More From Forbes
4 social experiments that will improve your career.
- Share to Facebook
- Share to Twitter
- Share to Linkedin
From a young age, I’ve been fascinated with how people meet and form relationships. While researching and writing The 2 AM Principle , I tested many famous theories and studies about human behavior.
These mini experiments and games provided essential insights for my career. Whether you are an entrepreneur trying to grow your business or someone trying to get ahead in their career, these experiments can help you understand your leadership style, make connections, and build confidence.

1. The Rejection Game
Human beings are overwhelmingly concerned with rejection. The fear of not being accepted stops us from taking many actions for our benefit. Yet, being turned down is never as bad as we think. The Rejection Game helps us realize this and overcome our fear.
It works like this: Go up to complete strangers and ask them for something that would seem worthy of a rejection. The request can be anything that puts you out of your comfort zone, but here are some examples to get started:
- Ask a random woman or man for their number.
- At a restaurant, ask a group if you can join them for dinner.
- Ask a stranger to run a race with you.
- Ask strangers to do the “Running Man”, “Nae/Nae” or some other dance fad with you.
- Ask someone at the gym to teach you their workout routine.
Will a percentage of people say no to you? Without a doubt, but it won’t be nearly as many as you think. You will realize how hard it is to get rejected, second you will toughen up and won’t fear rejection as much.
Social experiments can help boost your confidence and career.
2. The Favor Game
The favor game is similar to the rejection game. You ask people to perform favors for you but not for the sake of rejection. Instead, you ask for favors to understand how far strangers or acquaintances will go to support you. It is based on a concept popularized by Ben Franklin. To win over an adversary, Franklin asked for a favor: to borrow a rare book. The two men ended up becoming lifelong friends.
According to the Ben Franklin effect, we like people more when we do them favors because we have invested our time and given them support.
The key is to stack favors from small to large. If you ask people for directions, ask them for the time first. People will go surprisingly far to be helpful. They may lend you their car, help you move, lend you money and so on.
You will discover how much your community is willing to support and be there for you. If you discover that people aren’t willing to do favors for you, then your requests may be too large. Another possibility is that you haven't been a good friend or you’re spending time with the wrong people.
3. The “E” Test
As an indicator of leadership and perspective, Professors Adam Galinsky and Maurice Schweitzer , developed the “E” test. In it, a person is asked to trace the letter “E” on his or her forehead. Did you write the “E” so that other people could read it? According to Galinsky and Schweitzer, you are focused on others, which suggests that you consider the perspectives of those around you.
If you wrote it so that it can be read from your viewpoint, then you are self-focused, which is common in those in powerful positions. It is suggested that those who are focused on others may not have what it takes to be a ruthless leader, but it isn’t definite.
4. The Cash Register Experiment
In his book Give and Take , Wharton professor Adam Grant proposes that we assume other people are like ourselves. If you want to know how honest you or someone else is, ask a simple question: How much does the average store employee steal from their cash register?
Did you pick a big number or a small number? The higher the number, the less likely a person is to be honest. Once again, this experiment is suggestive but not definitive.
I have found these experiments and games invaluable. These insights have led me to invite a duty-free cashier in the Stockholm Airport to quit her job and travel the world with me after 10 seconds of meeting and befriend Kiefer Sutherland over a battle of Jenga. However, the greatest impact by far was on my confidence and ability to stay calm in any situation.

- Editorial Standards
- Reprints & Permissions
Social Psychology Experiments: 10 Of The Most Famous Studies
Ten of the most influential social psychology experiments explain why we sometimes do dumb or irrational things.

Ten of the most influential social psychology experiments explain why we sometimes do dumb or irrational things.
“I have been primarily interested in how and why ordinary people do unusual things, things that seem alien to their natures. Why do good people sometimes act evil? Why do smart people sometimes do dumb or irrational things?” –Philip Zimbardo
Like famous social psychologist Professor Philip Zimbardo (author of The Lucifer Effect: Understanding How Good People Turn Evil ), I’m also obsessed with why we do dumb or irrational things.
The answer quite often is because of other people — something social psychologists have comprehensively shown.
Each of the 10 brilliant social psychology experiments below tells a unique, insightful story relevant to all our lives, every day.
Click the link in each social psychology experiment to get the full description and explanation of each phenomenon.
1. Social Psychology Experiments: The Halo Effect
The halo effect is a finding from a famous social psychology experiment.
It is the idea that global evaluations about a person (e.g. she is likeable) bleed over into judgements about their specific traits (e.g. she is intelligent).
It is sometimes called the “what is beautiful is good” principle, or the “physical attractiveness stereotype”.
It is called the halo effect because a halo was often used in religious art to show that a person is good.
2. Cognitive Dissonance
Cognitive dissonance is the mental discomfort people feel when trying to hold two conflicting beliefs in their mind.
People resolve this discomfort by changing their thoughts to align with one of conflicting beliefs and rejecting the other.
The study provides a central insight into the stories we tell ourselves about why we think and behave the way we do.
3. Robbers Cave Experiment: How Group Conflicts Develop
The Robbers Cave experiment was a famous social psychology experiment on how prejudice and conflict emerged between two group of boys.
It shows how groups naturally develop their own cultures, status structures and boundaries — and then come into conflict with each other.
For example, each country has its own culture, its government, legal system and it draws boundaries to differentiate itself from neighbouring countries.
One of the reasons the became so famous is that it appeared to show how groups could be reconciled, how peace could flourish.
The key was the focus on superordinate goals, those stretching beyond the boundaries of the group itself.
4. Social Psychology Experiments: The Stanford Prison Experiment
The Stanford prison experiment was run to find out how people would react to being made a prisoner or prison guard.
The psychologist Philip Zimbardo, who led the Stanford prison experiment, thought ordinary, healthy people would come to behave cruelly, like prison guards, if they were put in that situation, even if it was against their personality.
It has since become a classic social psychology experiment, studied by generations of students and recently coming under a lot of criticism.
5. The Milgram Social Psychology Experiment
The Milgram experiment , led by the well-known psychologist Stanley Milgram in the 1960s, aimed to test people’s obedience to authority.
The results of Milgram’s social psychology experiment, sometimes known as the Milgram obedience study, continue to be both thought-provoking and controversial.
The Milgram experiment discovered people are much more obedient than you might imagine.
Fully 63 percent of the participants continued administering what appeared like electric shocks to another person while they screamed in agony, begged to stop and eventually fell silent — just because they were told to.
6. The False Consensus Effect
The false consensus effect is a famous social psychological finding that people tend to assume that others agree with them.
It could apply to opinions, values, beliefs or behaviours, but people assume others think and act in the same way as they do.
It is hard for many people to believe the false consensus effect exists because they quite naturally believe they are good ‘intuitive psychologists’, thinking it is relatively easy to predict other people’s attitudes and behaviours.
In reality, people show a number of predictable biases, such as the false consensus effect, when estimating other people’s behaviour and its causes.
7. Social Psychology Experiments: Social Identity Theory
Social identity theory helps to explain why people’s behaviour in groups is fascinating and sometimes disturbing.
People gain part of their self from the groups they belong to and that is at the heart of social identity theory.
The famous theory explains why as soon as humans are bunched together in groups we start to do odd things: copy other members of our group, favour members of own group over others, look for a leader to worship and fight other groups.
8. Negotiation: 2 Psychological Strategies That Matter Most
Negotiation is one of those activities we often engage in without quite realising it.
Negotiation doesn’t just happen in the boardroom, or when we ask our boss for a raise or down at the market, it happens every time we want to reach an agreement with someone.
In a classic, award-winning series of social psychology experiments, Morgan Deutsch and Robert Krauss investigated two central factors in negotiation: how we communicate with each other and how we use threats.
9. Bystander Effect And The Diffusion Of Responsibility
The bystander effect in social psychology is the surprising finding that the mere presence of other people inhibits our own helping behaviours in an emergency.
The bystander effect social psychology experiments are mentioned in every psychology textbook and often dubbed ‘seminal’.
This famous social psychology experiment on the bystander effect was inspired by the highly publicised murder of Kitty Genovese in 1964.
It found that in some circumstances, the presence of others inhibits people’s helping behaviours — partly because of a phenomenon called diffusion of responsibility.
10. Asch Conformity Experiment: The Power Of Social Pressure
The Asch conformity experiments — some of the most famous every done — were a series of social psychology experiments carried out by noted psychologist Solomon Asch.
The Asch conformity experiment reveals how strongly a person’s opinions are affected by people around them.
In fact, the Asch conformity experiment shows that many of us will deny our own senses just to conform with others.
Author: Dr Jeremy Dean
Psychologist, Jeremy Dean, PhD is the founder and author of PsyBlog. He holds a doctorate in psychology from University College London and two other advanced degrees in psychology. He has been writing about scientific research on PsyBlog since 2004. View all posts by Dr Jeremy Dean

Join the free PsyBlog mailing list. No spam, ever.
The Science of Improving Motivation at Work

The topic of employee motivation can be quite daunting for managers, leaders, and human resources professionals.
Organizations that provide their members with meaningful, engaging work not only contribute to the growth of their bottom line, but also create a sense of vitality and fulfillment that echoes across their organizational cultures and their employees’ personal lives.
“An organization’s ability to learn, and translate that learning into action rapidly, is the ultimate competitive advantage.”
In the context of work, an understanding of motivation can be applied to improve employee productivity and satisfaction; help set individual and organizational goals; put stress in perspective; and structure jobs so that they offer optimal levels of challenge, control, variety, and collaboration.
This article demystifies motivation in the workplace and presents recent findings in organizational behavior that have been found to contribute positively to practices of improving motivation and work life.
Before you continue, we thought you might like to download our three Goal Achievement Exercises for free . These detailed, science-based exercises will help you or your clients create actionable goals and master techniques to create lasting behavior change.
This Article Contains:
Motivation in the workplace, motivation theories in organizational behavior, employee motivation strategies, motivation and job performance, leadership and motivation, motivation and good business, a take-home message.
Motivation in the workplace has been traditionally understood in terms of extrinsic rewards in the form of compensation, benefits, perks, awards, or career progression.
With today’s rapidly evolving knowledge economy, motivation requires more than a stick-and-carrot approach. Research shows that innovation and creativity, crucial to generating new ideas and greater productivity, are often stifled when extrinsic rewards are introduced.
Daniel Pink (2011) explains the tricky aspect of external rewards and argues that they are like drugs, where more frequent doses are needed more often. Rewards can often signal that an activity is undesirable.
Interesting and challenging activities are often rewarding in themselves. Rewards tend to focus and narrow attention and work well only if they enhance the ability to do something intrinsically valuable. Extrinsic motivation is best when used to motivate employees to perform routine and repetitive activities but can be detrimental for creative endeavors.
Anticipating rewards can also impair judgment and cause risk-seeking behavior because it activates dopamine. We don’t notice peripheral and long-term solutions when immediate rewards are offered. Studies have shown that people will often choose the low road when chasing after rewards because addictive behavior is short-term focused, and some may opt for a quick win.
Pink (2011) warns that greatness and nearsightedness are incompatible, and seven deadly flaws of rewards are soon to follow. He found that anticipating rewards often has undesirable consequences and tends to:
- Extinguish intrinsic motivation
- Decrease performance
- Encourage cheating
- Decrease creativity
- Crowd out good behavior
- Become addictive
- Foster short-term thinking
Pink (2011) suggests that we should reward only routine tasks to boost motivation and provide rationale, acknowledge that some activities are boring, and allow people to complete the task their way. When we increase variety and mastery opportunities at work, we increase motivation.
Rewards should be given only after the task is completed, preferably as a surprise, varied in frequency, and alternated between tangible rewards and praise. Providing information and meaningful, specific feedback about the effort (not the person) has also been found to be more effective than material rewards for increasing motivation (Pink, 2011).

They have shaped the landscape of our understanding of organizational behavior and our approaches to employee motivation. We discuss a few of the most frequently applied theories of motivation in organizational behavior.
Herzberg’s two-factor theory
Frederick Herzberg’s (1959) two-factor theory of motivation, also known as dual-factor theory or motivation-hygiene theory, was a result of a study that analyzed responses of 200 accountants and engineers who were asked about their positive and negative feelings about their work. Herzberg (1959) concluded that two major factors influence employee motivation and satisfaction with their jobs:
- Motivator factors, which can motivate employees to work harder and lead to on-the-job satisfaction, including experiences of greater engagement in and enjoyment of the work, feelings of recognition, and a sense of career progression
- Hygiene factors, which can potentially lead to dissatisfaction and a lack of motivation if they are absent, such as adequate compensation, effective company policies, comprehensive benefits, or good relationships with managers and coworkers
Herzberg (1959) maintained that while motivator and hygiene factors both influence motivation, they appeared to work entirely independently of each other. He found that motivator factors increased employee satisfaction and motivation, but the absence of these factors didn’t necessarily cause dissatisfaction.
Likewise, the presence of hygiene factors didn’t appear to increase satisfaction and motivation, but their absence caused an increase in dissatisfaction. It is debatable whether his theory would hold true today outside of blue-collar industries, particularly among younger generations, who may be looking for meaningful work and growth.
Maslow’s hierarchy of needs
Abraham Maslow’s hierarchy of needs theory proposed that employees become motivated along a continuum of needs from basic physiological needs to higher level psychological needs for growth and self-actualization . The hierarchy was originally conceptualized into five levels:
- Physiological needs that must be met for a person to survive, such as food, water, and shelter
- Safety needs that include personal and financial security, health, and wellbeing
- Belonging needs for friendships, relationships, and family
- Esteem needs that include feelings of confidence in the self and respect from others
- Self-actualization needs that define the desire to achieve everything we possibly can and realize our full potential
According to the hierarchy of needs, we must be in good health, safe, and secure with meaningful relationships and confidence before we can reach for the realization of our full potential.
For a full discussion of other theories of psychological needs and the importance of need satisfaction, see our article on How to Motivate .
Hawthorne effect
The Hawthorne effect, named after a series of social experiments on the influence of physical conditions on productivity at Western Electric’s factory in Hawthorne, Chicago, in the 1920s and 30s, was first described by Henry Landsberger in 1958 after he noticed some people tended to work harder and perform better when researchers were observing them.
Although the researchers changed many physical conditions throughout the experiments, including lighting, working hours, and breaks, increases in employee productivity were more significant in response to the attention being paid to them, rather than the physical changes themselves.
Today the Hawthorne effect is best understood as a justification for the value of providing employees with specific and meaningful feedback and recognition. It is contradicted by the existence of results-only workplace environments that allow complete autonomy and are focused on performance and deliverables rather than managing employees.
Expectancy theory
Expectancy theory proposes that we are motivated by our expectations of the outcomes as a result of our behavior and make a decision based on the likelihood of being rewarded for that behavior in a way that we perceive as valuable.
For example, an employee may be more likely to work harder if they have been promised a raise than if they only assumed they might get one.

Expectancy theory posits that three elements affect our behavioral choices:
- Expectancy is the belief that our effort will result in our desired goal and is based on our past experience and influenced by our self-confidence and anticipation of how difficult the goal is to achieve.
- Instrumentality is the belief that we will receive a reward if we meet performance expectations.
- Valence is the value we place on the reward.
Expectancy theory tells us that we are most motivated when we believe that we will receive the desired reward if we hit an achievable and valued target, and least motivated if we do not care for the reward or do not believe that our efforts will result in the reward.
Three-dimensional theory of attribution
Attribution theory explains how we attach meaning to our own and other people’s behavior and how the characteristics of these attributions can affect future motivation.
Bernard Weiner’s three-dimensional theory of attribution proposes that the nature of the specific attribution, such as bad luck or not working hard enough, is less important than the characteristics of that attribution as perceived and experienced by the individual. According to Weiner, there are three main characteristics of attributions that can influence how we behave in the future:
Stability is related to pervasiveness and permanence; an example of a stable factor is an employee believing that they failed to meet the expectation because of a lack of support or competence. An unstable factor might be not performing well due to illness or a temporary shortage of resources.
“There are no secrets to success. It is the result of preparation, hard work, and learning from failure.”
Colin Powell
According to Weiner, stable attributions for successful achievements can be informed by previous positive experiences, such as completing the project on time, and can lead to positive expectations and higher motivation for success in the future. Adverse situations, such as repeated failures to meet the deadline, can lead to stable attributions characterized by a sense of futility and lower expectations in the future.
Locus of control describes a perspective about the event as caused by either an internal or an external factor. For example, if the employee believes it was their fault the project failed, because of an innate quality such as a lack of skills or ability to meet the challenge, they may be less motivated in the future.
If they believe an external factor was to blame, such as an unrealistic deadline or shortage of staff, they may not experience such a drop in motivation.
Controllability defines how controllable or avoidable the situation was. If an employee believes they could have performed better, they may be less motivated to try again in the future than someone who believes that factors outside of their control caused the circumstances surrounding the setback.

Theory X and theory Y
Douglas McGregor proposed two theories to describe managerial views on employee motivation: theory X and theory Y. These views of employee motivation have drastically different implications for management.
He divided leaders into those who believe most employees avoid work and dislike responsibility (theory X managers) and those who say that most employees enjoy work and exert effort when they have control in the workplace (theory Y managers).
To motivate theory X employees, the company needs to push and control their staff through enforcing rules and implementing punishments.
Theory Y employees, on the other hand, are perceived as consciously choosing to be involved in their work. They are self-motivated and can exert self-management, and leaders’ responsibility is to create a supportive environment and develop opportunities for employees to take on responsibility and show creativity.
Theory X is heavily informed by what we know about intrinsic motivation and the role that the satisfaction of basic psychological needs plays in effective employee motivation.

Taking theory X and theory Y as a starting point, theory Z was developed by Dr. William Ouchi. The theory combines American and Japanese management philosophies and focuses on long-term job security, consensual decision making, slow evaluation and promotion procedures, and individual responsibility within a group context.
Its noble goals include increasing employee loyalty to the company by providing a job for life, focusing on the employee’s wellbeing, and encouraging group work and social interaction to motivate employees in the workplace.

