Read an Academic Article
- How to Read a Paper. Keshav (2007) .
- Efficient Reading of Papers in Science and Technology. Hanson (1999) .
- On ICSE’s “Most Influential Papers”. Parnas (1995) .
Selection criteria
- The idea is not to include every interesting paper that I come across but rather to keep a representative list that's possible to read from start to finish with a similar level of effort as reading a technical book from cover to cover.
- I tried to include one paper per each major topic and author. Since in the process I found a lot of noteworthy alternatives, related or follow-up papers and I wanted to keep track of those as well, I included them as sublist items.
- The papers shouldn't be too long. For the same reasons as the previous item, I try to avoid papers longer than 20 or 30 pages.
- They should be self-contained and readable enough to be approachable by the casual technical reader.
- They should be freely available online.
- Examples of this are classic works by Von Neumann, Turing and Shannon.
- That being said, where possible I preferred the original paper on each subject over modern updates or survey papers.
- Similarly, I tended to skip more theoretical papers, those focusing on mathematical foundations for Computer Science, electronic aspects of hardware, etc.
- I sorted the list by a mix of relatedness of topics and a vague chronological relevance, such that it makes sense to read it in the suggested order. For example, historical and seminal topics go first, contemporary internet-era developments last, networking precedes distributed systems, etc.
Sponsor this project
Contributors 4.
- Python 100.0%
Software Engineering
At Google, we pride ourselves on our ability to develop and launch new products and features at a very fast pace. This is made possible in part by our world-class engineers, but our approach to software development enables us to balance speed and quality, and is integral to our success. Our obsession for speed and scale is evident in our developer infrastructure and tools. Developers across the world continually write, build, test and release code in multiple programming languages like C++, Java, Python, Javascript and others, and the Engineering Tools team, for example, is challenged to keep this development ecosystem running smoothly. Our engineers leverage these tools and infrastructure to produce clean code and keep software development running at an ever-increasing scale. In our publications, we share associated technical challenges and lessons learned along the way.
Recent Publications
Some of our teams.
Africa team
Climate and sustainability
Software engineering and programming languages
We're always looking for more talented, passionate people.

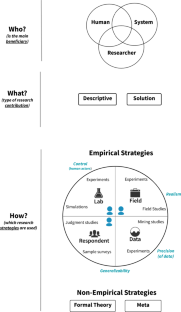
The who, what, how of software engineering research: a socio-technical framework
- Published: 28 August 2020
- Volume 25 , pages 4097–4129, ( 2020 )
Cite this article

- Margaret-Anne Storey ORCID: orcid.org/0000-0003-2278-2536 1 ,
- Neil A. Ernst 1 ,
- Courtney Williams 1 &
- Eirini Kalliamvakou 1
2904 Accesses
15 Altmetric
Explore all metrics
Software engineering is a socio-technical endeavor, and while many of our contributions focus on technical aspects, human stakeholders such as software developers are directly affected by and can benefit from our research and tool innovations. In this paper, we question how much of our research addresses human and social issues, and explore how much we study human and social aspects in our research designs. To answer these questions, we developed a socio-technical research framework to capture the main beneficiary of a research study (the who ), the main type of research contribution produced (the what ), and the research strategies used in the study ( how we methodologically approach delivering relevant results given the who and what of our studies). We used this Who-What-How framework to analyze 151 papers from two well-cited publishing venues—the main technical track at the International Conference on Software Engineering, and the Empirical Software Engineering Journal by Springer—to assess how much this published research explicitly considers human aspects. We find that although a majority of these papers claim the contained research should benefit human stakeholders, most focus predominantly on technical contributions. Although our analysis is scoped to two venues, our results suggest a need for more diversification and triangulation of research strategies. In particular, there is a need for strategies that aim at a deeper understanding of human and social aspects of software development practice to balance the design and evaluation of technical innovations. We recommend that the framework should be used in the design of future studies in order to steer software engineering research towards explicitly including human and social concerns in their designs, and to improve the relevance of our research for human stakeholders.
This is a preview of subscription content, log in via an institution to check access.
Access this article
Subscribe and save.
- Get 10 units per month
- Download Article/Chapter or Ebook
- 1 Unit = 1 Article or 1 Chapter
- Cancel anytime
Price includes VAT (Russian Federation)
Instant access to the full article PDF.
Rent this article via DeepDyve
Institutional subscriptions
Similar content being viewed by others

What is Qualitative in Qualitative Research

Research Methodology: An Introduction

The GenAI is out of the bottle: generative artificial intelligence from a business model innovation perspective
Cooperative and Human Aspects of Software Engineering, co-located with ICSE since 2008 http://www.chaseresearch.org/
We shorten this to “Humans” in the rest of the paper.
We recognize that most technical systems are studied or improved with the final goal to benefit a human stakeholder. However, we found in many papers that these human stakeholders are not discussed and that the research is aimed at understanding or improving the technical system.
By in silico , we mean performed on a computer or via computer simulation.
For example, one EMSE paper we read reported a user study but did not indicate how many participants were involved, nor who the participants were.
http://www.gousios.gr/blog/Scaling-qualitative-research.html
Visual Languages and Human-Centric Computing, http://conferences.computer.org/VLHCC/
ACM Conference on Computer Supported Cooperative Work https://cscw.acm.org
Stol and Fitzgerald interpret and extend this model quite differently to us as they are not concerned with using their framework to discriminate which strategies directly involve human actors. Runkel and McGrath developed their model to capture behavioral aspects and we maintain the behavioral aspect in our extension of their model.
Aranda J, Venolia G (2009) The secret life of bugs: Going past the errors and omissions in software repositories. In: Icse, pp 298–308. https://doi.org/10.1109/ICSE.2009.5070530
Baecker RM, Grudin J, Buxton WAS, Greenberg S (eds) (1995) Human-Computer interaction: Toward the Year, vol 2000. Morgan Kaufmann Publishers Inc., San Francisco
Google Scholar
Bird C, Rigby PC, Barr ET, Hamilton DJ, German DM, Devanbu P (2009) The promises and perils of mining git. In: Proceedings of the international working conference on mining software repositories. https://doi.org/10.1109/msr.2009.5069475
Brooks FP Jr (1995) The Mythical Man-month (Anniversary Ed.) Addison-wesley Longman Publishing Co., Inc., Boston
Colavizza G, Hrynaszkiewicz I, Staden I, Whitaker K, McGillivray B (2019) The citation advantage of linking publications to research data. Tech. Rep. arXiv: 1907.02565
Cruz A, Correia A, Paredes H, Fonseca B, Morgado L, Martins P (2012) Towards an overarching classification model of cscw and groupware: a socio-technical perspective. In: International conference on collaboration and technology, Springer, pp 41–56
DeMarco T, Lister T (1987) Peopleware: productive projects and teams. Dorset House Publishing Co., Inc., New York
Denzin NK (1973) The research act: A theoretical introduction to sociological methods. Transaction Publishers, New Jersey