There are several implications of these numerous theories on ways to motivate employees. They vary with whatever perspectives leadership ascribes to motivation and how that is cascaded down and incorporated into practices, policies, and culture.
The effectiveness of these approaches is further determined by whether individual preferences for motivation are considered. Nevertheless, various motivational theories can guide our focus on aspects of organizational behavior that may require intervening.
Herzberg’s two-factor theory , for example, implies that for the happiest and most productive workforce, companies need to work on improving both motivator and hygiene factors.
The theory suggests that to help motivate employees, the organization must ensure that everyone feels appreciated and supported, is given plenty of specific and meaningful feedback, and has an understanding of and confidence in how they can grow and progress professionally.
To prevent job dissatisfaction, companies must make sure to address hygiene factors by offering employees the best possible working conditions, fair pay, and supportive relationships.
Maslow’s hierarchy of needs , on the other hand, can be used to transform a business where managers struggle with the abstract concept of self-actualization and tend to focus too much on lower level needs. Chip Conley, the founder of the Joie de Vivre hotel chain and head of hospitality at Airbnb, found one way to address this dilemma by helping his employees understand the meaning of their roles during a staff retreat.
In one exercise, he asked groups of housekeepers to describe themselves and their job responsibilities by giving their group a name that reflects the nature and the purpose of what they were doing. They came up with names such as “The Serenity Sisters,” “The Clutter Busters,” and “The Peace of Mind Police.”
These designations provided a meaningful rationale and gave them a sense that they were doing more than just cleaning, instead “creating a space for a traveler who was far away from home to feel safe and protected” (Pattison, 2010). By showing them the value of their roles, Conley enabled his employees to feel respected and motivated to work harder.
The Hawthorne effect studies and Weiner’s three-dimensional theory of attribution have implications for providing and soliciting regular feedback and praise. Recognizing employees’ efforts and providing specific and constructive feedback in the areas where they can improve can help prevent them from attributing their failures to an innate lack of skills.
Praising employees for improvement or using the correct methodology, even if the ultimate results were not achieved, can encourage them to reframe setbacks as learning opportunities. This can foster an environment of psychological safety that can further contribute to the view that success is controllable by using different strategies and setting achievable goals .
Theories X, Y, and Z show that one of the most impactful ways to build a thriving organization is to craft organizational practices that build autonomy, competence, and belonging. These practices include providing decision-making discretion, sharing information broadly, minimizing incidents of incivility, and offering performance feedback.
Being told what to do is not an effective way to negotiate. Having a sense of autonomy at work fuels vitality and growth and creates environments where employees are more likely to thrive when empowered to make decisions that affect their work.
Feedback satisfies the psychological need for competence. When others value our work, we tend to appreciate it more and work harder. Particularly two-way, open, frequent, and guided feedback creates opportunities for learning.
Frequent and specific feedback helps people know where they stand in terms of their skills, competencies, and performance, and builds feelings of competence and thriving. Immediate, specific, and public praise focusing on effort and behavior and not traits is most effective. Positive feedback energizes employees to seek their full potential.
Lack of appreciation is psychologically exhausting, and studies show that recognition improves health because people experience less stress. In addition to being acknowledged by their manager, peer-to-peer recognition was shown to have a positive impact on the employee experience (Anderson, 2018). Rewarding the team around the person who did well and giving more responsibility to top performers rather than time off also had a positive impact.
Stop trying to motivate your employees – Kerry Goyette
Other approaches to motivation at work include those that focus on meaning and those that stress the importance of creating positive work environments.
Meaningful work is increasingly considered to be a cornerstone of motivation. In some cases, burnout is not caused by too much work, but by too little meaning. For many years, researchers have recognized the motivating potential of task significance and doing work that affects the wellbeing of others.
All too often, employees do work that makes a difference but never have the chance to see or to meet the people affected. Research by Adam Grant (2013) speaks to the power of long-term goals that benefit others and shows how the use of meaning to motivate those who are not likely to climb the ladder can make the job meaningful by broadening perspectives.
Creating an upbeat, positive work environment can also play an essential role in increasing employee motivation and can be accomplished through the following:
- Encouraging teamwork and sharing ideas
- Providing tools and knowledge to perform well
- Eliminating conflict as it arises
- Giving employees the freedom to work independently when appropriate
- Helping employees establish professional goals and objectives and aligning these goals with the individual’s self-esteem
- Making the cause and effect relationship clear by establishing a goal and its reward
- Offering encouragement when workers hit notable milestones
- Celebrating employee achievements and team accomplishments while avoiding comparing one worker’s achievements to those of others
- Offering the incentive of a profit-sharing program and collective goal setting and teamwork
- Soliciting employee input through regular surveys of employee satisfaction
- Providing professional enrichment through providing tuition reimbursement and encouraging employees to pursue additional education and participate in industry organizations, skills workshops, and seminars
- Motivating through curiosity and creating an environment that stimulates employee interest to learn more
- Using cooperation and competition as a form of motivation based on individual preferences
Sometimes, inexperienced leaders will assume that the same factors that motivate one employee, or the leaders themselves, will motivate others too. Some will make the mistake of introducing de-motivating factors into the workplace, such as punishment for mistakes or frequent criticism, but negative reinforcement rarely works and often backfires.

Download 3 Free Goals Exercises (PDF)
These detailed, science-based exercises will help you or your clients create actionable goals and master techniques for lasting behavior change.
Download 3 Free Goals Pack (PDF)
By filling out your name and email address below.
- Email Address *
- Your Expertise * Your expertise Therapy Coaching Education Counseling Business Healthcare Other
- Phone This field is for validation purposes and should be left unchanged.
There are several positive psychology interventions that can be used in the workplace to improve important outcomes, such as reduced job stress and increased motivation, work engagement, and job performance. Numerous empirical studies have been conducted in recent years to verify the effects of these interventions.

World’s Largest Positive Psychology Resource
The Positive Psychology Toolkit© is a groundbreaking practitioner resource containing over 500 science-based exercises , activities, interventions, questionnaires, and assessments created by experts using the latest positive psychology research.
Updated monthly. 100% Science-based.
“The best positive psychology resource out there!” — Emiliya Zhivotovskaya , Flourishing Center CEO
Psychological capital interventions
Psychological capital interventions are associated with a variety of work outcomes that include improved job performance, engagement, and organizational citizenship behaviors (Avey, 2014; Luthans & Youssef-Morgan 2017). Psychological capital refers to a psychological state that is malleable and open to development and consists of four major components:
- Self-efficacy and confidence in our ability to succeed at challenging work tasks
- Optimism and positive attributions about the future of our career or company
- Hope and redirecting paths to work goals in the face of obstacles
- Resilience in the workplace and bouncing back from adverse situations (Luthans & Youssef-Morgan, 2017)
Job crafting interventions
Job crafting interventions – where employees design and have control over the characteristics of their work to create an optimal fit between work demands and their personal strengths – can lead to improved performance and greater work engagement (Bakker, Tims, & Derks, 2012; van Wingerden, Bakker, & Derks, 2016).
The concept of job crafting is rooted in the jobs demands–resources theory and suggests that employee motivation, engagement, and performance can be influenced by practices such as (Bakker et al., 2012):
- Attempts to alter social job resources, such as feedback and coaching
- Structural job resources, such as opportunities to develop at work
- Challenging job demands, such as reducing workload and creating new projects
Job crafting is a self-initiated, proactive process by which employees change elements of their jobs to optimize the fit between their job demands and personal needs, abilities, and strengths (Wrzesniewski & Dutton, 2001).

Today’s motivation research shows that participation is likely to lead to several positive behaviors as long as managers encourage greater engagement, motivation, and productivity while recognizing the importance of rest and work recovery.
One key factor for increasing work engagement is psychological safety (Kahn, 1990). Psychological safety allows an employee or team member to engage in interpersonal risk taking and refers to being able to bring our authentic self to work without fear of negative consequences to self-image, status, or career (Edmondson, 1999).
When employees perceive psychological safety, they are less likely to be distracted by negative emotions such as fear, which stems from worrying about controlling perceptions of managers and colleagues.
Dealing with fear also requires intense emotional regulation (Barsade, Brief, & Spataro, 2003), which takes away from the ability to fully immerse ourselves in our work tasks. The presence of psychological safety in the workplace decreases such distractions and allows employees to expend their energy toward being absorbed and attentive to work tasks.
Effective structural features, such as coaching leadership and context support, are some ways managers can initiate psychological safety in the workplace (Hackman, 1987). Leaders’ behavior can significantly influence how employees behave and lead to greater trust (Tyler & Lind, 1992).
Supportive, coaching-oriented, and non-defensive responses to employee concerns and questions can lead to heightened feelings of safety and ensure the presence of vital psychological capital.
Another essential factor for increasing work engagement and motivation is the balance between employees’ job demands and resources.
Job demands can stem from time pressures, physical demands, high priority, and shift work and are not necessarily detrimental. High job demands and high resources can both increase engagement, but it is important that employees perceive that they are in balance, with sufficient resources to deal with their work demands (Crawford, LePine, & Rich, 2010).
Challenging demands can be very motivating, energizing employees to achieve their goals and stimulating their personal growth. Still, they also require that employees be more attentive and absorbed and direct more energy toward their work (Bakker & Demerouti, 2014).
Unfortunately, when employees perceive that they do not have enough control to tackle these challenging demands, the same high demands will be experienced as very depleting (Karasek, 1979).
This sense of perceived control can be increased with sufficient resources like managerial and peer support and, like the effects of psychological safety, can ensure that employees are not hindered by distraction that can limit their attention, absorption, and energy.
The job demands–resources occupational stress model suggests that job demands that force employees to be attentive and absorbed can be depleting if not coupled with adequate resources, and shows how sufficient resources allow employees to sustain a positive level of engagement that does not eventually lead to discouragement or burnout (Demerouti, Bakker, Nachreiner, & Schaufeli, 2001).
And last but not least, another set of factors that are critical for increasing work engagement involves core self-evaluations and self-concept (Judge & Bono, 2001). Efficacy, self-esteem, locus of control, identity, and perceived social impact may be critical drivers of an individual’s psychological availability, as evident in the attention, absorption, and energy directed toward their work.
Self-esteem and efficacy are enhanced by increasing employees’ general confidence in their abilities, which in turn assists in making them feel secure about themselves and, therefore, more motivated and engaged in their work (Crawford et al., 2010).
Social impact, in particular, has become increasingly important in the growing tendency for employees to seek out meaningful work. One such example is the MBA Oath created by 25 graduating Harvard business students pledging to lead professional careers marked with integrity and ethics:
The MBA oath
“As a business leader, I recognize my role in society.
My purpose is to lead people and manage resources to create value that no single individual can create alone.
My decisions affect the well-being of individuals inside and outside my enterprise, today and tomorrow. Therefore, I promise that:
- I will manage my enterprise with loyalty and care, and will not advance my personal interests at the expense of my enterprise or society.
- I will understand and uphold, in letter and spirit, the laws and contracts governing my conduct and that of my enterprise.
- I will refrain from corruption, unfair competition, or business practices harmful to society.
- I will protect the human rights and dignity of all people affected by my enterprise, and I will oppose discrimination and exploitation.
- I will protect the right of future generations to advance their standard of living and enjoy a healthy planet.
- I will report the performance and risks of my enterprise accurately and honestly.
- I will invest in developing myself and others, helping the management profession continue to advance and create sustainable and inclusive prosperity.
In exercising my professional duties according to these principles, I recognize that my behavior must set an example of integrity, eliciting trust, and esteem from those I serve. I will remain accountable to my peers and to society for my actions and for upholding these standards. This oath, I make freely, and upon my honor.”
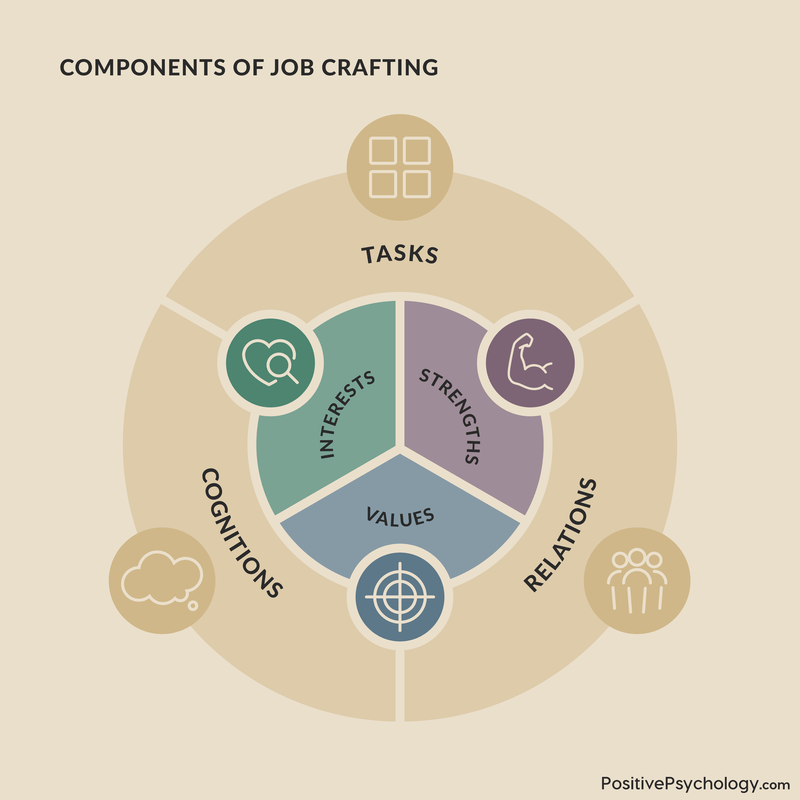
Job crafting is the process of personalizing work to better align with one’s strengths, values, and interests (Tims & Bakker, 2010).
Any job, at any level can be ‘crafted,’ and a well-crafted job offers more autonomy, deeper engagement and improved overall wellbeing.
There are three types of job crafting:
- Task crafting involves adding or removing tasks, spending more or less time on certain tasks, or redesigning tasks so that they better align with your core strengths (Berg et al., 2013).
- Relational crafting includes building, reframing, and adapting relationships to foster meaningfulness (Berg et al., 2013).
- Cognitive crafting defines how we think about our jobs, including how we perceive tasks and the meaning behind them.
If you would like to guide others through their own unique job crafting journey, our set of Job Crafting Manuals (PDF) offer a ready-made 7-session coaching trajectory.
Prosocial motivation is an important driver behind many individual and collective accomplishments at work.
It is a strong predictor of persistence, performance, and productivity when accompanied by intrinsic motivation. Prosocial motivation was also indicative of more affiliative citizenship behaviors when it was accompanied by motivation toward impression management motivation and was a stronger predictor of job performance when managers were perceived as trustworthy (Ciulla, 2000).
On a day-to-day basis most jobs can’t fill the tall order of making the world better, but particular incidents at work have meaning because you make a valuable contribution or you are able to genuinely help someone in need.
J. B. Ciulla
Prosocial motivation was shown to enhance the creativity of intrinsically motivated employees, the performance of employees with high core self-evaluations, and the performance evaluations of proactive employees. The psychological mechanisms that enable this are the importance placed on task significance, encouraging perspective taking, and fostering social emotions of anticipated guilt and gratitude (Ciulla, 2000).
Some argue that organizations whose products and services contribute to positive human growth are examples of what constitutes good business (Csíkszentmihályi, 2004). Businesses with a soul are those enterprises where employees experience deep engagement and develop greater complexity.
In these unique environments, employees are provided opportunities to do what they do best. In return, their organizations reap the benefits of higher productivity and lower turnover, as well as greater profit, customer satisfaction, and workplace safety. Most importantly, however, the level of engagement, involvement, or degree to which employees are positively stretched contributes to the experience of wellbeing at work (Csíkszentmihályi, 2004).

17 Tools To Increase Motivation and Goal Achievement
These 17 Motivation & Goal Achievement Exercises [PDF] contain all you need to help others set meaningful goals, increase self-drive, and experience greater accomplishment and life satisfaction.
Created by Experts. 100% Science-based.
Daniel Pink (2011) argues that when it comes to motivation, management is the problem, not the solution, as it represents antiquated notions of what motivates people. He claims that even the most sophisticated forms of empowering employees and providing flexibility are no more than civilized forms of control.
He gives an example of companies that fall under the umbrella of what is known as results-only work environments (ROWEs), which allow all their employees to work whenever and wherever they want as long their work gets done.
Valuing results rather than face time can change the cultural definition of a successful worker by challenging the notion that long hours and constant availability signal commitment (Kelly, Moen, & Tranby, 2011).
Studies show that ROWEs can increase employees’ control over their work schedule; improve work–life fit; positively affect employees’ sleep duration, energy levels, self-reported health, and exercise; and decrease tobacco and alcohol use (Moen, Kelly, & Lam, 2013; Moen, Kelly, Tranby, & Huang, 2011).
Perhaps this type of solution sounds overly ambitious, and many traditional working environments are not ready for such drastic changes. Nevertheless, it is hard to ignore the quickly amassing evidence that work environments that offer autonomy, opportunities for growth, and pursuit of meaning are good for our health, our souls, and our society.
Leave us your thoughts on this topic.
Related reading: Motivation in Education: What It Takes to Motivate Our Kids
We hope you enjoyed reading this article. Don’t forget to download our three Goal Achievement Exercises for free .
- Anderson, D. (2018, February 22). 11 Surprising statistics about employee recognition [infographic]. Best Practice in Human Resources. Retrieved from https://www.bestpracticeinhr.com/11-surprising-statistics-about-employee-recognition-infographic/
- Avey, J. B. (2014). The left side of psychological capital: New evidence on the antecedents of PsyCap. Journal of Leadership & Organizational Studies, 21( 2), 141–149.
- Bakker, A. B., & Demerouti, E. (2014). Job demands–resources theory. In P. Y. Chen & C. L. Cooper (Eds.), Wellbeing: A complete reference guide (vol. 3). John Wiley and Sons.
- Bakker, A. B., Tims, M., & Derks, D. (2012). Proactive personality and job performance: The role of job crafting and work engagement. Human Relations , 65 (10), 1359–1378
- Barsade, S. G., Brief, A. P., & Spataro, S. E. (2003). The affective revolution in organizational behavior: The emergence of a paradigm. In J. Greenberg (Ed.), Organizational behavior: The state of the science (pp. 3–52). Lawrence Erlbaum Associates.
- Berg, J. M., Dutton, J. E., & Wrzesniewski, A. (2013). Job crafting and meaningful work. In B. J. Dik, Z. S. Byrne, & M. F. Steger (Eds.), Purpose and meaning in the workplace (pp. 81-104) . American Psychological Association.
- Ciulla, J. B. (2000). The working life: The promise and betrayal of modern work. Three Rivers Press.
- Crawford, E. R., LePine, J. A., & Rich, B. L. (2010). Linking job demands and resources to employee engagement and burnout: A theoretical extension and meta-analytic test. Journal of Applied Psychology , 95 (5), 834–848.
- Csíkszentmihályi, M. (2004). Good business: Leadership, flow, and the making of meaning. Penguin Books.
- Demerouti, E., Bakker, A. B., Nachreiner, F., & Schaufeli, W. B. (2001). The job demands–resources model of burnout. Journal of Applied Psychology , 863) , 499–512.
- Edmondson, A. (1999). Psychological safety and learning behavior in work teams. Administrative Science Quarterly , 44 (2), 350–383.
- Grant, A. M. (2013). Give and take: A revolutionary approach to success. Penguin.
- Hackman, J. R. (1987). The design of work teams. In J. Lorsch (Ed.), Handbook of organizational behavior (pp. 315–342). Prentice-Hall.
- Herzberg, F. (1959). The motivation to work. Wiley.
- Judge, T. A., & Bono, J. E. (2001). Relationship of core self-evaluations traits – self-esteem, generalized self-efficacy, locus of control, and emotional stability – with job satisfaction and job performance: A meta-analysis. Journal of Applied Psychology , 86 (1), 80–92.
- Kahn, W. A. (1990). Psychological conditions of personal engagement and disengagement at work. Academy of Management Journal , 33 (4), 692–724.
- Karasek, R. A., Jr. (1979). Job demands, job decision latitude, and mental strain: Implications for job redesign. Administrative Science Quarterly, 24 (2), 285–308.
- Kelly, E. L., Moen, P., & Tranby, E. (2011). Changing workplaces to reduce work-family conflict: Schedule control in a white-collar organization. American Sociological Review , 76 (2), 265–290.
- Landsberger, H. A. (1958). Hawthorne revisited: Management and the worker, its critics, and developments in human relations in industry. Cornell University.
- Luthans, F., & Youssef-Morgan, C. M. (2017). Psychological capital: An evidence-based positive approach. Annual Review of Organizational Psychology and Organizational Behavior, 4 , 339-366.
- Moen, P., Kelly, E. L., & Lam, J. (2013). Healthy work revisited: Do changes in time strain predict well-being? Journal of occupational health psychology, 18 (2), 157.
- Moen, P., Kelly, E., Tranby, E., & Huang, Q. (2011). Changing work, changing health: Can real work-time flexibility promote health behaviors and well-being? Journal of Health and Social Behavior, 52(4), 404–429.
- Pattison, K. (2010, August 26). Chip Conley took the Maslow pyramid, made it an employee pyramid and saved his company. Fast Company. Retrieved from https://www.fastcompany.com/1685009/chip-conley-took-maslow-pyramid-made-it-employee-pyramid-and-saved-his-company
- Pink, D. H. (2011). Drive: The surprising truth about what motivates us. Penguin.
- Tims, M., & Bakker, A. B. (2010). Job crafting: Towards a new model of individual job redesign. SA Journal of Industrial Psychology, 36(2) , 1-9.
- Tyler, T. R., & Lind, E. A. (1992). A relational model of authority in groups. In M. P. Zanna (Ed.), Advances in experimental social psychology (vol. 25) (pp. 115–191). Academic Press.
- von Wingerden, J., Bakker, A. B., & Derks, D. (2016). A test of a job demands–resources intervention. Journal of Managerial Psychology , 31 (3), 686–701.
- Wrzesniewski, A., & Dutton, J. E. (2001). Crafting a job: Revisioning employees as active crafters of their work. Academy of Management Review, 26 (2), 179–201.

Share this article:
Article feedback
What our readers think.

Good and helpful study thank you. It will help achieving goals for my clients. Thank you for this information

A lot of data is really given. Validation is correct. The next step is the exchange of knowledge in order to create an optimal model of motivation.

A good article, thank you for sharing. The views and work by the likes of Daniel Pink, Dan Ariely, Barry Schwartz etc have really got me questioning and reflecting on my own views on workplace motivation. There are far too many organisations and leaders who continue to rely on hedonic principles for motivation (until recently, myself included!!). An excellent book which shares these modern views is ‘Primed to Perform’ by Doshi and McGregor (2015). Based on the earlier work of Deci and Ryan’s self determination theory the book explores the principle of ‘why people work, determines how well they work’. A easy to read and enjoyable book that offers a very practical way of applying in the workplace.

Thanks for mentioning that. Sounds like a good read.
All the best, Annelé

Motivation – a piece of art every manager should obtain and remember by heart and continue to embrace.

Exceptionally good write-up on the subject applicable for personal and professional betterment. Simplified theorem appeals to think and learn at least one thing that means an inspiration to the reader. I appreciate your efforts through this contributive work.

Excelente artículo sobre motivación. Me inspira. Gracias

Very helpful for everyone studying motivation right now! It’s brilliant the way it’s witten and also brought to the reader. Thank you.

Such a brilliant piece! A super coverage of existing theories clearly written. It serves as an excellent overview (or reminder for those of us who once knew the older stuff by heart!) Thank you!
Let us know your thoughts Cancel reply
Your email address will not be published.
Save my name, email, and website in this browser for the next time I comment.
Related articles

How to Encourage Clients to Embrace Change
Many of us struggle with change, especially when it’s imposed upon us rather than chosen. Yet despite its inevitability, without it, there would be no [...]

Victor Vroom’s Expectancy Theory of Motivation
Motivation is vital to beginning and maintaining healthy behavior in the workplace, education, and beyond, and it drives us toward our desired outcomes (Zajda, 2023). [...]

SMART Goals, HARD Goals, PACT, or OKRs: What Works?
Goal setting is vital in business, education, and performance environments such as sports, yet it is also a key component of many coaching and counseling [...]
Read other articles by their category
- Body & Brain (52)
- Coaching & Application (39)
- Compassion (23)
- Counseling (40)
- Emotional Intelligence (21)
- Gratitude (18)
- Grief & Bereavement (18)
- Happiness & SWB (40)
- Meaning & Values (26)
- Meditation (16)
- Mindfulness (40)
- Motivation & Goals (41)
- Optimism & Mindset (29)
- Positive CBT (28)
- Positive Communication (23)
- Positive Education (36)
- Positive Emotions (32)
- Positive Leadership (16)
- Positive Parenting (14)
- Positive Psychology (21)
- Positive Workplace (35)
- Productivity (16)
- Relationships (46)
- Resilience & Coping (38)
- Self Awareness (20)
- Self Esteem (37)
- Strengths & Virtues (29)
- Stress & Burnout Prevention (33)
- Theory & Books (42)
- Therapy Exercises (37)
- Types of Therapy (54)
- Comments This field is for validation purposes and should be left unchanged.
3 Goal Achievement Exercises Pack
How it works
Transform your enterprise with the scalable mindsets, skills, & behavior change that drive performance.
Explore how BetterUp connects to your core business systems.
We pair AI with the latest in human-centered coaching to drive powerful, lasting learning and behavior change.
Build leaders that accelerate team performance and engagement.
Unlock performance potential at scale with AI-powered curated growth journeys.
Build resilience, well-being and agility to drive performance across your entire enterprise.
Transform your business, starting with your sales leaders.
Unlock business impact from the top with executive coaching.
Foster a culture of inclusion and belonging.
Accelerate the performance and potential of your agencies and employees.
See how innovative organizations use BetterUp to build a thriving workforce.
Discover how BetterUp measurably impacts key business outcomes for organizations like yours.
Daring Leadership Institute: a groundbreaking partnership that amplifies Brené Brown's empirically based, courage-building curriculum with BetterUp’s human transformation platform.

- What is coaching?
Learn how 1:1 coaching works, who its for, and if it's right for you.
Accelerate your personal and professional growth with the expert guidance of a BetterUp Coach.
Types of Coaching
Navigate career transitions, accelerate your professional growth, and achieve your career goals with expert coaching.
Enhance your communication skills for better personal and professional relationships, with tailored coaching that focuses on your needs.
Find balance, resilience, and well-being in all areas of your life with holistic coaching designed to empower you.
Discover your perfect match : Take our 5-minute assessment and let us pair you with one of our top Coaches tailored just for you.
Find your coach
-1.png "social experiments at work")
Research, expert insights, and resources to develop courageous leaders within your organization.
Best practices, research, and tools to fuel individual and business growth.
View on-demand BetterUp events and learn about upcoming live discussions.
The latest insights and ideas for building a high-performing workplace.
- BetterUp Briefing
The online magazine that helps you understand tomorrow's workforce trends, today.
Innovative research featured in peer-reviewed journals, press, and more.
Founded in 2022 to deepen the understanding of the intersection of well-being, purpose, and performance
We're on a mission to help everyone live with clarity, purpose, and passion.
Join us and create impactful change.
Read the buzz about BetterUp.
Meet the leadership that's passionate about empowering your workforce.

For Business
For Individuals

Experimentation brings innovation: Create an experimental workplace

Jump to section
What’s experimentation in the workplace?
Why you should foster a culture of experimentation
How to build a culture of experimentation: 8 ways.
Confronting the challenges of innovation
Success through failure
In an increasingly noisy digital age, you need your product or service to stand out so people choose you over other companies.
To find solutions that get your target audience’s attention, you can foster a culture of experimentation in your workforce. Allowing employees to try — and fail — is how you’ll find innovative ideas that change the game.
What’s experimentation in the workplace?
Experimentation in the workplace involves asking employees to question the status quo, try out ideas even if they fear failure , and embrace change . Leaders also encourage cross-departmental brainstorming to break down silos which increases the chance teams land on innovative ideas brought about through collaboration.
Encouraging experimentation also involves bringing together unique perspectives across professional hierarchies. Managers encourage upward communication from entry-level employees about what to try and procedures to change. And leaders might ask staff of every level to present their ideas, trials, and failures to team members.
An experimental workforce also prioritizes research on industry trends and innovations to pivot quickly when new technologies arise. They try to be one of the first companies to embrace these advancements.
Pinning innovation into the fabric of your business requires drive, conviction, and constantly returning to the drawing board. But it pays off. Here are a few benefits of encouraging experimentation in your workforce:
- Saves you money: Trying out ideas helps you decide if a solution is worth investing in. Rather than diving into the market headfirst with all your resources, experimentation separates good ideas from bad ones.
- Increases everyone’s knowledge: Open brainstorming and testing expand your business’s cognitive diversity. The more comfortable people feel sharing, the wider the pool of experiences and perspectives all employees can learn from.
- Provides a way to implement systematic changes: Experiments allow you to systematically break down changes into smaller pieces. Rather than launching a complex new service, you can progressively build, test, modify, and release interventions.
- Drives growth: A ccording to a study by McKinse y, crisis-fueled experimentation was the main driver of organic growth for companies during the pandemic . Companies that refocused quickly, invested more resources, and experimented with new technologies accelerated faster than others.
- Everyone enjoys greater success: The quicker you fai l, the faster you'll reach success if you’re resilient . So leaders who make their staff feel comfortable rather than afraid of the occasional disapp ointment increase their chance of success.
- Increases employee retention : Employees want to feel valued at work . And you can showcase this value by listening to and trying out their ideas.
- Boosts employee morale: A/B testing allows employees to clearly see their accomplishments because of the quantified results . They can also more easily share this information — in a spreadsheet, during a presentation — than qualitative accomplishments like “My yearly review went very well.”
- Encourages curiosity: Inquisitive employees are more likely to ask deeper questions and avoid “status quo” solutions. This curiosity can lead them to unique ideas or problem-solving outcomes compared to staff that are encouraged to think inside the box.

Unironically, creating a culture of experimentation involves running experiments to fig ure out what works best for your business. Here are eight methods for encouraging innovation at work:
1. Practice humility
Humility in leadership means accepting your knowledge gaps and mistakes. And when you’re vulnerable with your staff and admit you don’t have all the answers, you gain their trust and make them feel comfortable trying out ideas .
A fundamental step in creating a culture of experimentation is opening the floor to everybody in the organization. Rather than taking charge of brainstorming or being responsible for coming up with every solution, step aside and listen to help workers fine-tune their ideas.
2. Make failure your friend
In a culture of experimentation, everything won’t go as planned. But that’s the point. Experimentation shows you the right path to innovation by illuminating the roads that lead to nowhere.
When you accept failure as part of the process and not a roadblock to success, you also build important soft skills . This includes being cognitively flexible , resilient to challenges , and motivated to tackle tasks and achieve goals .
3. Drive with data
You can’t test ideas if you don’t know where you currently stand in your market. You won’t know who you’re targeting and how to measure success. So conduct market research and assess customer data to understand where your solution fits.
If your marketing department doesn’t have a dedicated team of research analysts, consider hiring a consultant. They’ll help run controlled experiments, build case studies, and outline risks and benefits. This allows you to unify subjective ideas with data-driven insights to launch effective and creative solutions .
4. Don’t reinvent the wheel
Your team doesn’t need to invent an entirely new solution to your target audience’s problem. Experimentation also involves improving current products and services. You’ll try out several tweaks to a current offering to see whether it satisfies your clients even more.

Workplace experimentation could even be internally-focused. You might rearrange in-office seating to see how it affects productivity or experiment with a new conferencing system during hybrid meetings . Encourage experimentation in your workforce by constantly trying new things to find the most effective option.
5. Encourage initiative
Clarify for everyone in the company that you’ll reward those who show initiative — no matter the experiment results. This public encouragement builds their confidence to follow through on instincts, share ideas, and develop skills fearlessly.
For example, encourage your sales team to experiment with new methodologies, client acquisition techniques, or workflow platforms to streamline processes. Then, allow all employees to offer feedback on the changes so their voices feel heard and valued and your sales team can gain fresh perspectives.
6. Don’t hate, collaborate
Regular brainstorming sessions effectively generate a wide pool of ideas. They also establish a teamwork-focused company culture and encourage diverse perspectives .
No matter the brainstorming technique you choose, discuss the session’s focus and agenda beforehand so everyone feels prepared and well-informed. The right balance of freedom to pursue curiosities and structure to fine-tune ideas will help keep experiments firmly planted on the ground.
7. Learn with A/B testing
You’ll likely identify multiple solutions to the same problem, so use A/B testing to narrow down the best choice. Test every iteration of an idea on the same users to choose the best solution to improve and launch.
Before conducting these tests, identify key metrics so everyone on your team understands what success looks like for each solution. When testing ideas for improving an app’s interface, a metric might be the number of call-to-action buttons clicked.
8. Resist the temptation to micromanage
If you tend to micromanage , you might need to adopt a new leadership model . Micromanagement can make employees feel their ideas and contributions aren’t valuable, so they’ll stop sharing. And experimentation might feel like a waste of time since you'll likely re-work methods or results to suit your style.
Instead, show you trust your employees’ creativity and competence by giving them the freedom to try new methods. When they bring a viable idea to the table, offer them resources to try it out even if there’s a chance it fails.

Confronting the challenges of innovation
Changing your business’s culture is a holistic process that touches every aspect of the organization, lik e leadership style , re source allotment, and keeping up morale in the face of failures. Here are a few challenges to encouraging experimentation:
- Resistance to change: Whether you’re a large-scale organization or startup, the leadership team might not want to change “business as usual,” so prepare to show them the benefits of experimentation with data and testimony.
- To launch or not to launch: It won’t always be easy to decide whether the test results are enough to launch a new strategy that implicates the whole company. Your research might not be meticulous enough and the test market could skew results. Or maybe the new strategy unexpectedly takes precious resources from other initiatives.
- Pulling the plug: Humans often make decisions based on emotions . You may find it hard pulling the plug on experiments that teams are excited about, even when data-driven research suggests something won’t succeed in the market.
- Drained resources: Experimentation requires time and resources, as does helping your team learn from failures. But building cross-functional teams, recording tests on open-access documents, and setting time aside to analyze mistakes can help keep time and resources in check.

Embracing experimentation in the workplace is all about becoming comfortable with discomfort. It’s scary conducting new experiments to test solutions that might not work.
But nobody makes it on the first try — you can only reach success through a series of failures. So really, they’re not failures since they gave you the confidence and insights necessary to move forward.
To encourage your team to be more experimental, start by assessing your current company culture. Note areas where you tend to go with the most obvious solutions or where you’re in a bit of a rut. You might find you’re micromanaging every project, so employees don’t feel they have the freedom to try new things.
Or perhaps you haven’t found a streamlined A/B testing process yet. Once you’ve pinpointed your weak areas, work with the entire team to fix them one-by-one until you’ve successfully created an experimentation culture.
Understand Yourself Better:
Big 5 Personality Test
Madeline Miles
Madeline is a writer, communicator, and storyteller who is passionate about using words to help drive positive change. She holds a bachelor's in English Creative Writing and Communication Studies and lives in Denver, Colorado. In her spare time, she's usually somewhere outside (preferably in the mountains) — and enjoys poetry and fiction.
How experiential learning encourages employees to own their learning
What’s convergent thinking how to be a better problem-solver, celebrating art, allyship, and authors for black history month, betterup named a 2019 “cool vendor” in human capital management: enhancing employee experience by gartnerup your game: a new model for leadership, 9 must-haves for a stellar candidate experience, what is a disc assessment and how can it help your team, 18 excellent educational podcasts to fuel your love of learning, how to create a culture of accountability in the workplace, gpa on a resume: when and how to include it, what is lateral thinking 7 techniques to encourage creative ideas, discover 4 types of innovation and how to encourage them, how tacit knowledge drives innovation and team outcomes, learn what disruptive innovation is and how to foster it, fundamental attribution error: how to recognize your bias, why creativity isn't just for creatives and how to find it anywhere, 37 innovation and creativity appraisal comments, stay connected with betterup, get our newsletter, event invites, plus product insights and research..
3100 E 5th Street, Suite 350 Austin, TX 78702
- Platform Overview
- Integrations
- Powered by AI
- BetterUp Lead™
- BetterUp Manage™
- BetterUp Care®
- Sales Performance
- Diversity & Inclusion
- Case Studies
- Why BetterUp?
- About Coaching
- Find your Coach
- Career Coaching
- Communication Coaching
- Personal Coaching
- News and Press
- Leadership Team
- Become a BetterUp Coach
- BetterUp Labs
- Center for Purpose & Performance
- Leadership Training
- Business Coaching
- Contact Support
- Contact Sales
- Privacy Policy
- Acceptable Use Policy
- Trust & Security
- Cookie Preferences

Work Life is Atlassian’s flagship publication dedicated to unleashing the potential of every team through real-life advice, inspiring stories, and thoughtful perspectives from leaders around the world.

Contributing Writer

Work Futurist

Senior Quantitative Researcher, People Insights

Principal Writer

The 7-day, science-backed experiment that can spark a culture of kindness

Cultivating kindness at work boosts productivity, motivation, and even retention, according to recent research. Use these simple strategies to inject some good vibes into your team interactions.
As one of the first lessons you learned in life, being kind to others may be something you take for granted. But research shows that kindness has tangible value across many aspects of life–and that value includes business value.
“There is now a plethora of data showing that when individuals engage in generous and altruistic behavior, they actually activate circuits in the brain that are key to fostering well-being,” explains Richard Davidson , author and founder of the Center for Healthy Minds at the University of Wisconsin.
When those positive feelings carry over to the workplace, things get even more interesting. A study reported on by KindCanada.org, found that employees who experienced frequent doses of kindness of work had:
- 26% more energy
- 36% more job satisfaction
- 44% greater commitment to their organization
- 30% greater motivation to learn new skills and ideas
The science behind kindness
When you’re kind to someone—even to yourself —your brain releases serotonin and dopamine. These are feel-good neurotransmitters , causing your brain to light up with satisfaction, pleasure, reward, and well-being.
Those reward signals are so powerful that they can trigger a chain reaction in interactions with other people. One study found that employees who were treated kindly were 278% more generous to coworkers compared to a control group. So if you’re thanked for a job well done, then you’re more likely to pay it forward by complimenting someone else.
The 7 days of kindness experiment
Oxford University and Kindness.org ran a study to quantify the value of kindness. They found that just seven days of small, random acts of kindness were enough to bring significantly more joy to the study participants’ lives. And the more acts of kindness people were exposed to, the greater the benefits.
Seven days of small, random acts of kindness bring serious changes to your life (and work life).
It just takes one person on your team to set the tone and model kind behavior for everyone. Once you’ve set that baseline, you can work together as a group to weave kindness into your meetings, daily work life, and workplace culture.
Challenge your teammates to commit to seven days of practicing random acts of kindness and see how it impacts productivity and morale.
Create a culture of kindness
Starting with seven days of random acts of kindness can be the first step toward creating a culture of kindness. To go even further:
- Get inspired by even more ideas for random acts of kindness from the Random Acts of Kindness organization