Dittrich Y, John M, Singer J, Tessem B, (eds) (2007) Special issue on qualitative software engineering research. vol 49. https://www.sciencedirect.com/journal/information-and-software-technology/vol/49/issue/6
Dybå T, Prikladnicki R, Rönkkö K, Seaman C, Sillito J (eds) (2011) Special Issue on Qualitative Research in Software Engineering, vol 16. Springer, Berlin. https://link.springer.com/journal/10664/16/4
Easterbrook S, Singer J, Storey MA, Damian D (2008) Selecting empirical methods for software engineering research. Springer, London, pp 285–311. https://doi.org/10.1007/978-1-84800-044-5_11
Engström E, Storey MD, Runeson P, Höst M, Baldassarre MT (2019) A review of software engineering research from a design science perspective. arXiv: abs/1904.12742
Felderer M, Travassos GH (2019) The evolution of empirical methods in software engineering
Feldt R, Torkar R, Angelis L, Samuelsson M (2008) Towards individualized software engineering: empirical studies should collect psychometrics. In: Proceedings of the 2008 international workshop on Cooperative and human aspects of software engineering, ACM, pp 49–52
Guéhéneuc YG, Khomh F (2019) Empirical software engineering. In: Handbook of software engineering, Springer, pp 285–320
Hassan AE (2008) The road ahead for mining software repositories. In: 2008 Frontiers of software maintenance, pp 48–57. https://doi.org/10.1109/FOSM.2008.4659248
Kalliamvakou E, Gousios G, Blincoe K, Singer L, German DM, Damian D (2014) The promises and perils of mining GitHub. In: International working conference on mining software repositories. https://doi.org/10.1145/2597073.2597074
Kirk J, Miller ML (1986) Reliability and validity in qualitative research. Sage Publications. https://doi.org/10.4135/9781412985659
Kitchenham BA, Pfleeger SL (2008) Personal opinion surveys. Springer, London, pp 63–92. https://doi.org/10.1007/978-1-84800-044-5_3
Kontio J, Bragge J, Lehtola L (2008) The focus group method as an empirical tool in software engineering. Springer, London, pp 93–116. https://doi.org/10.1007/978-1-84800-044-5_4
Lanza M, Mocci A, Ponzanelli L (2016) The tragedy of defect prediction, prince of empirical software engineering research. IEEE Softw 33(6):102–105
Article Google Scholar
Lenberg P, Feldt R, Tengberg LGW, Tidefors I, Graziotin D (2017) Behavioral software engineering – guidelines for qualitative studies. arXiv: 1712.08341
Lenberg P, Feldt R, Wallgren LG (2014) Towards a behavioral software engineering In: Proceedings of the 7th international workshop on cooperative and human aspects of software engineering, pp 48–55
Lex A, Gehlenborg N, Strobelt H, Vuillemot R, Pfister H (2014) Upset: Visualization of intersecting sets. IEEE Trans Vis Comput Graph 20(12):1983–1992. https://doi.org/10.1109/tvcg.2014.2346248
McGrath JE (1995) Methodology matters: Doing research in the behavioral and social sciences. In: Baecker RM, Grudin J, Buxton W, Greenberg S (eds) Readings in Human-Computer Interaction: Toward the Year 2000. Morgan Kaufmann Publishers Inc, pp 152–169
Miles MB, Huberman AM, Saldana J (2013) Qualitative data analysis: a methods sourcebook. SAGE Publications Incorporated
Onwuegbuzie AJ, Leech NL (2007) Validity and qualitative research: an oxymoron? Quality & Quantity 41:233–249
Roller MR, Lavrakas PJ (2015) Applied Qualitative Research Design: A Total Quality Framework Approach. Guilford Press. https://www.amazon.com/Applied-Qualitative-Research-Design-Framework/dp/1462515754
Runeson P, Höst M (2008) Guidelines for conducting and reporting case study research in software engineering. Empir Softw Eng 14(2):131. https://doi.org/10.1007/s10664-008-9102-8
Runkel PJ, McGrath JE (1972) Research on human behavior. Holt, Rinehart, and Winston Inc
Seaman CB (1999) Qualitative methods in empirical studies of software engineering. IEEE Transactions on Software Engineering 25(4):557–572
Seaman CB (2008) Qualitative methods. Springer, London, pp 35–62. https://doi.org/10.1007/978-1-84800-044-5_2
Sharp H, Dittrich Y, de Souza CRB (2016) The role of ethnographic studies in empirical software engineering. IEEE Trans Softw Eng 42(8):786–804. https://doi.org/10.1109/TSE.2016.2519887
Shaw M (2003) Writing good software engineering research papers: Minitutorial. In: Proceedings of the 25th international conference on software engineering, ICSE ’03. IEEE Computer Society, Washington, pp 726–736
Shneiderman B (1980) Software psychology: human factors in computer and information systems (winthrop computer systems series). winthrop publishers
Singer J, Sim SE, Lethbridge TC (2008) Software engineering data collection for field studies. Springer, London, pp 9–34. https://doi.org/10.1007/978-1-84800-044-5_1
Singer J, Vinson NG (2002) Ethical issues in empirical studies of software engineering. IEEE Trans Softw Eng 28(12):1171–1180
Stol KJ, Fitzgerald B (2015) A holistic overview of software engineering research strategies. In: Proceedings of the Third international workshop on conducting empirical studies in industry, CESI ’15. IEEE Press, Piscataway, pp 47–54
Stol KJ, Fitzgerald B (2018) The abc of software engineering research. ACM Trans Softw Eng Methodol 27(3):11,1–11,51. https://doi.org/10.1145/3241743
Theisen C, Dunaiski M, Williams L, Visser W (2017) Writing good software engineering research papers: Revisited. In: 2017 IEEE/ACM 39Th international conference on software engineering companion (ICSE-c), pp 402–402. https://doi.org/10.1109/ICSE-C.2017.51
Weinberg GM (1985) The psychology of computer programming. Wiley, New York
Whitworth B (2009) The social requirements of technical systems. In: Whitworth B, de Moor A (eds) Handbook of research on socio-technical design and social networking systems. https://doi.org/10.4018/978-1-60566-264-0 . IGI Global, pp 2–22
Williams C (2019) Methodology matters: mapping software engineering research through a sociotechnical lens. Master’s thesis, University of Victoria. https://dspace.library.uvic.ca//handle/1828/9997
Zelkowitz MV (2007) Techniques for empirical validation. Springer, Berlin, pp 4–9
Barik T, Smith J, Lubick K, Holmes E, Feng J, Murphy-Hill E, Parnin C (2017) Do developers read compiler error messages?. In: Proceedings of the ACM/IEEE international conference on software engineering, IEEE. https://doi.org/10.1109/icse.2017.59
Bezemer CP, McIntosh S, Adams B, German DM, Hassan AE (2017) An empirical study of unspecified dependencies in make-based build systems. Empir Softw Eng 22(6):3117–3148. https://doi.org/10.1007/s10664-017-9510-8
Charpentier A, Falleri JR, Morandat F, Yahia EBH, Réveillère L (2017) Raters’ reliability in clone benchmarks construction. Empir Softw Eng 22(1):235–258. https://doi.org/10.1007/s10664-015-9419-z
Christakis M, Emmisberger P, Godefroid P, Müller P. (2017) A general framework for dynamic stub injection. In: Proceedings of the ACM/IEEE international conference on software engineering, pp 586–596. https://doi.org/10.1109/ICSE.2017.60
Faitelson D, Tyszberowicz S (2017) Uml diagram refinement (focusing on class- and use case diagrams). In: Proceedings of the ACM/IEEE international conference on software engineering, pp 735–745. https://doi.org/10.1109/ICSE.2017.73
Fernández DM, Wagner S, Kalinowski M, Felderer M, Mafra P, Vetrò A, Conte T, Christiansson MT, Greer D, Lassenius C, Männistö T, Nayabi M, Oivo M, Penzenstadler B, Pfahl D, Prikladnicki R, Ruhe G, Schekelmann A, Sen S, Spinola R, Tuzcu A, de la Vara JL, Wieringa R (2017) Naming the pain in requirements engineering. Empir Softw Eng 22(5):2298–2338. https://doi.org/10.1007/s10664-016-9451-7
Heikkilä VT, Paasivaara M, Lasssenius C, Damian D, Engblom C (2017) Managing the requirements flow from strategy to release in large-scale agile development: a case study at ericsson. Empir Softw Eng 22(6):2892–2936. https://doi.org/10.1007/s10664-016-9491-z
Hoda R, Noble J (2017) Becoming agile: a grounded theory of agile transitions in practice. In: Proceedings of the ACM/IEEE international conference on software engineering, IEEE. https://doi.org/10.1109/icse.2017.21
Jiang H, Li X, Yang Z, Xuan J (2017) What causes my test alarm? automatic cause analysis for test alarms in system and integration testing. In: 2017 IEEE/ACM 39Th international conference on software engineering (ICSE), IEEE. https://doi.org/10.1109/icse.2017.71