- Assign and rotate weekly kindness leaders on your team
- Challenge yourself and your team to keep up the kindness at work and at home
- Dedicate a few minutes of team meetings to kindness (give kudos, treats, and progress updates)
- Start every one-on-one meeting by complimenting the other person on something that went well
- Have team members write down each daily act of kindness they did in a Trello note and make a Trello Board that showcases kindness in the office
- Show your appreciation to others through kudos, celebrations, gifts, and acknowledgement
- Inspire other teams and departments to do the same
- Write kindness into your company policies and philosophy
Thinking bigger than small, random acts of kindness
Entrepreneur James Rhee gave a powerful TED talk on the value of kindness at work , in which he shared how kindness became such an important part of his organization’s culture and business philosophy.
Inspired from the top down, goodwill and kindness connected his company leaders, employees, and customers. Kindness set the tone for their branding, customer service, sales, marketing, and internal communications. Everything. It was infectious and even saved the company from bankruptcy.
“We had the courage to establish a culture of kindness in the workplace,” Rhee said. “It was a strategic priority day in and day out—and yeah, there were moments as individuals we failed. But as a collective, we were very successful in changing attitudes about the transformative power of kindness at work.”
Make it your philosophy to be kind at work and in life. Be kind to yourself and to others. Start with just seven days of small, random acts of kindness and see if it inspires you and others to do the same.
Advice, stories, and expertise about work life today.
- Bipolar Disorder
- Therapy Center
- When To See a Therapist
- Types of Therapy
- Best Online Therapy
- Best Couples Therapy
- Managing Stress
- Sleep and Dreaming
- Understanding Emotions
- Self-Improvement
- Healthy Relationships
- Student Resources
- Personality Types
- Sweepstakes
- Guided Meditations
- Verywell Mind Insights
- 2024 Verywell Mind 25
- Mental Health in the Classroom
- Editorial Process
- Meet Our Review Board
- Crisis Support
Ideas for Psychology Experiments
Inspiration for psychology experiments is all around if you know where to look
Psychology experiments can run the gamut from simple to complex. Students are often expected to design—and sometimes perform—their own experiments, but finding great experiment ideas can be a little challenging. Fortunately, inspiration is all around if you know where to look—from your textbooks to the questions that you have about your own life.
Always discuss your idea with your instructor before beginning your experiment—particularly if your research involves human participants. (Note: You'll probably need to submit a proposal and get approval from your school's institutional review board.)
At a Glance
If you are looking for an idea for psychology experiments, start your search early and make sure you have the time you need. Doing background research, choosing an experimental design, and actually performing your experiment can be quite the process. Keep reading to find some great psychology experiment ideas that can serve as inspiration. You can then find ways to adapt these ideas for your own assignments.
15 Ideas for Psychology Experiments
Most of these experiments can be performed easily at home or at school. That said, you will need to find out if you have to get approval from your teacher or from an institutional review board before getting started.
The following are some questions you could attempt to answer as part of a psychological experiment:
- Are people really able to "feel like someone is watching" them ? Have some participants sit alone in a room and have them note when they feel as if they are being watched. Then, see how those results line up to your own record of when participants were actually being observed.
- Can certain colors improve learning ? You may have heard teachers or students claim that printing text on green paper helps students read better, or that yellow paper helps students perform better on math exams. Design an experiment to see whether using a specific color of paper helps improve students' scores on math exams.
- Can color cause physiological reactions ? Perform an experiment to determine whether certain colors cause a participant's blood pressure to rise or fall.
- Can different types of music lead to different physiological responses ? Measure the heart rates of participants in response to various types of music to see if there is a difference.
- Can smelling one thing while tasting another impact a person's ability to detect what the food really is ? Have participants engage in a blind taste test where the smell and the food they eat are mismatched. Ask the participants to identify the food they are trying and note how accurate their guesses are.
- Could a person's taste in music offer hints about their personality ? Previous research has suggested that people who prefer certain styles of music tend to exhibit similar personality traits. Administer a personality assessment and survey participants about their musical preferences and examine your results.
- Do action films cause people to eat more popcorn and candy during a movie ? Have one group of participants watch an action movie, and another group watch a slow-paced drama. Compare how much popcorn is consumed by each group.
- Do colors really impact moods ? Investigate to see if the color blue makes people feel calm, or if the color red leaves them feeling agitated.
- Do creative people see optical illusions differently than more analytical people ? Have participants complete an assessment to measure their level of creative thinking. Then ask participants to look at optical illusions and note what they perceive.
- Do people rate individuals with perfectly symmetrical faces as more beautiful than those with asymmetrical faces ? Create sample cards with both symmetrical and asymmetrical faces and ask participants to rate the attractiveness of each picture.
- Do people who use social media exhibit signs of addiction ? Have participants complete an assessment of their social media habits, then have them complete an addiction questionnaire.
- Does eating breakfast help students do better in school ? According to some, eating breakfast can have a beneficial influence on school performance. For your experiment, you could compare the test scores of students who ate breakfast to those who did not.
- Does sex influence short-term memory ? You could arrange an experiment that tests whether men or women are better at remembering specific types of information.
- How likely are people to conform in groups ? Try this experiment to see what percentage of people are likely to conform . Enlist confederates to give the wrong response to a math problem and then see if the participants defy or conform to the rest of the group.
- How much information can people store in short-term memory ? Have participants study a word list and then test their memory. Try different versions of the experiment to see which memorization strategies, like chunking or mnemonics, are most effective.
Once you have an idea, the next step is to learn more about how to conduct a psychology experiment .
Psychology Experiments on Your Interests
If none of the ideas in the list above grabbed your attention, there are other ways to find inspiration for your psychology experiments.
How do you come up with good psychology experiments? One of the most effective approaches is to look at the various problems, situations, and questions that you are facing in your own life.
You can also think about the things that interest you. Start by considering the topics you've studied in class thus far that have really piqued your interest. Then, whittle the list down to two or three major areas within psychology that seem to interest you the most.
From there, make a list of questions you have related to the topic. Any of these questions could potentially serve as an experiment idea.
Use Textbooks for Inspiration for Psychology Experiments
Your psychology textbooks are another excellent source you can turn to for experiment ideas. Choose the chapters or sections that you find particularly interesting—perhaps it's a chapter on social psychology or a section on child development.
Start by browsing the experiments discussed in your book. Then think of how you could devise an experiment related to some of the questions your text asks. The reference section at the back of your textbook can also serve as a great source for additional reference material.
Discuss Psychology Experiments with Other Students
It can be helpful to brainstorm with your classmates to gather outside ideas and perspectives. Get together with a group of students and make a list of interesting ideas, subjects, or questions you have.
The information from your brainstorming session can serve as a basis for your experiment topic. It's also a great way to get feedback on your own ideas and to determine if they are worth exploring in greater depth.
Study Classic Psychology Experiments
Taking a closer look at a classic psychology experiment can be an excellent way to trigger some unique and thoughtful ideas of your own. To start, you could try conducting your own version of a famous experiment or even updating a classic experiment to assess a slightly different question.
Famous Psychology Experiments
Examples of famous psychology experiments that might be a source of further questions you'd like to explore include:
- Marshmallow test experiments
- Little Albert experiment
- Hawthorne effect experiments
- Bystander effect experiments
- Robbers Cave experiments
- Halo effect experiments
- Piano stairs experiment
- Cognitive dissonance experiments
- False memory experiments
You might not be able to replicate an experiment exactly (lots of classic psychology experiments have ethical issues that would preclude conducting them today), but you can use well-known studies as a basis for inspiration.
Review the Literature on Psychology Experiments
If you have a general idea about what topic you'd like to experiment, you might want to spend a little time doing a brief literature review before you start designing. In other words, do your homework before you invest too much time on an idea.
Visit your university library and find some of the best books and articles that cover the particular topic you are interested in. What research has already been done in this area? Are there any major questions that still need to be answered? What were the findings of previous psychology experiments?
Tackling this step early will make the later process of writing the introduction to your lab report or research paper much easier.
Ask Your Instructor About Ideas for Psychology Experiments
If you have made a good effort to come up with an idea on your own but you're still feeling stumped, it might help to talk to your instructor. Ask for pointers on finding a good experiment topic for the specific assignment. You can also ask them to suggest some other ways you could generate ideas or inspiration.
While it can feel intimidating to ask for help, your instructor should be more than happy to provide some guidance. Plus, they might offer insights that you wouldn't have gathered on your own. Your instructor probably has lots of ideas for psychology experiments that would be worth exploring.
If you need to design or conduct psychology experiments, there are plenty of great ideas (both old and new) for you to explore. Consider an idea from the list above or turn some of your own questions about the human mind and behavior into an experiment.
Before you dive in, make sure that you are observing the guidelines provided by your instructor and always obtain the appropriate permission before conducting any research with human or animal subjects.
Frequently Asked Questions
Finding a topic for a research paper is much like finding an idea for an experiment. Start by considering your own interests, or browse though your textbooks for inspiration. You might also consider looking at online news stories or journal articles as a source of inspiration.
Three of the most classic social psychology experiments are:
- The Asch Conformity Experiment : This experiment involved seeing if people would conform to group pressure when rating the length of a line.
- The Milgram Obedience Experiment : This experiment involved ordering participants to deliver what they thought was a painful shock to another person.
- The Stanford Prison Experiment : This experiment involved students replicating a prison environment to see how it would affect participant behavior.
Jakovljević T, Janković MM, Savić AM, et al. The effect of colour on reading performance in children, measured by a sensor hub: From the perspective of gender . PLoS One . 2021;16(6):e0252622. doi:10.1371/journal.pone.0252622
Greenberg DM, et al. Musical preferences are linked to cognitive styles . PLoS One. 2015;10(7). doi:10.1371/journal.pone.0131151
Kurt S, Osueke KK. The effects of color on the moods of college students . Sage. 2014;4(1). doi:10.1177/2158244014525423
Hartline-Grafton H, Levin M. Breakfast and School-Related Outcomes in Children and Adolescents in the US: A Literature Review and its Implications for School Nutrition Policy . Curr Nutr Rep . 2022;11(4):653-664. doi:10.1007/s13668-022-00434-z
By Kendra Cherry, MSEd Kendra Cherry, MS, is a psychosocial rehabilitation specialist, psychology educator, and author of the "Everything Psychology Book."

How Do You Get Psychology Experiments to Work?
New research addresses informal practices that make studies work..
Posted September 29, 2019
- What Is a Career
- Take our Procrastination Test
- Find a career counselor near me

How do you get a psychology experiment to work? A new paper in the journal Collabra: Psychology by Jonna Brenninkmeijer and colleagues interviews researchers about the informal knowledge they need to get their experiments to work. They describe things like projecting a professional appearance, designing materials to be easy to read, and making sure that people who experienced an experimental manipulation provide responses on the outcome of interest soon afterwards (e.g., not having too many filler tasks). As someone who has worked in several psychology labs, these sound like pretty standard measures taken by many researchers. But an issue that comes up in the manuscript is that psychologists don’t really know whether these steps matter. They think “you have to do it this way to get ‘quality data’ from an experiment” but this belief is just based on intuition . They haven’t systematically checked whether professionally dressed research assistants, nicely designed materials, or time spent on filler tasks matters for an experiment.
This can be a problem, because not everyone agrees what the right “standard operating procedures” for getting good data are. One researcher says you should always start by asking about demographics, then move on to more psychological questions (e.g., about attitudes, emotions, etc.). One research says the opposite, arguing that demographics should always go last. When describing professionalism, some researchers say that an experimenter should be slightly removed, not engaging in too much chit chat with participants. Later on, researchers argue that some experiments require “people skills” from an experimenter and lots of talking with participants to put them at ease. A social psychologist who does lab experiments says he tries to “make it lively” for participants, which is mostly done in the way he delivers instructions.
These ad hoc techniques for trying to get an experiment to work make intuitive sense, and have some justification in the philosophy of science. Ian Hacking describes physics experiments as hard to get right. The typical high schooler finds a science lab hard precisely because there is a certain amount of implicit knowledge needed to stain a cell properly or to know where to look in a microscope to see a structure. People critical of the value of replication studies often latch on to this point. There are all kinds of little decisions that a researcher makes when setting up an experiment, and many of these are the kinds of informal things described in Brenninkmeijer and colleagues’ works. Couldn’t it be the case that when a new study fails to replicate a published effect, the reason is that the experimenter missed one of these small, informal steps that was crucial for getting high quality data? Couldn’t they be like the high schooler who can’t properly stain a cell?
That can certainly happen sometimes. But always arguing that a failed replication is due to some hidden detail of an experiment that someone didn’t get right isn’t reasonable, because it implies that the core hypothesis being tested can never be wrong. In essence, it is arguing that every failed replication is due to some mistake in the informal parts of running the experiments—something that’s been called the “hidden moderators” argument in the scientific debate. This argument recasts all psychology research as methodological. The underlying effect can’t be challenged; the only thing a researcher can ever claim is that a particular method doesn’t work. No researcher can ever contradict the interesting, theoretical part of another researcher’s work—the actual psychology.
In case you think I’m taking the argument too far, I will point you to the work of influential psychologists William McGuire. In an essay on the philosophy of science in psychology, McGuire argued, “we cannot really test a theory, because all theories are true” (p. 417). Drawing out the implications more fully, he writes:
“… if a person who apparently has been contemplating the origins of leadership says to us, ‘You know, taller people are more likely to rise to power than shorter ones,’ the statement is probably ipso facto true for having been derived. Of course, it is quite possible that some other reasonable person may come up with the opposite hypothesis that shorter people are more likely to rise to leadership. However, this is no embarrassment because not only are all hypotheses true, but so are their contraries if they too have been honestly and thoughtfully generated.” (p. 417)

So according to McGuire, the contrary hypotheses “taller people rise to power more” and “shorter people rise to power more” are both true because a psychologist came up with them. What we should do in psychology research is just accept that everyone is always right, and then look for the specific conditions that make people right. Maybe tall people succeed as CEO’s and short people succeed as movie stars. The point is that no hypothesis is ever wrong, it’s just conditional.
This leads McGuire to propose the following advice for coming up with new studies to run: “Take a very straightforward proposition (such as, ‘people like others to the extent that the others are like themselves’), reverse it by stating its contrary, and then generate the special circumstances under which the contrary would be true” (p. 417). The successful psychologist isn’t trying to build a comprehensive and precise understanding of a topic by pitting competing explanations against each other (as Platt argues good sciences do in the strong inference method). The successful psychologist is trying to come up with something counter-intuitive that they can somehow still get to come out their way.
The real work in this paradigm comes behind the scenes in tweaking the setup. McGuire argues that psychologists “expend several times as much effort in … prestudies to get the conditions right as one spends in the final study that is written up for publication” (p. 418, 2013). Of course, McGuire recognizes that this causes problems. As he notes, if we are only presenting a few clean results out of the dozens of studies that we run to get the situation just right, then we aren’t presenting the most difficult and important part of our work: systematically working out when an effect will hold.

The biggest problem comes in the way we report results. As McGuire puts it, “to find the conditions under which their outlandish, nonobvious hypothesis was indeed valid,” psychologists had to conduct lots of unreported studies and arrange conditions “often outrageously” so that “the far-out hypothesis was indeed confirmed.” But what got reported was that the general counter-intuitive statement was true, and “by implication … the obvious hypothesis was wrong.” So social psychology worked for a long time by reporting results that were exciting and counter-intuitive but misleading. Counter-intuitive statements made implying a relationship was generally true were not true in general at all. From the McGuire perspective, classic social psychology effects aren’t generalizable statements about how the world works, they are highly fragile and specific results that likely rely on very precise conditions—only some of which were reported.
Under this paradigm, McGuire was right to argue that what psychology really needed was to report the full set of studies that led up to the studies that “worked” are were reported in the journal. The problem, for McGuire, was that we weren’t willing to report our “failed experiments.” Instead, social psychologists misrepresented our process as testing a hypothesis—when really we were assuming the hypothesis was true and instead the work came in all kinds of background shenanigans to make sure it came out right. But what McGuire wouldn’t give up was the belief that psychologists coming up with theories were always right.
This perspective is frustrating because it refuses to let us compare the real hypotheses we care about. Do tall people or short people rise to power more quickly? Just saying “both are true sometimes” isn’t satisfying. What we need is some underlying theory of how to do psychology experiments so that we can isolate the particular situation we’re talking about and remove the influence of factors we don’t care about. We can begin to address this by stating our results more honestly: not saying “short people rise to leadership more” but saying that “short people rise in contexts, like Hollywood, where personal charisma matters more.”

Longer term, we want to have background knowledge—and even some theory—about where we are testing things. This is what Paul Meehl described as a “theory of the instrument.” Students who can’t properly stain a cell for observation under a microscope don’t have to guess blindly at why the process didn’t work. They can rely on some core understanding of how staining and microscopes work to guide them to the right technique.
Imagine a biologist saying that a specific cell both has a specific protein and it didn’t have the protein. We wouldn’t just say “of course! They’re both true!” We would want a frame of reference for understanding what “normal conditions” were, and we’d want to know what was the case under those normal conditions. If there were other typical conditions that changed protein composition, we’d want to check those out. Then if there were special conditions unique to this protein where it was more or less likely to want to be present, we’d want to know about those, too. In short, we wouldn’t accept the “everybody’s right in some situation” premise—we’d want a detailed theory to talk about when statements are and aren’t true.
The new paper by Brenninkmeijer and colleagues is important because it’s a first step towards gathering this kind of information on the way that psychology experiments are—and should—be run. The way we do this is by developing a detailed theory regarding how background variables—things that we don’t inherently care about, like the way experimenters explain instructions, the order of questions, and the design of materials—work, and then using this theory to minimize their influence.
At one point, the interviewers ask the researchers whether they would be interested in a handbook of informal information on how to conduct good experiments. One jokingly said Brenninkmeijer and colleagues should write this sort of handbook themselves. I hope they—or others—consider doing this. A handbook of the role of background variables would help us adjudicate claims about the validity of replications, because we wouldn’t be relying on after-the-fact, motivated claims by researchers that “of course doing an experiment in a room with a video camera wouldn’t work.” It would help us determine if the replication should be expected to work based on our understanding of the background variables. As a psychologist interested in building a deep, cumulative theory of how people work, I do not want to spend my career in McGuire’s world coming up with “outrageous” situations to support “far-out” hypotheses. I want to build the tools needed to test real, important theoretical questions. To do this, we need to start figuring out what background factors really matter in experiments, and which don’t.