Joblin M, Apel S, Hunsen C, Mauerer W (2017) Classifying developers into core and peripheral: an empirical study on count and network metrics. In: Proceedings of the ACM/IEEE international conference on software engineering, pp 164–174. https://doi.org/10.1109/ICSE.2017.23
Kafali O, Jones J, Petruso M, Williams L, Singh MP (2017) How good is a security policy against real breaches? a HIPAA case study. In: Proceedings of the ACM/IEEE international conference on software engineering , IEEE. https://doi.org/10.1109/icse.2017.55
Kitchenham B, Madeyski L, Budgen D, Keung J, Brereton P, Charters S, Gibbs S, Pohthong A (2016) Robust statistical methods for empirical software engineering. Empir Softw Eng 22(2):579–630. https://doi.org/10.1007/s10664-016-9437-5
Lenberg P, Tengberg LGW, Feldt R (2016) An initial analysis of software engineers’ attitudes towards organizational change. Empir Softw Eng 22 (4):2179–2205. https://doi.org/10.1007/s10664-016-9482-0
Li M, Wang W, Wang P, Wang S, Wu D, Liu J, Xue R, Huo W (2017) Libd: Scalable and precise third-party library detection in android markets. In: Proceedings of the ACM/IEEE international conference on software engineering. https://doi.org/10.1109/icse.2017.38
Lin Y, Sun J, Xue Y, Liu Y, Dong J (2017) Feedback-based debugging. In: Proceedings of the ACM/IEEE international conference on software engineering. https://doi.org/10.1109/icse.2017.43
Mkaouer MW, Kessentini M, Cinnéide MÓ, Hayashi S, Deb K (2016) A robust multi-objective approach to balance severity and importance of refactoring opportunities. Empir Softw Eng 22(2):894–927. https://doi.org/10.1007/s10664-016-9426-8
Rojas JM, White TD, Clegg BS, Fraser G (2017) Code defenders: Crowdsourcing effective tests and subtle mutants with a mutation testing game. In: Proceedings of the ACM/IEEE international conference on software engineering. https://doi.org/10.1109/icse.2017.68
Stol KJ, Ralph P, Fitzgerald B (2016) Grounded theory in software engineering research: a critical review and guidelines. In: Proceedings of the ACM/IEEE international conference on software engineering, pp 120–131. https://doi.org/10.1145/2884781.2884833
Download references
Acknowledgements
We would like to thank Cassandra Petrachenko, Alexey Zagalsky and Soroush Yousefi for their invaluable help with this paper and research. We also thank Marian Petre and the anonymous reviewers for their insightful suggestions to improve our paper. We also acknowledge the support of the Natural Sciences and Engineering Research Council of Canada (NSERC).
Author information
Authors and affiliations.
University of Victoria, Victoria, Canada
Margaret-Anne Storey, Neil A. Ernst, Courtney Williams & Eirini Kalliamvakou
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Margaret-Anne Storey .
Additional information
Communicated by: Burak Turhan
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix A: The Circumplex of Runkel and McGrath
Figure 6 shows a sketch of the research strategy circumplex designed by Runkel and McGrath ( 1972 ) for categorizing behavioral research strategies. We adapted their model for the How part of our research framework. Runkel and McGrath’s model of research strategies was developed in the 1970s for categorizing human behavioral research, hence it provides a good model for examining socio-technical factors in software engineering.

Runkel and McGrath’s research strategy circumplex
The McGrath model has been used by other software engineering researchers to reflect on research strategy choice and its implications on research design (Easterbrook et al. 2008 ), and most recently by Stol and Fitzgerald ( 2018 ) as a way to to provide consistent terminology for research strategies (Stol and Fitzgerald 2018 ) Footnote 9 It is used in the field of Human Computer Interaction (Baecker et al. 1995 ) and CSCW (Cruz et al. 2012 ) to guide research design on human aspects.
Three of our quadrants (Respondent, Lab, Field) mirror three of the quadrants in Runkel and McGrath’s book (although we refer to Experimental Strategies as Lab Strategies as we find this less confusing). The fourth quadrant they suggest captures non-empirical research methods: they refer to this quadrant as Theoretical Strategies. We consider two types of non-empirical strategies in our framework: Meta (e.g., systematic literature review), and Formal Theory. We show these non empirical strategies separately to the four quadrants of empirical strategies in our framework. Our fourth quadrant includes Computer Simulations (which we consider empirical), but it also includes other types of data strategies that rely solely on previously collected data in addition to simulated data. We call this fourth quadrant in our framework “Data Strategies”.
One of the core contributions of the Runkel and McGrath research strategy model is to highlight the trade-offs inherent in choosing a research strategy and how each strategy has strengths and weaknesses in terms of achieving higher levels of generalizability, realism and control. Runkel and McGrath refer to these criteria as “quality criteria”, since achieving higher levels of these criteria is desirable. Generalizability captures how generalizable the findings may be to the population outside of the specific actors under study. Realism captures how closely the context under which evidence is gathered may match real life. Control refers to the control over the measurement of variables that may be relevant when human behaviors are studied. Field strategies typically exhibit low generalizability, but have higher potential for higher realism. Lab studies have high control over human variables, but lower realism. Respondent strategies show higher potential for generalizability, but lower realism and control over human variables.
We added a fourth research quality criterion to our model, data precision . Data strategies have higher potential for collecting precise measurements of system data over other strategies. Data studies may be reported as ‘controlled’ by some authors when they really mean precision over data collected, therefore, we reserve the term control in this paper for control over variables in the data generation process (e.g., applying a treatment to one of two groups and observing effects on a dependent variable). McGrath himself debated the distinction between precision and control in his later work. We note that McGrath’s observations were based on work in sociology and less likely to involve large data studies, unlike in software engineering. The Who-What-How framework (bottom of Fig. 1 ) denotes these criteria in italics outside the quadrants. The closer a quadrant to the criterion, the more the quadrant has the potential to maximize that criterion.
We recommend that the interested reader refer to Runkel and McGrath’s landmark book (Runkel and McGrath 1972 ) for additional insights on methodology choice that we could not include in our paper.
Appendix B: Sample Paper Classification
Table 3 shows a 15-paper sample classified using our Who-What-How framework. Full data is available at https://doi.org/10.5281/zenodo.3813878 .
Rights and permissions
Reprints and permissions
About this article
Storey, MA., Ernst, N.A., Williams, C. et al. The who, what, how of software engineering research: a socio-technical framework. Empir Software Eng 25 , 4097–4129 (2020). https://doi.org/10.1007/s10664-020-09858-z
Download citation
Published : 28 August 2020
Issue Date : September 2020
DOI : https://doi.org/10.1007/s10664-020-09858-z
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Empirical methods
- Human studies
- Software engineering
- Meta-research
- Find a journal
- Publish with us
- Track your research
Thank you for visiting nature.com. You are using a browser version with limited support for CSS. To obtain the best experience, we recommend you use a more up to date browser (or turn off compatibility mode in Internet Explorer). In the meantime, to ensure continued support, we are displaying the site without styles and JavaScript.