Alexander Danvers, Ph.D. , is a social psychologist by training with an interdisciplinary approach to research. Currently, he works on measuring and improving mental health outcomes.
- Find a Therapist
- Find a Treatment Center
- Find a Psychiatrist
- Find a Support Group
- Find Online Therapy
- United States
- Brooklyn, NY
- Chicago, IL
- Houston, TX
- Los Angeles, CA
- New York, NY
- Portland, OR
- San Diego, CA
- San Francisco, CA
- Seattle, WA
- Washington, DC
- Asperger's
- Bipolar Disorder
- Chronic Pain
- Eating Disorders
- Passive Aggression
- Personality
- Goal Setting
- Positive Psychology
- Stopping Smoking
- Low Sexual Desire
- Relationships
- Child Development
- Self Tests NEW
- Therapy Center
- Diagnosis Dictionary
- Types of Therapy

Sticking up for yourself is no easy task. But there are concrete skills you can use to hone your assertiveness and advocate for yourself.
- Emotional Intelligence
- Gaslighting
- Affective Forecasting
- Neuroscience
- SUGGESTED TOPICS
- The Magazine
- Newsletters
- Managing Yourself
- Managing Teams
- Work-life Balance
- The Big Idea
- Data & Visuals
- Reading Lists
- Case Selections
- HBR Learning
- Topic Feeds
- Account Settings
- Email Preferences
The Value of Belonging at Work
- Evan W. Carr,
- Andrew Reece,
- Gabriella Rosen Kellerman,
- Alexi Robichaux

It’s good for people — and for the bottom line.
Social belonging is a fundamental human need, hardwired into our DNA. And yet, 40% of people say that they feel isolated at work, and the result has been lower organizational commitment and engagement. U.S. businesses spend nearly $8 billion each year on diversity and inclusion (D&I) trainings that miss the mark because they neglect our need to feel included. Recent research from Betterup shows that if workers feel like they belong, companies reap substantial bottom-line benefits: better job performance, lower turnover risk, and fewer sick days. Experiments show that individuals coping with left-out feelings can prevent them by gaining perspective from others, mentoring those in a similar condition, and thinking of strategies for improving the situation. For team leaders and colleagues who want to help others feel included, serving as a fair-minded ally — someone who treats everyone equally — can offer protection to buffer the exclusionary behavior of others.
Social belonging is a fundamental human need, hardwired into our DNA. And yet, 40% of people say that they feel isolated at work, and the result has been lower organizational commitment and engagement . In a nutshell, companies are blowing it. U.S. businesses spend nearly 8 billion dollars each year on diversity and inclusion (D&I) trainings that miss the mark because they neglect our need to feel included .
- EC Evan W. Carr is a quantitative behavioral scientist at BetterUp.
- AR Andrew Reece is a behavioral data scientist at BetterUp.
- GK Gabriella Rosen Kellerman is a physician, the chief product officer, and the chief innovation officer at BetterUp, a coaching platform in San Francisco.
- AR Alexi Robichaux is co-founder and CEO of BetterUp.
Partner Center

21 13. Experimental design
Chapter outline.
- What is an experiment and when should you use one? (8 minute read)
- True experimental designs (7 minute read)
- Quasi-experimental designs (8 minute read)
- Non-experimental designs (5 minute read)
- Critical, ethical, and critical considerations (5 minute read)
Content warning : examples in this chapter contain references to non-consensual research in Western history, including experiments conducted during the Holocaust and on African Americans (section 13.6).
13.1 What is an experiment and when should you use one?
Learning objectives.
Learners will be able to…
- Identify the characteristics of a basic experiment
- Describe causality in experimental design
- Discuss the relationship between dependent and independent variables in experiments
- Explain the links between experiments and generalizability of results
- Describe advantages and disadvantages of experimental designs
The basics of experiments
The first experiment I can remember using was for my fourth grade science fair. I wondered if latex- or oil-based paint would hold up to sunlight better. So, I went to the hardware store and got a few small cans of paint and two sets of wooden paint sticks. I painted one with oil-based paint and the other with latex-based paint of different colors and put them in a sunny spot in the back yard. My hypothesis was that the oil-based paint would fade the most and that more fading would happen the longer I left the paint sticks out. (I know, it’s obvious, but I was only 10.)
I checked in on the paint sticks every few days for a month and wrote down my observations. The first part of my hypothesis ended up being wrong—it was actually the latex-based paint that faded the most. But the second part was right, and the paint faded more and more over time. This is a simple example, of course—experiments get a heck of a lot more complex than this when we’re talking about real research.
Merriam-Webster defines an experiment as “an operation or procedure carried out under controlled conditions in order to discover an unknown effect or law, to test or establish a hypothesis, or to illustrate a known law.” Each of these three components of the definition will come in handy as we go through the different types of experimental design in this chapter. Most of us probably think of the physical sciences when we think of experiments, and for good reason—these experiments can be pretty flashy! But social science and psychological research follow the same scientific methods, as we’ve discussed in this book.
As the video discusses, experiments can be used in social sciences just like they can in physical sciences. It makes sense to use an experiment when you want to determine the cause of a phenomenon with as much accuracy as possible. Some types of experimental designs do this more precisely than others, as we’ll see throughout the chapter. If you’ll remember back to Chapter 11 and the discussion of validity, experiments are the best way to ensure internal validity, or the extent to which a change in your independent variable causes a change in your dependent variable.
Experimental designs for research projects are most appropriate when trying to uncover or test a hypothesis about the cause of a phenomenon, so they are best for explanatory research questions. As we’ll learn throughout this chapter, different circumstances are appropriate for different types of experimental designs. Each type of experimental design has advantages and disadvantages, and some are better at controlling the effect of extraneous variables —those variables and characteristics that have an effect on your dependent variable, but aren’t the primary variable whose influence you’re interested in testing. For example, in a study that tries to determine whether aspirin lowers a person’s risk of a fatal heart attack, a person’s race would likely be an extraneous variable because you primarily want to know the effect of aspirin.
In practice, many types of experimental designs can be logistically challenging and resource-intensive. As practitioners, the likelihood that we will be involved in some of the types of experimental designs discussed in this chapter is fairly low. However, it’s important to learn about these methods, even if we might not ever use them, so that we can be thoughtful consumers of research that uses experimental designs.
While we might not use all of these types of experimental designs, many of us will engage in evidence-based practice during our time as social workers. A lot of research developing evidence-based practice, which has a strong emphasis on generalizability, will use experimental designs. You’ve undoubtedly seen one or two in your literature search so far.
The logic of experimental design
How do we know that one phenomenon causes another? The complexity of the social world in which we practice and conduct research means that causes of social problems are rarely cut and dry. Uncovering explanations for social problems is key to helping clients address them, and experimental research designs are one road to finding answers.
As you read about in Chapter 8 (and as we’ll discuss again in Chapter 15 ), just because two phenomena are related in some way doesn’t mean that one causes the other. Ice cream sales increase in the summer, and so does the rate of violent crime; does that mean that eating ice cream is going to make me murder someone? Obviously not, because ice cream is great. The reality of that relationship is far more complex—it could be that hot weather makes people more irritable and, at times, violent, while also making people want ice cream. More likely, though, there are other social factors not accounted for in the way we just described this relationship.
Experimental designs can help clear up at least some of this fog by allowing researchers to isolate the effect of interventions on dependent variables by controlling extraneous variables . In true experimental design (discussed in the next section) and some quasi-experimental designs, researchers accomplish this w ith the control group and the experimental group . (The experimental group is sometimes called the “treatment group,” but we will call it the experimental group in this chapter.) The control group does not receive the intervention you are testing (they may receive no intervention or what is known as “treatment as usual”), while the experimental group does. (You will hopefully remember our earlier discussion of control variables in Chapter 8 —conceptually, the use of the word “control” here is the same.)

In a well-designed experiment, your control group should look almost identical to your experimental group in terms of demographics and other relevant factors. What if we want to know the effect of CBT on social anxiety, but we have learned in prior research that men tend to have a more difficult time overcoming social anxiety? We would want our control and experimental groups to have a similar gender mix because it would limit the effect of gender on our results, since ostensibly, both groups’ results would be affected by gender in the same way. If your control group has 5 women, 6 men, and 4 non-binary people, then your experimental group should be made up of roughly the same gender balance to help control for the influence of gender on the outcome of your intervention. (In reality, the groups should be similar along other dimensions, as well, and your group will likely be much larger.) The researcher will use the same outcome measures for both groups and compare them, and assuming the experiment was designed correctly, get a pretty good answer about whether the intervention had an effect on social anxiety.
You will also hear people talk about comparison groups , which are similar to control groups. The primary difference between the two is that a control group is populated using random assignment, but a comparison group is not. Random assignment entails using a random process to decide which participants are put into the control or experimental group (which participants receive an intervention and which do not). By randomly assigning participants to a group, you can reduce the effect of extraneous variables on your research because there won’t be a systematic difference between the groups.
Do not confuse random assignment with random sampling. Random sampling is a method for selecting a sample from a population, and is rarely used in psychological research. Random assignment is a method for assigning participants in a sample to the different conditions, and it is an important element of all experimental research in psychology and other related fields. Random sampling also helps a great deal with generalizability , whereas random assignment increases internal validity .
We have already learned about internal validity in Chapter 11 . The use of an experimental design will bolster internal validity since it works to isolate causal relationships. As we will see in the coming sections, some types of experimental design do this more effectively than others. It’s also worth considering that true experiments, which most effectively show causality , are often difficult and expensive to implement. Although other experimental designs aren’t perfect, they still produce useful, valid evidence and may be more feasible to carry out.
Key Takeaways
- Experimental designs are useful for establishing causality, but some types of experimental design do this better than others.
- Experiments help researchers isolate the effect of the independent variable on the dependent variable by controlling for the effect of extraneous variables .
- Experiments use a control/comparison group and an experimental group to test the effects of interventions. These groups should be as similar to each other as possible in terms of demographics and other relevant factors.
- True experiments have control groups with randomly assigned participants, while other types of experiments have comparison groups to which participants are not randomly assigned.
- Think about the research project you’ve been designing so far. How might you use a basic experiment to answer your question? If your question isn’t explanatory, try to formulate a new explanatory question and consider the usefulness of an experiment.
- Why is establishing a simple relationship between two variables not indicative of one causing the other?
13.2 True experimental design
- Describe a true experimental design in social work research
- Understand the different types of true experimental designs
- Determine what kinds of research questions true experimental designs are suited for
- Discuss advantages and disadvantages of true experimental designs
True experimental design , often considered to be the “gold standard” in research designs, is thought of as one of the most rigorous of all research designs. In this design, one or more independent variables are manipulated by the researcher (as treatments), subjects are randomly assigned to different treatment levels (random assignment), and the results of the treatments on outcomes (dependent variables) are observed. The unique strength of experimental research is its internal validity and its ability to establish ( causality ) through treatment manipulation, while controlling for the effects of extraneous variable. Sometimes the treatment level is no treatment, while other times it is simply a different treatment than that which we are trying to evaluate. For example, we might have a control group that is made up of people who will not receive any treatment for a particular condition. Or, a control group could consist of people who consent to treatment with DBT when we are testing the effectiveness of CBT.
As we discussed in the previous section, a true experiment has a control group with participants randomly assigned , and an experimental group . This is the most basic element of a true experiment. The next decision a researcher must make is when they need to gather data during their experiment. Do they take a baseline measurement and then a measurement after treatment, or just a measurement after treatment, or do they handle measurement another way? Below, we’ll discuss the three main types of true experimental designs. There are sub-types of each of these designs, but here, we just want to get you started with some of the basics.
Using a true experiment in social work research is often pretty difficult, since as I mentioned earlier, true experiments can be quite resource intensive. True experiments work best with relatively large sample sizes, and random assignment, a key criterion for a true experimental design, is hard (and unethical) to execute in practice when you have people in dire need of an intervention. Nonetheless, some of the strongest evidence bases are built on true experiments.
For the purposes of this section, let’s bring back the example of CBT for the treatment of social anxiety. We have a group of 500 individuals who have agreed to participate in our study, and we have randomly assigned them to the control and experimental groups. The folks in the experimental group will receive CBT, while the folks in the control group will receive more unstructured, basic talk therapy. These designs, as we talked about above, are best suited for explanatory research questions.
Before we get started, take a look at the table below. When explaining experimental research designs, we often use diagrams with abbreviations to visually represent the experiment. Table 13.1 starts us off by laying out what each of the abbreviations mean.
| R | Randomly assigned group (control/comparison or experimental) |
| O | Observation/measurement taken of dependent variable |
| X | Intervention or treatment |
| X | Experimental or new intervention |
| X | Typical intervention/treatment as usual |
| A, B, C, etc. | Denotes different groups (control/comparison and experimental) |
Pretest and post-test control group design
In pretest and post-test control group design , participants are given a pretest of some kind to measure their baseline state before their participation in an intervention. In our social anxiety experiment, we would have participants in both the experimental and control groups complete some measure of social anxiety—most likely an established scale and/or a structured interview—before they start their treatment. As part of the experiment, we would have a defined time period during which the treatment would take place (let’s say 12 weeks, just for illustration). At the end of 12 weeks, we would give both groups the same measure as a post-test .

In the diagram, RA (random assignment group A) is the experimental group and RB is the control group. O 1 denotes the pre-test, X e denotes the experimental intervention, and O 2 denotes the post-test. Let’s look at this diagram another way, using the example of CBT for social anxiety that we’ve been talking about.

In a situation where the control group received treatment as usual instead of no intervention, the diagram would look this way, with X i denoting treatment as usual (Figure 13.3).
Hopefully, these diagrams provide you a visualization of how this type of experiment establishes time order , a key component of a causal relationship. Did the change occur after the intervention? Assuming there is a change in the scores between the pretest and post-test, we would be able to say that yes, the change did occur after the intervention. Causality can’t exist if the change happened before the intervention—this would mean that something else led to the change, not our intervention.
Post-test only control group design
Post-test only control group design involves only giving participants a post-test, just like it sounds (Figure 13.4).
But why would you use this design instead of using a pretest/post-test design? One reason could be the testing effect that can happen when research participants take a pretest. In research, the testing effect refers to “measurement error related to how a test is given; the conditions of the testing, including environmental conditions; and acclimation to the test itself” (Engel & Schutt, 2017, p. 444) [1] (When we say “measurement error,” all we mean is the accuracy of the way we measure the dependent variable.) Figure 13.4 is a visualization of this type of experiment. The testing effect isn’t always bad in practice—our initial assessments might help clients identify or put into words feelings or experiences they are having when they haven’t been able to do that before. In research, however, we might want to control its effects to isolate a cleaner causal relationship between intervention and outcome.
Going back to our CBT for social anxiety example, we might be concerned that participants would learn about social anxiety symptoms by virtue of taking a pretest. They might then identify that they have those symptoms on the post-test, even though they are not new symptoms for them. That could make our intervention look less effective than it actually is.
However, without a baseline measurement establishing causality can be more difficult. If we don’t know someone’s state of mind before our intervention, how do we know our intervention did anything at all? Establishing time order is thus a little more difficult. You must balance this consideration with the benefits of this type of design.
Solomon four group design
One way we can possibly measure how much the testing effect might change the results of the experiment is with the Solomon four group design. Basically, as part of this experiment, you have two control groups and two experimental groups. The first pair of groups receives both a pretest and a post-test. The other pair of groups receives only a post-test (Figure 13.5). This design helps address the problem of establishing time order in post-test only control group designs.
For our CBT project, we would randomly assign people to four different groups instead of just two. Groups A and B would take our pretest measures and our post-test measures, and groups C and D would take only our post-test measures. We could then compare the results among these groups and see if they’re significantly different between the folks in A and B, and C and D. If they are, we may have identified some kind of testing effect, which enables us to put our results into full context. We don’t want to draw a strong causal conclusion about our intervention when we have major concerns about testing effects without trying to determine the extent of those effects.
Solomon four group designs are less common in social work research, primarily because of the logistics and resource needs involved. Nonetheless, this is an important experimental design to consider when we want to address major concerns about testing effects.
- True experimental design is best suited for explanatory research questions.
- True experiments require random assignment of participants to control and experimental groups.
- Pretest/post-test research design involves two points of measurement—one pre-intervention and one post-intervention.
- Post-test only research design involves only one point of measurement—post-intervention. It is a useful design to minimize the effect of testing effects on our results.
- Solomon four group research design involves both of the above types of designs, using 2 pairs of control and experimental groups. One group receives both a pretest and a post-test, while the other receives only a post-test. This can help uncover the influence of testing effects.
- Think about a true experiment you might conduct for your research project. Which design would be best for your research, and why?
- What challenges or limitations might make it unrealistic (or at least very complicated!) for you to carry your true experimental design in the real-world as a student researcher?
- What hypothesis(es) would you test using this true experiment?
13.4 Quasi-experimental designs
- Describe a quasi-experimental design in social work research
- Understand the different types of quasi-experimental designs
- Determine what kinds of research questions quasi-experimental designs are suited for
- Discuss advantages and disadvantages of quasi-experimental designs
Quasi-experimental designs are a lot more common in social work research than true experimental designs. Although quasi-experiments don’t do as good a job of giving us robust proof of causality , they still allow us to establish time order , which is a key element of causality. The prefix quasi means “resembling,” so quasi-experimental research is research that resembles experimental research, but is not true experimental research. Nonetheless, given proper research design, quasi-experiments can still provide extremely rigorous and useful results.
There are a few key differences between true experimental and quasi-experimental research. The primary difference between quasi-experimental research and true experimental research is that quasi-experimental research does not involve random assignment to control and experimental groups. Instead, we talk about comparison groups in quasi-experimental research instead. As a result, these types of experiments don’t control the effect of extraneous variables as well as a true experiment.
Quasi-experiments are most likely to be conducted in field settings in which random assignment is difficult or impossible. They are often conducted to evaluate the effectiveness of a treatment—perhaps a type of psychotherapy or an educational intervention. We’re able to eliminate some threats to internal validity, but we can’t do this as effectively as we can with a true experiment. Realistically, our CBT-social anxiety project is likely to be a quasi experiment, based on the resources and participant pool we’re likely to have available.
It’s important to note that not all quasi-experimental designs have a comparison group. There are many different kinds of quasi-experiments, but we will discuss the three main types below: nonequivalent comparison group designs, time series designs, and ex post facto comparison group designs.
Nonequivalent comparison group design
You will notice that this type of design looks extremely similar to the pretest/post-test design that we discussed in section 13.3. But instead of random assignment to control and experimental groups, researchers use other methods to construct their comparison and experimental groups. A diagram of this design will also look very similar to pretest/post-test design, but you’ll notice we’ve removed the “R” from our groups, since they are not randomly assigned (Figure 13.6).

Researchers using this design select a comparison group that’s as close as possible based on relevant factors to their experimental group. Engel and Schutt (2017) [2] identify two different selection methods:
- Individual matching : Researchers take the time to match individual cases in the experimental group to similar cases in the comparison group. It can be difficult, however, to match participants on all the variables you want to control for.
- Aggregate matching : Instead of trying to match individual participants to each other, researchers try to match the population profile of the comparison and experimental groups. For example, researchers would try to match the groups on average age, gender balance, or median income. This is a less resource-intensive matching method, but researchers have to ensure that participants aren’t choosing which group (comparison or experimental) they are a part of.
As we’ve already talked about, this kind of design provides weaker evidence that the intervention itself leads to a change in outcome. Nonetheless, we are still able to establish time order using this method, and can thereby show an association between the intervention and the outcome. Like true experimental designs, this type of quasi-experimental design is useful for explanatory research questions.
What might this look like in a practice setting? Let’s say you’re working at an agency that provides CBT and other types of interventions, and you have identified a group of clients who are seeking help for social anxiety, as in our earlier example. Once you’ve obtained consent from your clients, you can create a comparison group using one of the matching methods we just discussed. If the group is small, you might match using individual matching, but if it’s larger, you’ll probably sort people by demographics to try to get similar population profiles. (You can do aggregate matching more easily when your agency has some kind of electronic records or database, but it’s still possible to do manually.)
Time series design
Another type of quasi-experimental design is a time series design. Unlike other types of experimental design, time series designs do not have a comparison group. A time series is a set of measurements taken at intervals over a period of time (Figure 13.7). Proper time series design should include at least three pre- and post-intervention measurement points. While there are a few types of time series designs, we’re going to focus on the most common: interrupted time series design.

But why use this method? Here’s an example. Let’s think about elementary student behavior throughout the school year. As anyone with children or who is a teacher knows, kids get very excited and animated around holidays, days off, or even just on a Friday afternoon. This fact might mean that around those times of year, there are more reports of disruptive behavior in classrooms. What if we took our one and only measurement in mid-December? It’s possible we’d see a higher-than-average rate of disruptive behavior reports, which could bias our results if our next measurement is around a time of year students are in a different, less excitable frame of mind. When we take multiple measurements throughout the first half of the school year, we can establish a more accurate baseline for the rate of these reports by looking at the trend over time.
We may want to test the effect of extended recess times in elementary school on reports of disruptive behavior in classrooms. When students come back after the winter break, the school extends recess by 10 minutes each day (the intervention), and the researchers start tracking the monthly reports of disruptive behavior again. These reports could be subject to the same fluctuations as the pre-intervention reports, and so we once again take multiple measurements over time to try to control for those fluctuations.
This method improves the extent to which we can establish causality because we are accounting for a major extraneous variable in the equation—the passage of time. On its own, it does not allow us to account for other extraneous variables, but it does establish time order and association between the intervention and the trend in reports of disruptive behavior. Finding a stable condition before the treatment that changes after the treatment is evidence for causality between treatment and outcome.
Ex post facto comparison group design
Ex post facto (Latin for “after the fact”) designs are extremely similar to nonequivalent comparison group designs. There are still comparison and experimental groups, pretest and post-test measurements, and an intervention. But in ex post facto designs, participants are assigned to the comparison and experimental groups once the intervention has already happened. This type of design often occurs when interventions are already up and running at an agency and the agency wants to assess effectiveness based on people who have already completed treatment.
In most clinical agency environments, social workers conduct both initial and exit assessments, so there are usually some kind of pretest and post-test measures available. We also typically collect demographic information about our clients, which could allow us to try to use some kind of matching to construct comparison and experimental groups.
In terms of internal validity and establishing causality, ex post facto designs are a bit of a mixed bag. The ability to establish causality depends partially on the ability to construct comparison and experimental groups that are demographically similar so we can control for these extraneous variables .
Quasi-experimental designs are common in social work intervention research because, when designed correctly, they balance the intense resource needs of true experiments with the realities of research in practice. They still offer researchers tools to gather robust evidence about whether interventions are having positive effects for clients.
- Quasi-experimental designs are similar to true experiments, but do not require random assignment to experimental and control groups.
- In quasi-experimental projects, the group not receiving the treatment is called the comparison group, not the control group.
- Nonequivalent comparison group design is nearly identical to pretest/post-test experimental design, but participants are not randomly assigned to the experimental and control groups. As a result, this design provides slightly less robust evidence for causality.
- Nonequivalent groups can be constructed by individual matching or aggregate matching .
- Time series design does not have a control or experimental group, and instead compares the condition of participants before and after the intervention by measuring relevant factors at multiple points in time. This allows researchers to mitigate the error introduced by the passage of time.
- Ex post facto comparison group designs are also similar to true experiments, but experimental and comparison groups are constructed after the intervention is over. This makes it more difficult to control for the effect of extraneous variables, but still provides useful evidence for causality because it maintains the time order[ /pb_glossary] of the experiment.
- Think back to the experiment you considered for your research project in Section 13.3. Now that you know more about quasi-experimental designs, do you still think it's a true experiment? Why or why not?
- What should you consider when deciding whether an experimental or quasi-experimental design would be more feasible or fit your research question better?
13.5 Non-experimental designs
Learners will be able to...
- Describe non-experimental designs in social work research
- Discuss how non-experimental research differs from true and quasi-experimental research
- Demonstrate an understanding the different types of non-experimental designs
- Determine what kinds of research questions non-experimental designs are suited for
- Discuss advantages and disadvantages of non-experimental designs
The previous sections have laid out the basics of some rigorous approaches to establish that an intervention is responsible for changes we observe in research participants. This type of evidence is extremely important to build an evidence base for social work interventions, but it's not the only type of evidence to consider. We will discuss qualitative methods, which provide us with rich, contextual information, in Part 4 of this text. The designs we'll talk about in this section are sometimes used in [pb_glossary id="851"] qualitative research, but in keeping with our discussion of experimental design so far, we're going to stay in the quantitative research realm for now. Non-experimental is also often a stepping stone for more rigorous experimental design in the future, as it can help test the feasibility of your research.
In general, non-experimental designs do not strongly support causality and don't address threats to internal validity. However, that's not really what they're intended for. Non-experimental designs are useful for a few different types of research, including explanatory questions in program evaluation. Certain types of non-experimental design are also helpful for researchers when they are trying to develop a new assessment or scale. Other times, researchers or agency staff did not get a chance to gather any assessment information before an intervention began, so a pretest/post-test design is not possible.

A significant benefit of these types of designs is that they're pretty easy to execute in a practice or agency setting. They don't require a comparison or control group, and as Engel and Schutt (2017) [3] point out, they "flow from a typical practice model of assessment, intervention, and evaluating the impact of the intervention" (p. 177). Thus, these designs are fairly intuitive for social workers, even when they aren't expert researchers. Below, we will go into some detail about the different types of non-experimental design.
One group pretest/post-test design
Also known as a before-after one-group design, this type of research design does not have a comparison group and everyone who participates in the research receives the intervention (Figure 13.8). This is a common type of design in program evaluation in the practice world. Controlling for extraneous variables is difficult or impossible in this design, but given that it is still possible to establish some measure of time order, it does provide weak support for causality.