- View all journals
- Explore content
- About the journal
- Publish with us
- Sign up for alerts
- Published: 01 July 2024
Software in science is ubiquitous yet overlooked
- Alexandre Hocquet ORCID: orcid.org/0000-0001-6361-5780 1 , 2 ,
- Frédéric Wieber ORCID: orcid.org/0000-0001-7167-9813 1 ,
- Gabriele Gramelsberger 2 ,
- Konrad Hinsen ORCID: orcid.org/0000-0003-0330-9428 3 , 4 ,
- Markus Diesmann ORCID: orcid.org/0000-0002-2308-5727 5 ,
- Fernando Pasquini Santos ORCID: orcid.org/0000-0002-2259-7229 2 , 6 ,
- Catharina Landström 2 , 7 ,
- Benjamin Peters 2 , 8 ,
- Dawid Kasprowicz ORCID: orcid.org/0009-0005-6020-6865 2 ,
- Arianna Borrelli 2 , 9 ,
- Phillip Roth ORCID: orcid.org/0000-0001-5213-3348 2 ,
- Clarissa Ai Ling Lee ORCID: orcid.org/0000-0001-9705-5689 2 , 10 ,
- Alin Olteanu ORCID: orcid.org/0000-0002-4712-2529 2 &
- Stefan Böschen ORCID: orcid.org/0000-0003-0519-5030 2
Nature Computational Science ( 2024 ) Cite this article
1932 Accesses
13 Altmetric
Metrics details
- Computational science
- Interdisciplinary studies
Software is much more than just code. It is time to confront the complexity of licenses, uses, governance, infrastructure and other facets of software in science. Their influence is ubiquitous yet overlooked.
You have full access to this article via your institution.
In March 2020, Neil Ferguson, the scientist whose epidemiology model was used to justify COVID lockdown policies in the UK and around the world, was urged to make his model’s source code public. The model received some criticism on scientific grounds, but the most vocal objections targeted its software engineering aspects, calling it poorly designed, written and documented 1 . Such a culture clash is not surprising to some computational scientists, whose daily routine consists of designing, writing, maintaining, supporting, testing, debugging, adapting to new hardware, documenting, sharing, licensing and packaging a piece of software. Both computational researchers and software engineers are used to interacting with different temporalities, constraints, norms and work cultures.
In June 2020, in the wake of Ferguson’s controversies, colleagues across the sciences and humanities published a timely and relevant manifesto in Nature that proposes “five ways to ensure that models serve society” 2 . Yet the manifesto does not mention the concept of software in their consideration of models. We believe this is lacking because models and software are entangled in science, and software does critical work that models cannot perform on their own.
Software is indeed difficult to define, often being mistaken for code or algorithms. As historian of computing Thomas Haigh puts it : “Software always involves packaging disparate elements such as computer code, practices, algorithms, tacit knowledge, and intellectual property rights into an artifact suitable for dissemination”. Scientific software involves a diversity of practices regarding programming, governance, licensing, distribution, maintenance and support. It is developed and used across a myriad of scientific disciplines and programming traditions. It ranges in size from personal ‘scripts’ to huge projects involving entire communities and global infrastructure. It encompasses freely shared code as well as commercial packages.
In this Comment, we emphasize the complexity of scientific software as a multifaceted socio-technical (and historically grown) system. We describe facets of software that we define as vantage points from which the different dimensions of software can be understood. The multifaceted nature of software implies that the work done by software has technical, legal, sociological and epistemic consequences. Models and software are entangled in computational science, and much remains to be done to comprehend these consequences. We also point out the diversity of situations involving software in computational science, which further complicates how to approach software facets. We highlight a few case studies, with the hope that this starting conversation about software will be enriched by further input.
Engineering
Ferguson’s story reveals something important and widespread 1 about a culture clash between science and software engineering. Some software professionals may regard scientists as end-user programmers, yet scientists do not necessarily share the same norms, aims and practices as software engineers.
For example, given that validation and verification are often intertwined, test suites designed by scientists may focus more on the stability and reproducibility of simulation results than on the efficiency of the code or the structure of the program. In some scientific projects, risk-averse approaches oppose agile methods 3 . Software longevity may not be understood in the same way; whereas software engineers consider adaptation to new hardware, operating systems or platforms to be essential, backward compatibility, stability and replicability are more important for scientists.
Also, software engineers may tend to account for diverse potential users, whereas scientists sometimes devise software for the exclusive use of their close collaborators. Therefore, standards pertaining to portability or the user-friendliness of interface design may differ substantially. Tasks such as software maintenance or bug fixes might be idiosyncratic and have temporalities of their own.
To manage the unmanageable in increasing software complexity and in the labyrinth of available libraries, communities develop guidelines on how to use and improve scientific software in alignment with scientific research norms. In doing so, the field of research software engineering has emerged, aiming to bridge both cultures. The growing importance of research software engineering underlines the need to study the diversity of working cultures in scientific software. To this end, the FAIR (findable, accessible, interoperable and reusable) principles for research software 4 and similar initiatives should be assessed and compared to established practices in open source communities. Moreover, the issue of recognition or credit for engineering work in science is also pressing.
Governance — that is, the social structure of a software project — is an important facet of software that has more than one author. The way software development and maintenance are collectively organized affects the science that relies on it.
In the computational chemistry project Q-Chem , a professional workforce dedicated to development and maintenance is financed by software package sales. The project is thus commercial, centralized and proprietary, which is supposed to ensure its stability 5 . Open source would arguably be a better way forward for transparency, but it does not solve the problem of who is able to commit what (and themselves) to a project. The SciPy community consists of scientist-developers with diverse interests , both in terms of numerical techniques and scientific disciplines, and different computational needs. Even though the SciPy libraries are open source, development choices tied to hierarchies in governance or the representation of scientific disciplines in the community influence how practical their use can be in different communities. Forking can mitigate the diversity issue but is not always an effective solution, because it tends to fragment or even divide open source communities.
Users and funders are sometimes not aware of governance issues. To understand a software project, one should situate it within diverse types of social structure 6 . Moreover, governance should include both developer and user communities, because their perspectives and priorities often differ considerably.
Beyond governance, software is also concerned with the administration of its uses. Licenses are the contracts that software authors and users must abide by. Although definitely entangled with governance, licensing takes a legal rather than a social perspective, translating intellectual property rights into the world of software.
For example, licensing may differ for academic and industrial users. The MacroModel licensing policy distinguishes between discounted academic licenses that forbid tinkering with certain model parameters, and industrial licenses that do allow such tinkering. Some scientists have argued that academic licenses restrain scientific potentialities while the industrial ones raise reproducibility issues linked to uncertain versioning 7 .
Given that the license defines what the user is entitled to do, the actionability of a model embedded in a piece of software follows directly from licensing policies. Yet such end-user license agreements are notoriously seldom taken into account by users. Indeed, much scientific software lacks any licensing policy at all. Even within open source projects, license differences affect the possibilities for the reuse and combination of software 8 . For example, ‘Permissive’ licenses such as MIT, Apache or BSD differ from ‘copyleft’ licenses such as GPL or LGPL. Better literacy regarding licensing issues is desirable, as these issues illustrate a tension: scientific software is at once a valuable technical artifact subject to intellectual property, and an expression of models and methods whose scientific value comes from disclosure and sharing.
Circulation
According to Haigh 9 , software is only as useful as it is “suitable for dissemination”, but what this means depends on the context. As soon as exchange is envisioned for a computational project, software is what enables code to be packaged for traveling through space (that is, across different communities or userbases), time (because of maintenance and support), pieces of hardware (for instance, for portability), and software environments (for backwards compatibility).
For example, the history of the Gaussian computational chemistry package is a decades-long story of strategic changes. Gaussian began as a freely available source code, and eventually a company was founded to distribute and sell Gaussian as a software suite. The Gaussian story, however, is not merely one of software commodification. For Gaussian, maintaining control over official versions is key for the accountability and durability of the software project in the context of diverse hardware and portability initiatives. That is why the source code of Gaussian is provided, as a warrant for transparency, but many corporate actions forbid users to modify it, to avoid proliferation of uncontrolled and inconsistent versions of the program 7 . The history of distribution strategies of the Gaussian package over decades sheds light on different strategic choices regarding reproducibility. Nowadays, it is the evolution of software rather than hardware environments that needs to be taken into account.
Software environments can be stored and transferred, which is the role of container technologies such as Docker . These have become popular in scientific computing, alongside version control systems that permit source code changes to be tracked. The missing link between version control and executable containers is a record of the transformation process from source code to executable. This task is performed by compilers and related tools and orchestrated by package managers. However, some package managers do not keep track of the versions of compilation tools, which are subject to change as well. A different compiler can cause unpredictable changes in the results of calculations. Software management tools such as Nix or Guix ensure full provenance tracking, but their use is still far from widespread.
Infrastructure
Infrastructure studies have revealed issues of long-term development, scale and the interplay of technical and organizational structures, as well as tensions between what is planned and what emerges. Infrastructure constitutes a software facet of its own, especially when software projects involve or support entire communities 10 .
Nowadays, platforms as infrastructure are becoming increasingly detached from their hardware support. In science, this means that the portability of models to a variety of competing hardware is less of an issue than it was a few decades ago, whereas software infrastructure is nowadays more fragile, described by historian Paul Edwards as “flammable” 10 . Large scientific instruments such as telescopes are now well established elements of scientific infrastructure, and have corresponding funding models, but the same cannot yet be said for software, which has a similarly fundamental role.
For example, the field of computational neuroscience is striving to separate the formal specification of concrete neural network models from generic simulation engines, which can run a variety of models from different research groups. This kind of generic engine rests on software infrastructure suffering from distinctive long-term development and maintenance issues 11 . With many research groups depending on the continued usability of the shared engine, its maintenance must be governed and funded collegially and on a timescale extending far beyond that of a typical research grant 12 .
Budgets for software maintenance must be planned and approved as long-term investments, just like the budgets for traditional scientific infrastructure such as particle accelerators. For this to happen, science funding and policy actors need a better understanding of how software is made usable and for whom.
Embedded theory
In scientific models, software embeds theory, and different versions of a piece of software entail different versions of a model or its parameters, or even different underlying theoretical principles. In the context of in silico experiments in climate modeling 13 , changes in the software might imply changes in the models and theories they are based upon and, thus, correspond to different settings for such experiments. To ensure consistency, some climate researchers have adopted methods for comparative assessment of models and parameters that also include evaluation of the software.
Another example is the effort to standardize mathematical concepts in computational neuroscience. An analysis of connectivity patterns in neural network models implemented either in terms of predefined routines of a generic simulator or as custom code in a general-purpose programming language has unveiled a diversity of interpretations of its core connectivity concept that challenges reproducibility 14 .
The problem is not only one of theoretically diverse conceptions of connectivity, but also one of the implementation of any of these conceptions across different software frameworks such as MATLAB , NEURON or NEST . Using different pieces of software thus means using different connectivity theories. The way forward lies in developing standardized ontologies of the terms the community is using, backed up not only by mathematical definitions but also by reference software implementations.
Because users rarely form a homogeneous group, the potential diversity of uses accentuates the underlying complexity and diversity of software. As a medium, software constitutes an interface within and through which users operate. As such, software sets operational affordances that organize users’ interactions with models. For example, a command-line interface and the use of scripts may enhance reproducibility because invocations can be recorded 15 , whereas a graphical user-friendly interface might enhance usability. Beyond the command-line interface versus graphical user-friendly interface debate, users’ interactions with software must be understood as being bound to research cultures. For example, in protein crystallography, user interfaces shape the handling of models on the screen, but the interface design itself is influenced by a common understanding of molecules through physical ball-and-stick models 16 .
The diversity of application scenarios often transcends the scientific context itself. For instance, in water management, computer models are supposed to be used by water management professionals. Although such programs are nowadays published as open source code, they are less frequently used by professionals other than the scientists involved in their creation, as their design may be somewhat opaque to non-scientists. For a scientific computer model to become usable in water management, extensive development effort is required to transform it into a software package suited to a wider audience. This translation process of turning models into usable software is pivotal 17 .
Even within scientific communities, such as that of functional magnetic resonance imaging, the engagement and retention of users is challenged by competing software packages. Usability assessment is crucial because user experience choices presumably affect the scientific analysis itself 18 . Beyond code, reflexive studies about scientific software need a broader perspective to encompass the entire trajectory from the context of development to the context of application.
Our argument is that software influences models and their outputs, just as it shapes (and is shaped by) scientific practices. That software is multifaceted implies that the work software performs has not only technical or sociological but also epistemic consequences. Concerns about software robustness, maintenance and durability, reproducibility and actionability, dissemination and consistency, all have epistemic dimensions.
Some of the issues are currently being addressed. To name some initiatives, Software Heritage endeavors to preserve all available versions of scientific code; Software Carpentry promotes computational literacy; the Software Sustainability Institute and the Research Software Alliance work towards better recognition; the ReScience C journal aims at replicating results.
Nevertheless, more is needed. Coming back to the abovementioned manifesto about models and society 2 , it should now be clear that the entangled epistemic, social and technical dimensions of software give substance to the issues raised in said manifesto 2 .
The diversity of software practices implies that a form of interdisciplinarity is key to understanding software facets. We should gather perspectives from different academic (such as computational scientists as well as humanists and social scientists) and professional backgrounds (such as developers, users, maintainers, and so on) to reveal the tensions between different meanings of software.
In this spirit, more case studies in various scientific fields and epochs should help us to understand the entanglement of software and models within their diversity and different temporalities. We hope this will improve our comprehension of the situatedness of software and enrich the conversation we are calling for.
Thimbleby, H. Computer J. 67 , 1381–1404 (2024).
Article MathSciNet Google Scholar
Saltelli, A. et al. Nature 582 , 482–484 (2020).
Article Google Scholar
Kelly, D. J. Syst. Softw. 109 , 50–61 (2015).
Barker, M. et al. Sci. Data 9 , 622 (2022).
Hocquet, A. & Wieber, F. Eur. J. Phil. Sci. 11 , 38 (2021).
Schrape, J.-F. Convergence 25 , 409–427 (2017).
Hocquet, A. & Wieber, F. IEEE Ann. Hist. Comput. 39 , 40–58 (2017).
Google Scholar
Morin, A. et al. PLOS Computat. Biol. 8 , e1002598 (2012).
Haigh, T. Commun. ACM 56 , 31–34 (2013).
Edwards, P. N. Platforms are infrastructures on fire. In Your Computer is on Fire (eds Mullaney, T. S. et al.) 313–336 (MIT Press, 2021).
Einevoll, G. et al. Neuron 102 , 735–744 (2019).
Knowles, R. et al. Nat. Computat. Sci. 1 , 169–171 (2021).
Gramelsberger, G. et al. J. Adv. Model. Earth Syst. 12 , e2019MS001720 (2019).
Senk, J. et al. PLOS Computat. Biol. 18 , e1010086 (2022).
Baker, M. Nature 541 , 563–565 (2017).
Myers, N. Rendering Life Molecular: Models, Modelers, and Excitable Matter (Duke Univ. Press, 2015).
Landström, C. TATuP J. Technol. Assess. Theory Practice 32 , 36–42 (2023).
Pasquini, F. et al. in Proc. 18th Int. Joint Conf. Computer Vision, Imaging and Computer Graphics Theory and Applications (VISIGRAPP) Vol. 2, 63–72 (SCITEPRESS, 2023).
Download references
Acknowledgements
The joint research was funded by the Käte Hamburger Kolleg Cultures of Research for Advanced Study in the Humanities with funds from the German Federal Ministry of Education and Research.
Author information
Authors and affiliations.
Archives Poincaré, Université de Lorraine, Nancy, France
Alexandre Hocquet & Frédéric Wieber
Käte Hamburger Kolleg, Cultures of Research, RWTH, Aachen, Germany
Alexandre Hocquet, Gabriele Gramelsberger, Fernando Pasquini Santos, Catharina Landström, Benjamin Peters, Dawid Kasprowicz, Arianna Borrelli, Phillip Roth, Clarissa Ai Ling Lee, Alin Olteanu & Stefan Böschen
Centre de Biophysique Moléculaire, CNRS, Orléans, France
Konrad Hinsen
Synchrotron SOLEIL, Saint Aubin, France
Institute for Advanced Simulation (IAS-6), Forschungszentrum Jülich, Jülich, Germany
Markus Diesmann
Department of Computer Science, Calvin University, Grand Rapids, MI, USA
Fernando Pasquini Santos
Science, Technology and Society Division, Chalmers University of Technology, Gothenburg, Sweden
Catharina Landström
Department of Media Studies, The University of Tulsa, Tulsa, OK, USA
Benjamin Peters
History of Science Institute, TU Berlin, Berlin, Germany
Arianna Borrelli
Center for Interactive Media, Multimedia University, Cyberjaya, Selangor, Malaysia
Clarissa Ai Ling Lee
You can also search for this author in PubMed Google Scholar
Contributions
All authors contributed equally.
Corresponding author
Correspondence to Alexandre Hocquet .
Ethics declarations
Competing interests.
The authors declare no competing interests.
Peer review
Peer review information.
Nature Computational Science thanks Stefanie Betz and the other, anonymous, reviewer(s) for their contribution to the peer review of this work.
Rights and permissions
Reprints and permissions
About this article
Cite this article.
Hocquet, A., Wieber, F., Gramelsberger, G. et al. Software in science is ubiquitous yet overlooked. Nat Comput Sci (2024). https://doi.org/10.1038/s43588-024-00651-2
Download citation
Published : 01 July 2024
DOI : https://doi.org/10.1038/s43588-024-00651-2
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
Quick links
- Explore articles by subject
- Guide to authors
- Editorial policies
Sign up for the Nature Briefing: AI and Robotics newsletter — what matters in AI and robotics research, free to your inbox weekly.

Academia.edu no longer supports Internet Explorer.
To browse Academia.edu and the wider internet faster and more securely, please take a few seconds to upgrade your browser .
- We're Hiring!
- Help Center
Software Engineering
- Most Cited Papers
- Most Downloaded Papers
- Newest Papers
- Last »
- Computer Science Follow Following
- Empirical Software Engineering Follow Following
- Software Testing Follow Following
- Software Engineering education Follow Following
- Software Evolution Follow Following
- Agile Methods (Software Engineering) Follow Following
- Requirements Engineering Follow Following
- Software Maintenance Follow Following
- Software Architecture Follow Following
- Data Mining Follow Following
Enter the email address you signed up with and we'll email you a reset link.
- Academia.edu Journals
- We're Hiring!
- Help Center
- Find new research papers in:
- Health Sciences
- Earth Sciences
- Cognitive Science
- Mathematics
- Computer Science
- Academia ©2024
- Publications
- News and Events
- Education and Outreach
Software Engineering Institute
About the sei.
The Software Engineering Institute (SEI) at Carnegie Mellon University is a Federally Funded Research and Development Center (FFRDC)—a nonprofit, public–private partnership that conducts research for the United States government. One of only 10 FFRDCs sponsored by the U.S. Department of Defense (DoD), the SEI conducts R&D in software engineering, systems engineering, cybersecurity, and many other areas of computing, working to introduce private-sector innovations into government.
We work with partners throughout the U.S. government, the private sector, and academia. These partnerships enable us to take innovations from concept to practice, closing the gap between research and use.
We establish and advance software as a strategic advantage for national security. We lead and direct research and transition of software engineering and related disciplines at the intersection of academia, industry, and government.
Bringing Innovation to Government
The SEI is the only FFRDC sponsored by the DoD that can work with organizations outside of the DoD. This enables us to introduce innovation to a broad swath of government agencies, as well as to collaborate with Carnegie Mellon University and academia at large. We support government initiatives by conducting research and development that is objective, long-term, and free from the constraints of commercialism.
How We Work With Government
As an FFRDC, we fulfill core DoD software engineering needs that are unmet by in-house and private sector R&D centers. For example, the U.S. Army and the SEI engaged in a multiyear partnership to improve the Army's capability to acquire software-reliant systems. Our engineers stepped in to help a prototyping team accelerate its use of Agile methods in an acquisition for a critical U.S. Air Force intelligence system. We also collaborated with the Department of Transportation and US-CERT on research aimed at securing the U.S. government's fleet of vehicles. By charter, we offer fast-track contracting for DoD and other federal organizations. We stay close to our sponsor in Washington, DC, with offices in Arlington, Virginia, in addition to our headquarters in Pittsburgh, Pennsylvania.
Are You part of a Government Agency? Initiate a New Project with Us
Part of the Carnegie Mellon University Community
The SEI is based at Carnegie Mellon University in Pittsburgh, Pennsylvania. A national and international leader in higher education and research, Carnegie Mellon University is at the forefront of cybersecurity and software initiatives. The university provides the SEI with infrastructure and business processes while our technical staff are part of the university's world-class community of researchers and innovators.
We work with Carnegie Mellon University on major initiatives, contributing to the university's intellectual capital through research, collaboration, teaching, and strong management practices.
Learn More about our collaboration with CMU
- Past Presentations

International Conference on Software and Systems Processes 2022
Jointly held with the international conference on global software engineering (icgse).
May 19-20, 2022 | Virtual
Call for Papers
ICSSP 2022 aims to bring together researchers and practitioners to share their research findings, experiences, and new ideas on diverse topics related to software and system processes and global software engineering. For 2022, the theme of the joint conference is: “Envisioning the Future of Software Engineering Process & Practice for Global Competitiveness and Innovation.” The goal is to advance both the state of the research and the state of the practice by applying innovative ideas from different fields of research to the future of software engineering process and globally distributed software development. Download the Call for Papers and the Industry Call for Papers .
Thank you for your interest in submitting a paper; the call for papers is now closed.
Submissions
Submissions are invited for unpublished original work in the following categories:
- Full Papers (10 pages + up to 2 pages with references) that reflect completed and evaluated research on novel approaches to major software and systems engineering process challenges, especially relating to the Future of Software Engineering Process & Practice for Global Competitiveness and Innovation. Enhanced versions of the best research papers will be included in a special issue of the Journal of Software: Evolution and Process.
- Short papers (5 pages including references) that present concise research results, describe work-in-progress (e.g. Ph. D. research), or conceptual and position papers addressing new perspectives, open questions and future directions. Short papers can also be industrial papers, for instance, describing practical challenges or research needs motivated by experience.
- Experience reports – by industry. Experience Reports provide the opportunity for you to share your practical experience through a paper and accompanying talk at the conference. An experience report is a reflection of your own industry experiences (e.g. challenges you have seen, what you tried and approaches you have taken, what worked and what didn’t work). In a specific call, we will invite submissions of an abstract in which you briefly explain your own, unpublished experience related to one or more topics of the conference. If your proposal is accepted, you will then be shepherded as you write your report. Experience reports are short papers (maximum 5 pages) that will be published in the conference proceedings. (See Industry Call for Papers .)
- Industry talk – by industry. Industry track submissions are expected to have a strong focus on the real-world application of techniques, tools, methodologies, processes, and practices. Submissions should clearly identify the problem that is addressed, the industrial context, and the outcomes, as well as the expected learning for the audience. (See Industry Call for Papers .)
- Journal first – original works published only on Journal but never presented in a conference. Specific Call To Be Announced
Topics of Interest
Submissions must be related to software and systems processes and/or global software engineering and we are especially interested in, but not limited to, papers addressing the topics in the following list:
Work from Anywhere (WFX) Emerging processes supporting remote work Infrastructure for WFX Hiring and Economics of WFX
Education and Training Software process management (SPM) education Global and Distributed SE curricula Lessons learned on SPM or GSE courses
Future and Innovation Related to Software Process and Collaboration Process for Embedded and IoT Systems ALM/PLM for distributed teams Software Processes for Augmented, virtual, and extended reality (AR/VR/ XR) Use of AR/VR/XR in Distributed Settings Software Process for low-code development practices Quantum programming and software engineering Software process for Blockchain Blockchain to improve/enhance Global Software Development Software Developer’s Experience (DX) Software Developers’ Relationship (DevRel) Process and Infrastructure for Software Applications in Scientific Research
Submission Requirements and Policies
All submissions must conform to the ICSSP (and ICGSE) 2022 formatting and submission instructions and must not exceed the given page limits for the applicable type of submission. All submissions must be in English. Page limits include all text, figures, tables, references, and appendices. Only research papers are permitted up to two more pages containing only references . The page limit is strict, and purchase of additional pages in the proceedings is not allowed at any point in the process (including after the paper is accepted). All submissions must be in PDF.
Formatting – Submissions must conform to the ACM template Formatting instructions are available at https://www.acm.org/publications/proceedings-template for both LaTeX and Word users. LaTeX users must use the provided acmart.cls and ACM-Reference-Format.bst without modification, enable the conference format in the preamble of the document (i.e., \documentclass[sigconf,review]{acmart}), and use the ACM reference format for the bibliography (i.e., \bibliographystyle{ACM-Reference-Format}). The review option adds line numbers, thereby allowing referees to refer to specific lines in their comments. In addition, a selection of the best papers from the ICSSP 2022 conference will appear in a special issue of the Journal of Software Evolution and Process.
Authorship policy – By submitting to ICSSP (and ICGSE) 2022, authors acknowledge that they conform to the authorship policy of the ACM . Note in particular that submitted papers must reflect the original work of the authors, the authors must be entitled to publish the work, the work must not have been published previously in a refereed or formally reviewed publication, and the work must not be in press elsewhere while under review for ICSSP 2022, among other provisions.
Plagiarism policy – By submitting to ICSSP 2022, authors also acknowledge that they are aware of and agree to be bound by the ACM Policy and Procedures on Plagiarism . In particular, papers submitted to ICSSP and ICGSE 2022 must not have been published elsewhere and must not be under review or submitted for review elsewhere whilst under consideration for ICSSP or ICGSE 2022. Contravention of this concurrent submission policy will be deemed a serious breach of scientific ethics, and appropriate action will be taken in all such cases. To check for double submission and plagiarism issues, the chairs reserve the right to (1) share the list of submissions with the PC Chairs of other conferences with overlapping review periods and (2) use external plagiarism detection software, under contract to the ACM, to detect violations of these policies.
Submission site – Submissions must be made through the ICSSP (and ICGSE) 2022 submission site on EasyChair no later than the applicable submission deadline. Be sure to direct your submissions correctly and select the appropriate submission type when uploading your submission. We encourage authors to upload their paper info early (and can submit the PDF later, but still before or on the date of the submission deadline AoE) to support the management of the review process.
Any submission that does not comply with these requirements may be desk rejected by the PC Co-Chairs without further review.
Notice: The official publication date is the first day of the conference. The official publication date affects the deadline for any patent filings related to published work.
Proceedings – The proceedings will be published by ACM, and will appear in the ACM digital library. The proceedings will only contain papers that have been presented at ICSSP 2022 and for which at least one author has registered.
Reviewing – All submissions will be peer-reviewed by the ICSSP or ICGSE 2022 program committee members. When submitting, you will have the option to choose if you are submitting to ICSSP or to ICGSE as a track. Each submitted research paper will receive reviews from at least three members of the specific program committee.
ICSSP 2022 does not employ double-blind review process .
Requirement to Register, Attend, and Present – Upon notification of acceptance, authors of accepted papers will be asked to complete a copyright form and will receive further instructions for preparing their camera-ready versions. At least one author of each accepted paper is expected to register for and attend the ICSSP 2022 and present the work. The organizers have the right to pull papers out of the proceedings if there is no associated registration by two weeks past the authors’ registration deadline. All accepted contributions with at least one registered author will be published in the conference electronic proceedings and appear in the ACM digital library.
Open Science Policy – ICSSP (and ICGSE) 2022 encourage authors to submit artifact packages and/or data sets with their papers, for the sake of transparency, reusability, replicability, and/or reproducibility, as well as for facilitating the peer review process. The following guidelines are recommendations and are not mandatory. Your choice will not affect the review process for your paper. Should you decide to embrace this policy, we strongly encourage you to archive empirical datasets on Zenodo or Dataverse , following Google guidelines to dataset providers , and share analysis scripts on freely accessible code repositories such as GitHub, GitLab, and Bitbucket.
Self-Archiving – ICSSP and ICGSE 2022 also encourage authors to self-archive a preprint of your accepted manuscript in arXiv.org or other similar open repositories. This is permitted by the ACM publisher. Note that the final version of the paper, as laid out by the publisher, cannot be self-archived. Instead, manuscripts with reviewer comments addressed must be used, but before applying the camera-ready instructions and templates.
Contact – Feel free to contact the ICSSP and ICGSE 2022 Program Co-Chairs for more details.
- Corpus ID: 270924426
ResearchBot: Bridging the Gap between Academic Research and Practical Programming Communities
- Sahar Farzanehpour , Swetha Rajeev , +2 authors Chris Brown
- Published 2 July 2024
- Computer Science
Figures and Tables from this paper

6 References
On automated assistants for software development: the role of llms, the sciqa scientific question answering benchmark for scholarly knowledge, evidence-based software engineering, related papers.
Showing 1 through 3 of 0 Related Papers
Software Engineering Research Topics

- Università degli Studi di Genova
Discover the world's research
- 25+ million members
- 160+ million publication pages
- 2.3+ billion citations
- Recruit researchers
- Join for free
- Login Email Tip: Most researchers use their institutional email address as their ResearchGate login Password Forgot password? Keep me logged in Log in or Continue with Google Welcome back! Please log in. Email · Hint Tip: Most researchers use their institutional email address as their ResearchGate login Password Forgot password? Keep me logged in Log in or Continue with Google No account? Sign up
IEEE Account
- Change Username/Password
- Update Address
Purchase Details
- Payment Options
- Order History
- View Purchased Documents
Profile Information
- Communications Preferences
- Profession and Education
- Technical Interests
- US & Canada: +1 800 678 4333
- Worldwide: +1 732 981 0060
- Contact & Support
- About IEEE Xplore
- Accessibility
- Terms of Use
- Nondiscrimination Policy
- Privacy & Opting Out of Cookies
A not-for-profit organization, IEEE is the world's largest technical professional organization dedicated to advancing technology for the benefit of humanity. © Copyright 2024 IEEE - All rights reserved. Use of this web site signifies your agreement to the terms and conditions.
Help | Advanced Search
Computer Science > Software Engineering
Title: reproducibility in machine learning-based research: overview, barriers and drivers.
Abstract: Research in various fields is currently experiencing challenges regarding the reproducibility of results. This problem is also prevalent in machine learning (ML) research. The issue arises, for example, due to unpublished data and/or source code and the sensitivity of ML training conditions. Although different solutions have been proposed to address this issue, such as using ML platforms, the level of reproducibility in ML-driven research remains unsatisfactory. Therefore, in this article, we discuss the reproducibility of ML-driven research with three main aims: (i) identifying the barriers to reproducibility when applying ML in research as well as categorize the barriers to different types of reproducibility (description, code, data, and experiment reproducibility), (ii) discussing potential drivers such as tools, practices, and interventions that support ML reproducibility, as well as distinguish between technology-driven drivers, procedural drivers, and drivers related to awareness and education, and (iii) mapping the drivers to the barriers. With this work, we hope to provide insights and to contribute to the decision-making process regarding the adoption of different solutions to support ML reproducibility.
| Comments: | Pre-print of submission for the AI Magazine - comments to this pre-print are very welcome |
| Subjects: | Software Engineering (cs.SE); Information Retrieval (cs.IR); Machine Learning (cs.LG) |
| Cite as: | [cs.SE] |
| (or [cs.SE] for this version) | |
| Focus to learn more arXiv-issued DOI via DataCite |
Submission history
Access paper:.
- HTML (experimental)
- Other Formats
References & Citations
- Google Scholar
- Semantic Scholar
BibTeX formatted citation
Bibliographic and Citation Tools
Code, data and media associated with this article, recommenders and search tools.
- Institution
arXivLabs: experimental projects with community collaborators
arXivLabs is a framework that allows collaborators to develop and share new arXiv features directly on our website.
Both individuals and organizations that work with arXivLabs have embraced and accepted our values of openness, community, excellence, and user data privacy. arXiv is committed to these values and only works with partners that adhere to them.
Have an idea for a project that will add value for arXiv's community? Learn more about arXivLabs .
IMAGES
VIDEO
COMMENTS
They wanted to define values and basic principles for better software development. On top of being brought into focus, the ... Philipp Hohl, Jil Klünder, Arie van Bennekum, Ryan Lockard, James Gifford, Jürgen Münch, Michael Stupperich and Kurt Schneider. Journal of Software Engineering Research and Development 2018 6 :15.
For this theme issue on the 50th anniversary of software engineering (SE), Redirections offers an overview of the twists, turns, and numerous redirections seen over the years in the SE research literature. Nearly a dozen topics have dominated the past few decades of SE research—and these have been redirected many times. Some are gaining popularity, whereas others are becoming increasingly ...
The Journal of Systems and Software publishes papers covering all aspects of software engineering. All articles should provide evidence to support …. View full aims & scope. $3710. Article publishing charge. for open access. 252 days. Submission to acceptance. 8 days.
End To End . Predictive Software. The paper examines the principles of the Predictive Software Engineering (PSE) framework. The authors examine how PSE enables custom software development companies to offer transparent services and products while staying within the intended budget and a guaranteed budget.
A curated list of papers that may be of interest to Software Engineering students or professionals. See the sources and selection criteria below. List of papers by topic. Von Neumann's First Computer Program. Knuth (1970). Computer History; Early Programming. The Education of a Computer. Hopper (1952). Recursive Programming.
Software Engineering. At Google, we pride ourselves on our ability to develop and launch new products and features at a very fast pace. This is made possible in part by our world-class engineers, but our approach to software development enables us to balance speed and quality, and is integral to our success. Our obsession for speed and scale is ...
Journal of Software: Evolution and Process is a computer science and software engineering journal that enables the software community to communicate new ideas for developing, managing and improving software, systems and services. We publish original research, empirical studies, surveys and more covering topics including software testing, continuous improvement of software processes and ...
In software engineering, research papers are customary vehicles for reporting results to the research community. In a research paper, the author explains to an interested reader what he or she accomplished, and how the author accomplished it, and why the reader should care. A good research paper should answer a number of questions:
Overview. Empirical Software Engineering serves as a vital forum for applied software engineering research with a strong empirical focus. A platform for empirical results relevant to both researchers and practitioners. Features industrial experience reports detailing the application of software technologies. Addresses the gap between research ...
View a PDF of the paper titled Generative Artificial Intelligence for Software Engineering -- A Research Agenda, by Anh Nguyen-Duc and 14 other authors View PDF Abstract: Generative Artificial Intelligence (GenAI) tools have become increasingly prevalent in software development, offering assistance to various managerial and technical project ...
The review canvasses work appearing in the most prominent SE and DL conferences and journals and spans 128 papers across 23 unique SE tasks. ... Paul Ralph, and Brian Fitzgerald. 2016. Grounded theory in software engineering research: A critical review and guidelines. In Proceedings of the 38th International Conference on Software Engineering ...
We introduce the General Index of Software Engineering Papers, a dataset of fulltext-indexed papers from the most prominent scientific venues in the field of Software Engineering. The dataset includes both complete bibliographic information and indexed ngrams (sequence of contiguous words after removal of stopwords and non-words, for a total of 577 276 382 unique n-grams in this release) with ...
With the goal of helping software engineering researchers understand how to improve their papers, Mary Shaw presented "Writing Good Software Engineering Research Papers" in 2003. Shaw analyzed the abstracts of the papers submitted to the 2002 International Conference of Software Engineering (ICSE) to determine trends in research question type, contribution type, and validation approach. We ...
This paper presents a software-aided method for assessment and trend analysis, which can be used in software engineering as well as other research fields in computer science (or other disciplines). The method proposed in this paper is modular and automated compared with the method in prior studies [7, 10-22, 2].
This paper provides a survey of the emerging area of Large Language Models (LLMs) for Software Engineering (SE). It also sets out open research challenges for the application of LLMs to technical problems faced by software engineers. LLMs' emergent properties bring novelty and creativity with applications right across the spectrum of Software Engineering activities including coding, design ...
Dutta R Costa D Shihab E Tajmel T Hoda R Serebrenik A (2023) Diversity Awareness in Software Engineering Participant Research Proceedings of the 45th International Conference on Software Engineering: Software Engineering in Society 10.1109/ICSE-SEIS58686.2023.00017 (120-131) Online publication date: 17-May-2023
1 Introduction. Design science is a paradigm for conducting and communicating applied re-. paradigm may be a viable way to presen t research contributions in existing. search contributions comm ...
Software engineering is a socio-technical endeavor, and while many of our contributions focus on technical aspects, human stakeholders such as software developers are directly affected by and can benefit from our research and tool innovations. In this paper, we question how much of our research addresses human and social issues, and explore how much we study human and social aspects in our ...
The growing importance of research software engineering underlines the need to study the diversity of working cultures in scientific software. To this end, the FAIR (findable, ...
Formal Specification and Documentation using Z: A Case Study Approach (slides and exercises) Online material for a Z course based on the book by the author. This includes slides for some chapters and the exercises. Updated in July 1998 with minor corrections and improved formatting. Download.
The design of software has been a focus of software engineering research since the field's beginning. This paper explores key aspects of this research focus and shows why design will remain a principal focus. The intrinsic elements of software design, both process and product, are discussed: concept formation, use of experience, and means for representation, reasoning, and directing the design ...
One of only 10 FFRDCs sponsored by the U.S. Department of Defense (DoD), the SEI conducts R&D in software engineering, systems engineering, cybersecurity, and many other areas of computing, working to introduce private-sector innovations into government. We work with partners throughout the U.S. government, the private sector, and academia.
Full Papers (10 pages + up to 2 pages with references) that reflect completed and evaluated research on novel approaches to major software and systems engineering process challenges, especially relating to the Future of Software Engineering Process & Practice for Global Competitiveness and Innovation. Enhanced versions of the best research ...
The core objective of ResearchBot is to democratize access to academic knowledge for industry professionals, by providing concise summaries of cutting-edge research directly in response to SE-related questions and facilitates the application of academic insights to practical contexts. Software developers commonly rely on platforms like Stack Overflow for problem-solving and learning.
5) Software Testing. 6) Software Measurement. 7) Software Product Lines. 8) Software Architecture. 9) software verification. 10) software business. 11) Software Refactoring. 12) software design ...
This paper provides a definition of the term "software engineering" and a survey of the current state of the art and likely future trends in the field. The survey covers the technology available in the various phases of the software life cycle—requirements engineering, design, coding, test, and maintenance—and in the overall area of software management and integrated technology-management ...
Software engineering researchers solve problems of several different kinds. To do so, they produce several different kinds of results, and they should develop appropriate evidence to validate these results. They often report their research in conference papers. I analyzed the abstracts of research papers submitted to XSE 2002 in order to identify the types of research reported in the submitted ...
Research in various fields is currently experiencing challenges regarding the reproducibility of results. This problem is also prevalent in machine learning (ML) research. The issue arises, for example, due to unpublished data and/or source code and the sensitivity of ML training conditions. Although different solutions have been proposed to address this issue, such as using ML platforms, the ...