Imagine, for example, a researcher who is interested in the effectiveness of an anti-drug education program on elementary school students’ attitudes toward illegal drugs. The researcher could assess students' attitudes about illegal drugs (O 1 ), implement the anti-drug program (X), and then immediately after the program ends, the researcher could once again measure students’ attitudes toward illegal drugs (O 2 ). You can see how this would be relatively simple to do in practice, and have probably been involved in this type of research design yourself, even if informally. But hopefully, you can also see that this design would not provide us with much evidence for causality because we have no way of controlling for the effect of extraneous variables. A lot of things could have affected any change in students' attitudes—maybe girls already had different attitudes about illegal drugs than children of other genders, and when we look at the class's results as a whole, we couldn't account for that influence using this design.
All of that doesn't mean these results aren't useful, however. If we find that children's attitudes didn't change at all after the drug education program, then we need to think seriously about how to make it more effective or whether we should be using it at all. (This immediate, practical application of our results highlights a key difference between program evaluation and research, which we will discuss in Chapter 23 .)
After-only design
As the name suggests, this type of non-experimental design involves measurement only after an intervention. There is no comparison or control group, and everyone receives the intervention. I have seen this design repeatedly in my time as a program evaluation consultant for nonprofit organizations, because often these organizations realize too late that they would like to or need to have some sort of measure of what effect their programs are having.
Because there is no pretest and no comparison group, this design is not useful for supporting causality since we can't establish the time order and we can't control for extraneous variables. However, that doesn't mean it's not useful at all! Sometimes, agencies need to gather information about how their programs are functioning. A classic example of this design is satisfaction surveys—realistically, these can only be administered after a program or intervention. Questions regarding satisfaction, ease of use or engagement, or other questions that don't involve comparisons are best suited for this type of design.
Static-group design
A final type of non-experimental research is the static-group design. In this type of research, there are both comparison and experimental groups, which are not randomly assigned. There is no pretest, only a post-test, and the comparison group has to be constructed by the researcher. Sometimes, researchers will use matching techniques to construct the groups, but often, the groups are constructed by convenience of who is being served at the agency.
Non-experimental research designs are easy to execute in practice, but we must be cautious about drawing causal conclusions from the results. A positive result may still suggest that we should continue using a particular intervention (and no result or a negative result should make us reconsider whether we should use that intervention at all). You have likely seen non-experimental research in your daily life or at your agency, and knowing the basics of how to structure such a project will help you ensure you are providing clients with the best care possible.
- Non-experimental designs are useful for describing phenomena, but cannot demonstrate causality.
- After-only designs are often used in agency and practice settings because practitioners are often not able to set up pre-test/post-test designs.
- Non-experimental designs are useful for explanatory questions in program evaluation and are helpful for researchers when they are trying to develop a new assessment or scale.
- Non-experimental designs are well-suited to qualitative methods.
- If you were to use a non-experimental design for your research project, which would you choose? Why?
- Have you conducted non-experimental research in your practice or professional life? Which type of non-experimental design was it?
13.6 Critical, ethical, and cultural considerations
- Describe critiques of experimental design
- Identify ethical issues in the design and execution of experiments
- Identify cultural considerations in experimental design
As I said at the outset, experiments, and especially true experiments, have long been seen as the gold standard to gather scientific evidence. When it comes to research in the biomedical field and other physical sciences, true experiments are subject to far less nuance than experiments in the social world. This doesn't mean they are easier—just subject to different forces. However, as a society, we have placed the most value on quantitative evidence obtained through empirical observation and especially experimentation.
Major critiques of experimental designs tend to focus on true experiments, especially randomized controlled trials (RCTs), but many of these critiques can be applied to quasi-experimental designs, too. Some researchers, even in the biomedical sciences, question the view that RCTs are inherently superior to other types of quantitative research designs. RCTs are far less flexible and have much more stringent requirements than other types of research. One seemingly small issue, like incorrect information about a research participant, can derail an entire RCT. RCTs also cost a great deal of money to implement and don't reflect “real world” conditions. The cost of true experimental research or RCTs also means that some communities are unlikely to ever have access to these research methods. It is then easy for people to dismiss their research findings because their methods are seen as "not rigorous."
Obviously, controlling outside influences is important for researchers to draw strong conclusions, but what if those outside influences are actually important for how an intervention works? Are we missing really important information by focusing solely on control in our research? Is a treatment going to work the same for white women as it does for indigenous women? With the myriad effects of our societal structures, you should be very careful ever assuming this will be the case. This doesn't mean that cultural differences will negate the effect of an intervention; instead, it means that you should remember to practice cultural humility implementing all interventions, even when we "know" they work.
How we build evidence through experimental research reveals a lot about our values and biases, and historically, much experimental research has been conducted on white people, and especially white men. [4] This makes sense when we consider the extent to which the sciences and academia have historically been dominated by white patriarchy. This is especially important for marginalized groups that have long been ignored in research literature, meaning they have also been ignored in the development of interventions and treatments that are accepted as "effective." There are examples of marginalized groups being experimented on without their consent, like the Tuskegee Experiment or Nazi experiments on Jewish people during World War II. We cannot ignore the collective consciousness situations like this can create about experimental research for marginalized groups.
None of this is to say that experimental research is inherently bad or that you shouldn't use it. Quite the opposite—use it when you can, because there are a lot of benefits, as we learned throughout this chapter. As a social work researcher, you are uniquely positioned to conduct experimental research while applying social work values and ethics to the process and be a leader for others to conduct research in the same framework. It can conflict with our professional ethics, especially respect for persons and beneficence, if we do not engage in experimental research with our eyes wide open. We also have the benefit of a great deal of practice knowledge that researchers in other fields have not had the opportunity to get. As with all your research, always be sure you are fully exploring the limitations of the research.
- While true experimental research gathers strong evidence, it can also be inflexible, expensive, and overly simplistic in terms of important social forces that affect the resources.
- Marginalized communities' past experiences with experimental research can affect how they respond to research participation.
- Social work researchers should use both their values and ethics, and their practice experiences, to inform research and push other researchers to do the same.
- Think back to the true experiment you sketched out in the exercises for Section 13.3. Are there cultural or historical considerations you hadn't thought of with your participant group? What are they? Does this change the type of experiment you would want to do?
- How can you as a social work researcher encourage researchers in other fields to consider social work ethics and values in their experimental research?
- Engel, R. & Schutt, R. (2016). The practice of research in social work. Thousand Oaks, CA: SAGE Publications, Inc. ↵
- Sullivan, G. M. (2011). Getting off the “gold standard”: Randomized controlled trials and education research. Journal of Graduate Medical Education , 3 (3), 285-289. ↵
an operation or procedure carried out under controlled conditions in order to discover an unknown effect or law, to test or establish a hypothesis, or to illustrate a known law.
explains why particular phenomena work in the way that they do; answers “why” questions
variables and characteristics that have an effect on your outcome, but aren't the primary variable whose influence you're interested in testing.
the group of participants in our study who do not receive the intervention we are researching in experiments with random assignment
in experimental design, the group of participants in our study who do receive the intervention we are researching
the group of participants in our study who do not receive the intervention we are researching in experiments without random assignment
using a random process to decide which participants are tested in which conditions
The ability to apply research findings beyond the study sample to some broader population,
Ability to say that one variable "causes" something to happen to another variable. Very important to assess when thinking about studies that examine causation such as experimental or quasi-experimental designs.
the idea that one event, behavior, or belief will result in the occurrence of another, subsequent event, behavior, or belief
An experimental design in which one or more independent variables are manipulated by the researcher (as treatments), subjects are randomly assigned to different treatment levels (random assignment), and the results of the treatments on outcomes (dependent variables) are observed
a type of experimental design in which participants are randomly assigned to control and experimental groups, one group receives an intervention, and both groups receive pre- and post-test assessments
A measure of a participant's condition before they receive an intervention or treatment.
A measure of a participant's condition after an intervention or, if they are part of the control/comparison group, at the end of an experiment.
A demonstration that a change occurred after an intervention. An important criterion for establishing causality.
an experimental design in which participants are randomly assigned to control and treatment groups, one group receives an intervention, and both groups receive only a post-test assessment
The measurement error related to how a test is given; the conditions of the testing, including environmental conditions; and acclimation to the test itself
a subtype of experimental design that is similar to a true experiment, but does not have randomly assigned control and treatment groups
In nonequivalent comparison group designs, the process by which researchers match individual cases in the experimental group to similar cases in the comparison group.
In nonequivalent comparison group designs, the process in which researchers match the population profile of the comparison and experimental groups.
a set of measurements taken at intervals over a period of time
Graduate research methods in social work Copyright © 2021 by Matthew DeCarlo, Cory Cummings, Kate Agnelli is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
- Invited Paper
- Published: 20 October 2010
Setting up social experiments: the good, the bad, and the ugly
Die Gestaltung von Sozialexperimenten: The good, the bad and the ugly
- Burt S. Barnow 1
Zeitschrift für ArbeitsmarktForschung volume 43 , pages 91–105 ( 2010 ) Cite this article
20k Accesses
5 Citations
3 Altmetric
Metrics details
It is widely agreed that randomized controlled trials – social experiments – are the gold standard for evaluating social programs. There are, however, many important issues that cannot be tested using social experiments, and often things go wrong when conducting social experiments. This paper explores these issues and offers suggestions on ways to deal with commonly encountered problems. Social experiments are preferred because random assignment assures that any differences between the treatment and control groups are due to the intervention and not some other factor; also, the results of social experiments are more easily explained and accepted by policy officials. Experimental evaluations often lack external validity and cannot control for entry effects, scale and general equilibrium effects, and aspects of the intervention that were not randomly assigned. Experiments can also lead to biased impact estimates if the control group changes its behavior or if changing the number selected changes the impact. Other problems with conducting social experiments include increased time and cost, and legal and ethical issues related to excluding people from the treatment. Things that sometimes go wrong in social experiments include programs cheating on random assignment, and participants and/or staff not understanding the intervention rules. The random assignment evaluation of the Job Training Partnership Act in the United States is used as a case study to illustrate the issues.
Zusammenfassung
Es herrscht weitestgehend Konsens darüber, dass randomisierte kontrollierte Studien – Sozialexperimente – der „Goldstandard“ für die Bewertung sozialer Programme sind. Es gibt jedoch viele wichtige Aspekte, die sich nicht durch solche Studien bewerten lassen, und bei der Durchführung dieser Studien kann oft etwas schiefgehen. Die vorliegende Arbeit untersucht diese Themen und bietet Lösungsvorschläge für häufig auftretende Probleme. Sozialexperimente werden bevorzugt, weil die Randomisierung dafür sorgt, dass alle Unterschiede zwischen der Treatmentgruppe und der Kontrollgruppe der Intervention und nicht einem anderen Faktor zuzuschreiben sind. Es fällt Politikern und Beamten auch leichter, die Ergebnisse von Sozialexperimenten zu erklären und zu akzeptieren.
Bei experimentellen Bewertungen fehlt oft die externe Validität, und es fehlt die Möglichkeit, „entry effects“, Skaleneffekte, allgemeine Gleichgewichtseffekte und nichtrandomisierte Aspekte der Intervention zu kontrollieren. Experimente können auch zu verzerrten Aussagen über die Auswirkungen führen, wenn die Kontrollgruppe ihr Verhalten ändert oder wenn eine Änderung der Anzahl der ausgewählten Personen zu einer Veränderung der Auswirkungen führt. Weitere Probleme bei Sozialexperimenten sind erhöhter Zeitaufwand und Kosten sowie juristische und ethische Fragen nach dem Ausschluss gewisser Menschen von den Maßnahmen. Fehler, die manchmal in Sozialexperimenten vorkommen, sind beispielsweise Programme, die bei der Randomisierung nicht korrekt vorgehen und Teilnehmer bzw. Mitarbeiter, die die Interventionsregeln nicht verstehen. Die randomisierte Bewertung des Job Training Partnership Act in den USA wird als Fallstudie verwendet, um diese Themen besser aufzuzeigen.
1 Introduction
Since the 1960s, social experiments have been increasingly used in the United States to determine the effects of pilots and demonstrations as well as ongoing programs in areas as diverse as education, health insurance, housing, job training, welfare cash assistance, and time of day pricing of electricity. Although social experiments have not been widely used in Europe, there is growing interest in expanding their use in evaluating social programs. Social experiments remain popular in the United States, but there has been a spirited debate in recent years regarding whether recent methodological developments, particularly propensity score matching and regression discontinuity designs, overcome many of the key objections to nonexperimental methods. This paper provides an assessment of some of the issues that arise in conducting social experiments and explains some of the things that can go wrong in conducting and interpreting the results of social experiments.
The paper first defines what is generally meant by the term social experiments and briefly reviews their use in the United States. This is followed by a discussion of the advantages of social experiments over nonexperimental methods. The next section discusses the limitations of social experiments – what we cannot learn from social experiments. Next is a section discussing some of the things that can go wrong in social experiments and limits of what we learn from them. To illustrate the problems that can arise, the penultimate section provides a case study of lessons from the National JTPA Study, a social experiment that was used to assess a large training program for disadvantaged youth and adults in the United States. The last section provides conclusions.
2 Definitions and context
As Orr ( 1999 , p. 14) notes, “The defining element of a social experiment is random assignment of some pool of individuals to two or more groups that are subject to different policy regimes.” Greenberg and Shroder ( 2004 , p. 4) note that because social experiments are intended to provide unbiased estimates of the impacts of the policy of interest, they must have four specific features:
Random assignment : Creation of at least two groups of human subjects who differ from one another by chance alone.
Policy intervention : A set of actions ensuring that different incentives, opportunities, or constraints confront the members of each of the randomly assigned groups in their daily lives.
Follow-up data collection : Measurement of market and fiscal outcomes for members of each group.
Evaluation : Application of statistical inference and informed professional judgment about the degree to which the policy interventions have caused differences in outcomes between the groups.
These four features are not particularly restrictive, and social experiments can have a large number of variations. Although we often think of random assignment taking place at the individual level, the random assignment can take place at a more aggregated level, such as the classroom, the school, the school district, political or geographic jurisdictions, or any other unit where random assignment can be feasibly carried out. Footnote 1 Second, there is no necessity for a treatment to be compared against a null treatment. In an educational or medical context, for example, it might be harmful to the control group if they receive no intervention; in such instances, the experiment can measure differential impacts where the treatment and control groups both receive treatments, but they do not receive the same treatment. Footnote 2
Third, there does not have to be a single treatment. In many instances it is sensible to develop a number of alternative treatments to which participants are assigned. In health insurance experiments, for example, there are often a number of variations we would like to test for the key aspects of the treatment. Thus, we might want to randomly assign participants to various combinations of deductable amounts and co-payment rates to see which combination leads to the best results in terms of costs and health outcomes. Likewise, in U.S. welfare experiments, the experiments frequently vary the “guarantee,” the payment received if the person does no market work, and the “implicit tax rate,” the rate at which benefits are reduced if there are earnings. Footnote 3
Fourth, social experiments can be implemented in conjunction with an ongoing program or to test a new intervention; in some instances a social experiment will test a new intervention in the context of an ongoing program. Welfare programs in the United States have been subject to several types of social experiments. In the 1960s and 1970s, a series of “negative income tax” experiments were conducted where a randomly selected group of people were diverted from regular welfare programs to entirely new welfare programs with quite different rules and benefits. During the 1980s and 1990s, many states received waivers where they were permitted to try new variations on their welfare programs so long as the new interventions were evaluated using random assignment. U.S. vocational training programs have included freestanding demonstrations with experimental designs as well as experimental evaluations of ongoing programs. Inserting an experimental design in an ongoing program is sometimes difficult, particularly if the program is an entitlement or if the authorizing legislation prohibits denying services to those who apply.
Another important distinction among experiments is that the participants can volunteer for the intervention or they can be assigned to the program. For purely voluntary programs, such as many job training programs in the United States, there is no meaningful concept of mandatory participants. For welfare programs, however, a new intervention can be voluntary in nature or it could be mandatory; the numerous welfare to work demonstration programs tested in the United States have fallen into both categories. While both mandatory and voluntary programs can be evaluated using an experimental design, the findings must be interpreted carefully. The impacts estimated for a voluntary program can not necessarily be expected to apply for a program where all welfare recipients must participate, and the impacts for a mandatory program may not apply if the same intervention were implemented as a voluntary program.
Although this paper does not focus on the ethics of random assignment, it is important to consider whether it is ethical to deny people the opportunity to participate in a social program. Both Greenberg and Shroder ( 2004 ) and Orr ( 1999 ) discuss the ethics of random assignment, but they do not do so in depth. More recently, the topic was explored in more depth in an exchange between Blustein ( 2005a , b ), Barnow ( 2005 ), Rolston ( 2005 ), and Schochet ( 2005 ). Many observers would agree that random assignment is ethical (or at least not unethical) when there is excess demand for a program and the effectiveness of the program is unknown. Blustein ( 2005a ) uses the experimental evaluation of the Job Corps to raise issues such as recruiting additional applicants so that there will be sufficient applicants to deny services to some, the fact that applicants who do not consent to the random assignment procedure are denied access to the program, and whether those randomized out of participation should receive monetary compensation. She believes that a good case can be made that the Job Corps evaluation, which included random assignment, may have been unethical, although her critics generally take issue with her points and claim that the knowledge gained is sufficient to offset any losses to the participants. As Blustein makes clear, her primary motivation in the paper is not to dispute the ethics of the Job Corps evaluation but rather to urge that ethical considerations be taken into account more fully when random assignment is being considered.
An important distinction between social experiments and randomized controlled trials that are frequently used in the fields of medicine and public health is that social experiments rarely make use of double blind or even single blind approaches. In the field of medicine, it is well known that there can often be a “placebo effect” where subjects benefit from the perception of such a treatment. Although social experiments can also be subject to similar problems, it is often difficult or impossible to keep the subjects and researchers unaware of their treatment status. A related phenomenon, known as the “Hawthorne effect,” refers to the possibility that subjects respond differently to stimuli because they are being observed. Footnote 4 The important point is that the inability to conduct double blind experiments, and even the knowledge that a subject is in an experiment can potentially lead to biased estimates of intervention impacts.
It is important to distinguish between true social experiments and “natural experiments.” The term natural experiment is sometimes used to refer to situations where random selection is not used to determine assignment to treatment status but the mechanism used, it is argued, results in treatment and comparison groups that are virtually identical. Angrist and Krueger ( 2001 ) extol the use of natural experiments in evaluations when random assignment is not feasible as a way to eliminate omitted variable bias; however, the examples they cite make use of instrumental variables rather than assuming that simple analysis of variance or ordinary least squares regression analysis can be used to obtain impact estimates:
Instruments that are used to overcome omitted variable bias are sometimes said to derive from “natural experiments.” Recent years have seen a resurgence in the use of instrumental variables in this way – that is, to exploit situations where the forces of nature or government policy have conspired to produce an environment somewhat akin to a randomized experiment. This type of application has generated some of the most provocative empirical findings in economics, along with some controversy over substance and methods.
Perhaps one of the best known examples of use of a natural experiment is the analysis by Angrist and Krueger ( 1991 ) to evaluate the effects of compulsory school attendance laws in the United States on education and earnings. In that study, the authors argue that the number of years of compulsory education (within limits) is essentially random, as it is determined by the month of birth. As Angrist and Krueger clearly imply, a natural experiment is not a classical experiment with randomized control trials, and there is no guarantee that simple analyses or more complex approaches such as instrumental variables will yield unbiased treatment estimates.
3 Why conduct social experiments?
There are a number of reasons why social experiments are preferable to nonexperimental evaluations. In the simplest terms, the objective in an evaluation of a social program is to observe the outcome for an intervention for the participants with and without the intervention. Because it is impossible to observe the same person in two states of the world at the same time, we must rely on some alternative approach to estimate what would have happened to participants had they not been in the program. The simplest and most effective way to assure comparability of the treatment and control groups is to randomly assign the potential participants to either receive the treatment or be denied the treatment; with a sufficiently large sample size, the treatment and control groups are likely to be identical on all characteristics that might affect the outcome. Nonexperimental evaluation approaches generally seek to provide unbiased and consistent impact estimates either by using mechanisms to develop comparison groups that are as similar as possible to the treatment group (e.g., propensity score matching) or by using econometric approaches to control for observed and unobserved omitted variables (e.g., fixed effects models, instrumental variables, ordinary least squares regression analysis, and regression discontinuity designs). Unfortunately, all the nonexperimental approaches require strong assumptions to assure that unbiased estimates are obtained, and these assumptions are not always testable.
Burtless ( 1995 ) describes four reasons why experimental designs are preferable to nonexperimental designs. First, random assignment assures the direction of causality. If earnings rise for the treatment group in a training program more than they do for the control group, there is no logical source of the increase other than the program. If a comparison group of individuals who chose not to enroll is used, the causality is not clear – those who enroll may be more interested in working and it is the motivation that leads to the earnings gain rather than the treatment. Burtless's second argument is related to the first – random assignment assures that there is no selection bias in the evaluation, where selection bias is defined as a likelihood that individuals with particular unobserved characteristics may be more or less likely to participate in the program. Footnote 5 The most common example of potential selection bias is that years of educational attainment are likely to be determined in part on ability, but ability is usually either not available to the evaluator or available only with measurement error.
The third argument raised by Burtless in favor of social experiments is that social experiments permit tests of interventions that do not naturally occur. Although social experiments do permit evaluations of such interventions, pilot projects and demonstrations can also be implemented without a randomly selected control group. Finally, Burtless notes that evaluations using random assignment provide findings that are more persuasive to policy makers than evaluations using nonexperimental methods. One of the best features of using random assignment is that program impacts can be observed by simply subtracting the post-program control group values from the values for the treatment group – there is no need to have faith that a fancy instrumental variables approach or a propensity score matching scheme has adequately controlled for all unobserved variables. Footnote 6 For researchers, experiments also assure that the estimates are unbiased and more precise than alternative approaches.
4 Can nonexperimental methods replicate experimental findings?
The jury is still out on this issue, and in recent years there has been a great deal of research and spirited debate about how well nonexperimental methods do at replicating experimental findings, given the data that are available. There is no question that there have been important developments in nonexperimental methods in recent years, but the question remains as to how well the methods do in replicating experimental findings and how the replication depends on the particular methods used and data available. Major contributions in recent years include the work of Heckman et al. ( 1997 ) on propensity score matching and Hahn et al. ( 2001 ) on regression discontinuity designs. Footnote 7 In this section several recent studies that have found a good match between nonexperimental methods and experimental findings are first reviewed, followed by a review of studies that were unable to replicate experimental findings. The section concludes with suggestions from the literature on conditions where nonexperimental approaches are most likely to replicate experimental findings.
Propensity score matching has been widely used in recent years when random assignment is not feasible. Heckman et al. ( 1997 ) tested a variety of propensity score matching approaches to see what approaches best mirror the experimental findings from the evaluation of the Job Training Partnership Act (JTPA) in the United States. The authors conclude that: “We determine that a regression-adjusted semiparametric conditional difference in differences matching estimator often performs the best among a class of estimators we examine, especially when omitted time-invariant characteristics are a source of bias.” The authors caution, however: “As is true of any empirical study, our findings may not generalize beyond our data.” They go on to state: “Thus, it is likely that the insights gained from our study of the JTPA programme on the effectiveness of different estimators also apply in evaluating other training programmes targeted toward disadvantaged workers.”
Another effort to see how well propensity score matching replicates experimental findings is in Dehejia and Wahba ( 2002 ). These authors are also optimistic about the capability of propensity score matching to replicate experimental impact estimates: “This paper has presented a propensity score-matching method that is able to yield accurate estimates of the treatment effect in nonexperimental settings in which the treated group differs substantially from the pool of potential comparison units.” Dehejia and Wahba ( 2002 ) use propensity score matching in trying to replicate the findings from the National Supported Work demonstration. Although the authors find that propensity score matching works well in the instance they examined, they caution that the approach critically depends on selection being based on observable variables and note that the approach may not work well when important explanatory variables are missing.
Cook et al. ( 2008 ) provide a third example of finding that nonexperimental approaches do a satisfactory job of replicating experimental findings under some circumstances. The authors looked at the studies by the type of nonexperimental approach that was used. The three studies that used a regression discontinuity design were all found to replicate the findings from the experiment. Footnote 8 They note that although regression discontinuity designs are much less efficient than experiments, as shown by Goldberger ( 1972 ), the studies they reviewed had large samples so impacts remained statistically significant. The authors find that propensity score matching works well in replicating experimental findings when key covariates are included in the propensity score modeling and where the comparison pool members come from the same geographic area as the treatment group, and they also find that propensity score matching works well when clear rules for selection into the treatment group are used and the variables that are used in selection are available for the analysis. Finally, in studies where propensity score matching was used but the covariates available did not correspond well to the selection rules and/or there was a poor geographic match, the nonexperimental results did not consistently match the experimental findings.
In another recent study, Shadish et al. ( 2008 ) conducted an intriguing experiment by randomly assigning one group of individuals to be randomly assigned to treatment status and the other to self-select one of the two treatment options (mathematics or vocabulary training). The authors found that propensity score matching greatly reduced the bias of impact estimates when the full set of available covariates was used, including pretests, but did poorly when only predictors of convenience (sex, age, marital status, and ethnicity) were used. Thus, their findings correspond with the findings of Cook et al. ( 2008 ).
Smith and Todd ( 2005a ) reanalyzed the National Supported Work data used by Dehejia and Wahba ( 2002 ). They find that the estimated impacts are highly sensitive to the particular subset of the data analyzed and the variables used in the analysis. Of the various analytical strategies employed, Smith and Todd ( 2005a ) find that difference in difference matching estimators perform the best. Like many other researchers, Smith and Todd ( 2005a ) find that variations in the matching procedure (e.g., number of individuals matched, use of calipers, local linear regressions) generally do not have a large effect on the estimated impacts. Although they conclude that propensity score matching can be a useful approach for nonexperimental evaluations, they believe that it is not a panacea and that there is no single best approach to propensity score matching that should be used. Footnote 9
Wilde and Hollister ( 2007 ) used data from an experimental evaluation of a class size reduction effort in Tennessee (Project STAR) to assess how well propensity score matching replicates the experimental impact estimates. They accomplished this by treating each school as a separate experiment and pooling the control groups from other schools in the study and then using propensity score matching to identify the best match for the treatment group in each school. The authors state that: “Our conclusion is that propensity score estimators do not perform very well, when judged by standards of how close they are to the ‘true’ impacts estimated from experimental estimators based on a random assignment design.” Footnote 10
Bloom et al. ( 2002 ) make use of an experiment designed to assess the effects of mandatory welfare to work programs in six states to compare a series of comparison groups and estimation strategies to see if popular nonexperimental methods do a reasonable job of approximating the impact estimates obtained from the experimental design. Nonexperimental estimation strategies tested include several propensity score matching strategies, ordinary least squares regression analysis, fixed effect models, and random growth models. The authors conclude that none of the approaches tried do a good job of reproducing the experimental findings and that more sophisticated approaches are sometimes worse than simple approaches such as ordinary least squares.
Overall, the weight of the evidence appears to indicate that nonexperimental approaches generally do not do a good job of replicating experimental estimates and that the most common problem is the lack of suitable data to control for key differences between the treatment group and comparison group. The most promising nonexperimental approach appears to be the regression discontinuity design, but this approach requires a much larger sample size to obtain the same amount of precision as an experiment. Footnote 11 The studies identify a number of factors that generally improve the performance of propensity score matching:
It is important to only include observations in the region of common support, where the probabilities of participating are nonzero for both treatment group members and comparison group members.
Data for the treatment and comparison groups should be drawn from the same data source, or the same questions should be asked of both groups.
Comparison group members should be drawn from the same geographic area as the treatment group.
It is important to understand and statistically control for the variables used to select people into the treatment group and to control for variables correlated with the outcomes of interest.
Difference in difference estimators appear to produce less bias than cross section matching in several of the studies, but it is not clear that this is always the case.
5 What we cannot learn from social experiments
Although experiments provide the best means of obtaining unbiased estimates of program impacts, there are some important limitations that must be kept in mind in designing experiments and interpreting the findings. This section describes some of the limitations that are typically inherent to experiments as well as problems that sometimes arise in experiments.
Although a well designed experiment can eliminate internal validity problems, there are often issues regarding external validity, the applicability of the findings in other situations. External validity for the eligible population is threatened if either the participating sites or individuals volunteer for the program rather than are randomly assigned. If the sites included in the experiment volunteered rather than were randomly selected, the impact findings may not be applicable to other sites. It is possible that the sites that volunteer are more effective sites, as less capable sites may want to avoid having their poor performance known to the world. In some of the welfare to work experiments conducted in the United States, random assignment was conducted among welfare recipients who volunteered to participate in the new program. The fact that the experiment was limited to welfare recipients who volunteered would not harm the internal validity of the evaluation, but the results might not apply to individuals who did not volunteer. If consideration is being given to making the intervention mandatory, then learning the effects of the program for volunteers does not identify the parameter of interest unless the program has the same impact on all participants. Although there is no way to assure external validity, exploratory analyses examining whether impacts are consistent across sites and subgroups can suggest (but not prove) if there is a problem.
Experiments typically randomly assign people to the treatment or control group after they have applied for or enrolled in the program. Thus, experiments typically do not pick up any effects the intervention might have that encourage or discourage participation. For example, if a very generous training option is added to a welfare program, more people might sign up for the program. These types of effects, referred to as entry effects, can be an important aspect of a program's effects. Because experiments are likely not to measure these effects, nonexperimental methods must be used to estimate the entry effects. Footnote 12
Another issue that is difficult to deal with in the context of experiments is the finite time horizon that typically accompanies an experiment. If the experiment is offered on a temporary basis and potential participants are aware of the finite period of the experiment, their behavior may be quite different from what would occur if the program were permanent. Consider a health insurance experiment, for example. If members of the treatment group have more generous coverage during the experiment than they will have after the experiment, they are more likely to increase their spending on health care for services that might otherwise be postponed. The experiment will provide estimates of the impact of a temporary policy, but what is needed for policy purposes is the impact of a permanent program. This issue can be dealt with in several ways. One approach would be to run the experiment for a long time so that the treatment group's response would be similar to what would occur for a permanent program; this would usually not be feasible due to cost issues. Another approach would be to enroll members of the treatment group for a varying number of years and then try to estimate how the response varies with time in the experiment. Finally, one could enroll the participants in a “permanent” program and then buy them out after the data for the evaluation has been gathered.
Another area where experiments may provide only limited information is on general equilibrium effects. For example, a labor market intervention can have effects not captured in a typical evaluation. Examples include potential displacement of other workers by those who receive training, wage increases for the control group due to movement of those trained into a different labor market, and negative wage effects for occupations if the number of people trained is large. Another example is “herd immunity” observed in immunization programs; the benefits of an immunization program affect those not immunized at some point as their probability of contracting the disease diminishes as the number of people in the community immunized increases. Not only do small scale experiments fail to measure these effects, even the evaluation of a large scale program might miss them. Footnote 13
With human subjects, it is not always a simple matter to assure that individuals in the treatment group obtain the treatment and those in the control group do not receive the treatment. In addition, being in the control group in the experiment may provide benefits that would not have been received had there been no experiment. These three cases are described below.
One factor that differentiates social experiments from agricultural experiments is that often some of those assigned to the treatment group do not receive the treatment. So-called no-shows are frequently found in program evaluations, including experiments. It is essential that no-shows be included in the treatment group to preserve the equality of the treatment and control groups. Unfortunately, the experimental impact estimates produced when there are no-shows provide the impact of an offer of the treatment, not the impact of the treatment itself. A policy maker who is trying to decide whether to continue a training program is not interested in the impact of an offer for training – the program only incurs costs for those who enroll, so the policy maker wants to know the impact for those who participate.
Bloom ( 1984 ) has shown that if one is willing to assume that the treatment has no impact on no-shows, the experimental impact estimator can be adjusted to provide an estimate of the impact on the treated. The overall impact of the program is a weighted average of the impact on those who receive the treatment, \( { I_{\text{P}} } \) , and those who do not receive the treatment, \( { I_{\text{NP}} } \) :
where p is the fraction of the treatment group that receives the treatment. If the impact on those who do not receive the treatment is zero, then \( { I_{\text{NP}} = 0 } \) , and \( { I_{\text{P}} = I/p } \) ; in other words, the impact of the program on those who receive the treatment is estimated by dividing the impact on the overall treatment group (including no-shows) by the proportion who actually receive the treatment.
Individuals assigned to the control group who somehow receive the treatment are referred to as “crossovers.” Orr ( 1999 ) observes that some analysts assign the crossovers to the treatment group or leave them out of the analysis, but either of these strategies is likely to destroy the similarity of the treatment and control groups. He further observes that if we are willing to assume that the program is equally effective for the crossovers and the “crossover-like” individuals in the treatment group, then the impact on the crossover-like individuals is zero and the overall impact of the program can be expressed as a weighted average of the impact on the crossover-like individuals and other individuals:
where \( { I_{\text{c}} } \) is the impact on crossover-like participants, \( { I_{\text{o}} } \) is the impact on others, and c is the proportion of the control group that crossed over; assuming that \( { I_{\text{c}} = 0 } \) , we can then compute the impact on those who do not cross over as \( { I_{\text{o}} = I/(1 - c) } \) . If the crossovers receive a similar but not identical treatment, then the impact on the crossover-like individuals may well not be zero, and Orr ( 1999 ) indicates that the best that can be done is to vary the value of \( { I_{\text{c}} } \) and obtain a range of estimates. Footnote 14
Heckman and Smith ( 1995 ) raise a related issue. In some experiments, the control group may receive valuable services in the process of being randomized out that they would not receive if there were no experiment. This may occur because when people are being recruited for the experiment, they receive some services with the goal of increasing their interest. Alternatively, to reduce ethical concerns, those randomized out may receive information about alternative treatments, which they then receive. In either case, the presence of the experiment has altered the services received by the control group and this creates what Heckman and Smith ( 1995 ) refer to as “substitution bias.”
Heckman and Smith ( 1995 ) also discuss the concept of “randomization bias” that can arise because the experiment changes the scale of the intervention. This problem can arise when the program has heterogeneous impacts and as the scale of the program is increased, those with smaller expected impacts are more likely to enroll. Suppose, for example, that at its usual scale a training program has an earnings impact of $1,000 per year. When the experiment is introduced, the number of people accepted into the program increases, so the impact is likely to decline. It is possible, at least in theory, to assess this problem and correct for it by asking programs to indicate which individuals would have been accepted at the original scale and at the experiment scale. Another possible way to avoid this problem is to reduce the operating scale of the program during the experiment so that the size of the treatment and control groups combined is equal to the normal operating size of the program. More practically, randomization bias can be minimized if the proportion randomized out is very small, say 10% or less; this was the strategy employed in the experimental evaluation of the Job Corps in the United States where Schochet ( 2001 ) indicates that only about 7% of those admitted to the program were assigned to the control group. Footnote 15
6 What can go wrong in social experiments?
In addition to the issues described above that frequently arise in social experiments, there are a number of problems that can also arise. Several common problems are described in this section, and the following section provides a case study of one experiment.
For demonstration projects and for new programs, the intervention may change after the program is initiated. In some cases it may take several months for the program to be working at full capacity; those who enroll when the program first opens may not receive the same services as later participants receive. The program might also change because program officials learn that some program components do not work as well in practice as they do in theory, economic conditions change, or the participants differ from what was anticipated. Some types of interventions, such as comprehensive community initiatives are expected to change over their implementation as new information is gathered. Footnote 16 Although program modifications often improve the intervention, they can complicate the evaluation in several ways. Instead of determining the impact of one known intervention, the impact evaluation may provide estimates that represent an average of two or more different strategies. At worst, policy makers might believe that the impact findings apply to a different intervention than what was evaluated.
Several strategies can be used to avoid or minimize these types of problems. First, it is important to monitor the implementation of the intervention. Even ongoing programs should be subject to implementation studies so that policy makers know what is being evaluated and if it has changed over time. Second, for a new intervention, it is often wise to postpone the impact evaluation until the intervention has achieved a steady state. Finally, if major changes in the intervention occur over the period analyzed, the evaluation can be conducted for two or more separate periods, although this strategy reduces the precision of the impact estimates.
Experiments can vary in their complexity, and this can lead to problems in implementation and the interpretation of findings. In some instances, experiments are complex because we wish to determine an entire “response surface” rather than evaluate a single intervention. Examples in the United States include the RAND health insurance experiment and the negative income tax (welfare reform) experiments (Greenberg and Schroder 2004 ), where various groups in the experiment were subject to variations in key parameters. For example, in the negative income tax experiments, participants were subject to variation in the maximum benefit and the rate at which benefits were reduced if they earned additional income. If the participants did not understand the concepts involved, particularly the implicit tax rate on earnings, then it would be inappropriate to develop a response surface based on variation in behavior by participants subject to different rules.
Problems in understanding the rules of the intervention can also arise in simpler experiments. For example, the State of Maryland wished to promote good parenting among its welfare recipients and instituted an experiment called the Primary Prevention Initiative (PPI). The treatment group in this experiment was required to assure that the children in the household maintained satisfactory school attendance (80% attendance), and preschool children were required to receive immunizations and physical examinations (Wilson et al. 1999 ). Parents who failed to meet these criteria were subject to a fine of $25.00 per month. The experiment included an implementation study, and as part of the implementation study, clients were surveyed on their knowledge of the PPI. Wilson et al. ( 1999 ) report that “only a small minority of clients (under 20%) could correctly identify even the general areas in which PPI had behavioral requirements.” The lack of knowledge was almost as high among those sanctioned as for clients not sanctioned. Not surprisingly, the impact evaluation indicated that the PPI had no effect on the number of children that were immunized, that received a physical exam, or that had satisfactory school attendance. If there had been no data on program knowledge, readers of the impact evaluation might logically have inferred that the incentives were not strong enough rather than that participants did not understand the intervention.
The potential for participants in experiments to not fully understand the rules of the intervention is not trivial. If we obtain zero impacts because participants do not understand the rules and it is possible to educate them, it is important to identify the reasons why we estimate no impact. Thus, whenever there is a reasonable possibility of participants misunderstanding the rules, it is advisable to consider including a survey of intervention knowledge as part of the evaluation.
Finally, in instances where state or local programs are asked to volunteer to participate in the program, there may be a high refusal rate, thus jeopardizing external validity. Sites with low impacts may be reluctant to participate as may sites that are having trouble recruiting adequate participants. Sites may also be reluctant to participate if they believe random assignment is unethical, as was discussed above, or adds a delay in processing applicants.
7 Lessons from the National JTPA Study
This section describes some of the problems that occurred in implementing the National JTPA Study in the United States. The Job Training Partnership Act (JTPA) was the primary workforce program for disadvantaged youth and adults in the United States from 1982 through 1998 when the Workforce Investment Act (WIA) was enacted. The U.S. Department of Labor decided to evaluate JTPA with a classical experiment after a series of impact evaluations of JTPA's predecessor produced such a wide range of estimated impacts that it was impossible to know the impact of the program. Footnote 17 The National JTPA Study used a classical experimental design to estimate the impact of the JTPA program on disadvantaged adults and out-of-school disadvantaged youth. The study began in 1986 and made use of JTPA applicants in 16 sites across the country. The impact evaluation found that the program increased earnings of adult men and women by over $1,300 in 1998 dollars during the second year after training. The study found that the out-of-school youth programs were ineffective, and these findings are not discussed below.
I focus on the interim report of the National JTPA Study for several reasons. Footnote 18 First, the study was generally well done, and it was cited by Hollister ( 2008 ) as one of the best social experiments that was conducted. The problems that I review below are not technical flaws in the study design or implementation, but program features that precluded analyzing the hypotheses of most interest and, in my view, approaches to presenting the findings that may have led policy makers to misinterpret the findings. I focus on the interim report rather than the final report because many of the presentation issues that I discuss were not repeated in the final report. Footnote 19
7.1 Nonrandom site selection
The study design originally called for 16 to 20 local sites to be selected at random. Sites were offered modest payments to compensate for extra costs incurred and to pay for inconvenience experienced. The experiment took place when the economy was relatively strong, and many local programs (called service delivery areas or SDAs) were having difficulty spending all their funding. Because participating sites were required to recruit 50% more potential participants to construct a control group one-half the size of the treatment group, many sites were reluctant to participate in the experiment. In the end, the project enrolled all 16 sites identified that were willing and able to participate. All evaluations, including experiments, run the risk of failing to have external validity, but the fact that most local sites refused to participate raised suspicion that the sites selected did not constitute a representative sample of sites. The National JTPA Study report does note that no large cities are included in the participating sample of 16 SDAs (by design), but the report's overall conclusion is more optimistic: “The most basic conclusion … is that the study sites and the 17,026 members of the 18-month study sample resemble SDAs and their participants nationally and also include much of their diversity” (Bloom et al. 1993 , p. 73).
Although the external validity of the National JTPA Study has been subject to a great deal of debate among analysts, there is no way to resolve the issue. Obviously it is best to avoid sites refusing to participate, but that may be easier said than done. Potential strategies to improve participation include larger incentive payments, exemption from performance standards sanctions for the period of participation, Footnote 20 making participation in evaluations mandatory in authorizing legislation, and decreasing the proportion of the applicants assigned to the control group.
7.2 Random assignment by service strategy recommended
Experimental methods can only be used to evaluate hypotheses where random assignment was used to assign the specific treatment received. In JTPA, the evaluators determined that prior to the experiment adults in the 16 sites were assigned to one of three broad categories – (1) occupational classroom training, (2) job search assistance (JSA) or on-the-job training (OJT), and (3) other services. Although OJT is generally the most expensive service strategy, because the program pays up to one-half of the participant's wages for up to six months, and JSA is the least expensive because it is generally of short duration and is often provided in a group setting, it was observed that the individuals deemed appropriate for OJT were virtually job ready as were those recommended for JSA; in addition, because OJT slots are difficult to obtain, candidates for OJT are often given JSA while waiting for an OJT slot to become available. The “other” category included candidates recommended for services such as basic skills (education), work experience, and other miscellaneous services but not occupational classroom training or OJT.
The strategy used in the National JTPA Study was to perform random assignment after a prospective participant was given a preliminary assessment and a service strategy recommended for the person; individuals that the program elected not to serve were excluded from the experiment. Two-thirds of the participants recommended for services were in the treatment group, and one-third was excluded from the JTPA program for a period of 18 months. During the embargo period, control group members were permitted to enroll in any workforce activities other than JTPA that they wished.
There are several concerns with the random assignment procedures used in the National JTPA Study. None of these concerns threatens the internal validity of the impacts estimated, but they show how difficult it is to test the most interesting hypotheses when trying to graft a random assignment experimental design to an existing program.
By presenting findings primarily per assignee rather than per participant, the findings may be misinterpreted . This issue relates more to presentation than analysis. A reader of the full report can find detailed information about what the findings mean, but the executive summary stresses impact estimates per assignee, so casual readers may not learn the impact per person who enrolls in the program. Footnote 21 There are often large differences between the impact per assignee and impact per enrollee because for some analyses the percentage of assignees that actually enrolled in the program is much less than 100%. For adult women for example, less than half (48.6%) of the women assigned to classroom training actually received classroom training; for men, the figure was even lower (40.1%). Assignees who did not receive the recommended treatment strategy sometimes received other strategies, and the report notes that impacts per enrollee “were about 60 percent to 70 percent larger than impacts per assignee, depending on the target group” (Bloom et al. 1993 , p. xxxv). Policy makers generally think about what returns they are getting on people who enroll in the program, as little, if any, money is spent on no-shows. Thus, policy makers want to know the impact per enrollee, and they might assume that impact estimates are impact per enrollee rather than impact per assignee. Footnote 22 \( { ^{,} } \) Footnote 23
Failure to differentiate between the in-program period and the post-program period can be misleading, particularly for short-term findings. The impact findings are generally presented on a quarterly basis, measured in calendar quarters after random assignment, or for the entire six-quarter follow-up period. For strategies that typically last for more than one quarter, the reader can easily misinterpret the impact findings when the in-program and post-program impacts are not presented separately. Footnote 24 \( { ^{,} } \) Footnote 25
The strategy does not allow head-to-head testing of alternative strategies. Because random assignment is performed after a treatment strategy is recommended, the only experimental estimates that can be obtained are for a particular treatment versus control status. Thus, if, say, OJT has a higher experimental impact than classroom training, the experiment tells us nothing about what the impact of OJT would be for those assigned to classroom training. The only way to experimentally test this would be to randomly assign participants to treatment strategies. In the case of the JTPA, this would mean sometimes assigning people to a strategy that the SDA staff believed was inappropriate.
The strategy does not provide the impact of receiving a particular type of treatment – it only provides the impact of being assigned to a particular treatment stream . If all JTPA participants received the activities they were initially assigned to, this point would not be important, but this was not the case. Among the adult women and men who received services, slightly over one-half of those assigned to occupational classroom training received this service, 58 and 56%, respectively. Footnote 26 Of those who did not receive occupational classroom training, about one-half did not enroll, and the remainder received other services. The figures are similar for the OJT-JSA group except that over 40% never enrolled. The “other services” group received a variety of services with no single type of service dominating. There is, of course, no way to analyze actual services received using experimental methods, but the fact that a relatively large proportion of individuals received services other than those recommended makes interpretation of the findings difficult.
The OJT-JSA strategy assignee group includes those receiving the most expensive services and those receiving the least expensive services, so the impact estimates are not particularly useful. The proportions receiving JSA and OJT are roughly equal, but by estimating the impact for these two service strategies combined, policy and program officials cannot determine whether one of the two strategies or both are providing the benefits. It is impossible to disentangle the effects of these two very different strategies using experimental methods. In a future experiment this problem could be avoided by establishing narrower service strategies, e.g., making OJT and JSA separate strategies.
Control group members were barred from receiving JTPA services, but many received comparable services from other sources, making the results difficult to interpret. The National JTPA Study states that impact estimates of the JTPA program are relative to whatever non-JTPA services the control group received. Because both the treatment group and the control group were motivated to receive workforce services, it is perhaps not surprising that for many of the analyses the control group received substantial services. For example, for the men recommended to receive occupational classroom training, 40.1% of the treatment group received such training, but so did 24.2% of the control group. For women, 48.6% of the treatment group received occupational classroom training and 28.7% of the control group received such services. Thus, to some extent, the estimated impacts do not provide the impact of training versus no training, but of one type of training relative to another.
The point is not that the National JTPA Study was seriously flawed; on the contrary, Hollister ( 2008 ) is correct to identify this study as one of the better social experiments conducted in recent years. Rather, the two key lessons to be drawn from the study are as follows:
It is important to present impact estimates so that they answer the questions of primary interest to policy makers. This means clearly separating in-program and post-program impact findings and giving impacts per enrollee more prominence than impacts per assignee. Footnote 27
Some of the most important evaluation questions may be answered only through nonexperimental methods rather than experimental methods. Although experimental estimates are preferred when they are feasible, nonexperimental methods should be used when they are not. The U.S. Department of Labor has sometimes shied away from having researchers use nonexperimental methods in conjunction with experiments. When experimental methods cannot answer all the questions of interest, nonexperimental methods should be tried, with care taken to describe all assumptions made and for sensitivity analyses to be conducted.
8 Conclusions
This paper has addressed the strengths and weaknesses of social experiments. There is no doubt that experiments offer some advantages over nonexperimental evaluation approaches. Major advantages include the fact that experiments avoid the need to make strong assumptions about potential explanatory variables that are unavailable for analysis and the fact that experimental findings are much easier to explain to skeptical policy makers. Although there is growing literature testing how well nonexperimental methods replicate experimental impact estimates, there is no consensus on the extent to which positive findings can be generalized.
But experiments are not without problems. The key point of this paper is that any impact evaluation, experimental or nonexperimental in nature, can have serious limitations. First, there are some questions that experiments generally cannot answer. For example, experiments frequently have “no-shows” who do not participate in the intervention after they were randomly assigned to the treatment group, and crossovers who are members of the control group who somehow take the treatment intervention or something other than what was intended for the control group. Experiments are often bad at capturing entry effects and general equilibrium effects.
In addition, in implementing experimental designs, things can go wrong. Examples include problems with participants understanding the intervention and difficulties in testing the hypotheses of most interest. These points were illustrated by showing how the National JTPA Study, which included random assignment to treatment status and is considered by many as an example of a well conducted experiment, failed to answer many of the questions of interest to policy makers.
Thus, social experiments have many advantages, and one should always give careful thought to using random assignment to evaluate interventions of interest. It should be recognized, however, that simply conducting an experiment is not sufficient to assure that important policy questions are answered correctly. In short, an experiment is not a substitute for thinking.
Executive summary
It is widely agreed that randomized controlled trials – social experiments – are the gold standard for evaluating social programs. There are, however, important issues that cannot be tested using experiments, and often things go wrong when conducting experiments. This paper explores these issues and offers suggestions on dealing with commonly encountered problems. There are several reasons why experiments are preferable to nonexperimental evaluations. Because it is impossible to observe the same person in two states of the world at the same time, we must rely on some alternative approach to estimate what would have happened to participants had they not been in the program.
Nonexperimental evaluation approaches seek to provide unbiased and consistent impact estimates, either by developing comparison groups that are as similar as possible to the treatment group (propensity score matching) or by using approaches to control for observed and unobserved variables (e.g., fixed effects models, instrumental variables, ordinary least squares regression analysis, and regression discontinuity designs). Unfortunately, all the nonexperimental approaches require strong assumptions to assure that unbiased estimates are obtained, and these assumptions are not always testable. Overall, the evidence indicates that nonexperimental approaches generally do not do a good job of replicating experimental estimates and that the most common problem is the lack of suitable data to control for key differences between the treatment group and comparison group. The most promising nonexperimental approach appears to be the regression discontinuity design, but this approach requires a much larger sample size to obtain the same amount of precision as an experiment.
Although a well designed experiment can eliminate internal validity problems, there are often issues regarding external validity. External validity for the eligible population is threatened if either the participating sites or individuals volunteer for the program rather than are randomly assigned. Experiments typically randomly assign people to the treatment or control group after they have applied for or enrolled in the program. Thus, experiments typically do not pick up any effects the intervention might have that encourage or discourage participation. Another issue is the finite time horizon that typically accompanies an experiment; if the experiment is offered on a temporary basis and potential participants are aware of the finite period of the experiment, their behavior may be different than if the program were permanent. Experiments frequently have no-shows and crossovers, and these phenomena can only be addressed by resorting to nonexperimental methods. Finally, experiments generally cannot capture scale or general equilibrium effects.
Several things can go wrong in implementing an experiment. First, the intervention might change while the experiment is implemented. A common occurrence is that the intervention itself changes, either because the original design was not working or circumstances change. The intervention should be carefully monitored to observe this and the evaluation modified if it occurs. Another potential problem is that participants may not understand the intervention; to guard against this, knowledge should be tested and instruction provided if it is a problem.
Many of the problems described here occurred in the random assignment evaluation of the Job Training Partnership Act evaluation in the United States. Although the intent was to include a random sample of local programs, most local programs refused to participate, resulting in questions of external validity. Random assignment in the study occurred after an appropriate service strategy was selected. This assured that each strategy could be compared to exclusion from the program, but the alternative strategies could not be compared with each other. Crossover and no-show rates were high in the study, and it is likely many policy officials did not interpret the impact findings correctly. For example, 40% of the men recommended for classroom training received that treatment, as did 24% of the men in the control group. Thus, the difference in outcomes for the treatment and control groups is very different from the impact of receiving training versus not receiving training. Another feature that makes interpretation difficult is that one service strategy included those who received the most expensive strategy, on-the-job training, and the least expensive strategy, job search assistance; this makes it impossible to differentiate the impacts of these disparate strategies. Finally, the interim report made it difficult for the reader to separate impacts from the post-program period from those from the in-program period and much more attention was paid to the impact for the entire treatment group than the nonexperimentally estimated impact on the treated. It is likely that policy makers failed to understand the subtle but important differences here.
There is no doubt that experiments offer many advantages over nonexperimental evaluations. However, many problems can and do arise, and an experiment is not a substitute for thinking.
Kurzfassung
Es herrscht weitestgehend Konsens darüber, dass randomisierte kontrollierte Studien – Sozialexperimente – der „Goldstandard“ für die Bewertung sozialer Programme sind. Es gibt jedoch viele wichtige Aspekte, die sich nicht durch solche Studien bewerten lassen, und bei der Durchführung dieser Studien kann oft etwas schiefgehen. Die vorliegende Arbeit untersucht diese Themen und bietet Lösungsvorschläge für häufig entstehende Probleme. Es gibt viele Gründe, warum Experimente gegenüber nichtexperimentellen Bewertungen bevorzugt werden. Da es nicht möglich ist, die gleiche Person in zwei verschiedenen Zuständen gleichzeitig zu beobachten, müssen wir auf eine alternative Vorgehensweise zurückgreifen, um einzuschätzen, was mit den Probanden geschehen wäre, hätten sie am Maßnahmenprogramm nicht teilgenommen.
Nichtexperimentelle Bewertungsansätze versuchen unvoreingenommene, konsistente Aussagen über Auswirkungen zu treffen, indem sie entweder Vergleichsgruppen entwickeln, die der Behandlungsgruppe so ähnlich wie möglich sind („propensity score matching“), oder indem sie Ansätze verwenden, die beobachtete und nichtbeobachtete Variablen kontrollieren (z. B. Fixed-effects-Modelle, Instrumentalvariablen, „Ordinary Least Squares Regression Analysis“ und „Regression Discontinuity Designs“). Leider benötigen sämtliche nichtexperimentellen Ansätze starke Annahmen, um zu gewährleisten, dass unvoreingenommene Einschätzungen erfolgen. Es ist nicht immer möglich, solche Annahmen zu prüfen. Im Allgemeinen deuten alle Anzeichen darauf hin, dass nichtexperimentelle Ansätze nur schlecht experimentelle Einschätzungen reproduzieren können. Das häufigste Problem ist dabei der Mangel an geeigneten Daten, um die Kernunterschiede zwischen der Treatmentgruppe und der Vergleichsgruppe zu kontrollieren. Der vielversprechendste nichtexperimentelle Ansatz scheint das „Regression Discontinuity Design“ zu sein, wobei diese Methode eine wesentlich größere Versuchsgruppe benötigt, um die gleiche Präzision wie ein Experiment zu erreichen.
Obwohl ein gut geplantes Experiment Probleme der internen Validität ausschließen kann, bleiben oft Fragen der externen Validität. Die externe Validität hinsichtlich der Gesamtbevölkerung wird gefährdet, wenn entweder die teilnehmenden Standorte oder die Personen sich für das Programm freiwillig melden, anstatt zufällig ausgewählt zu werden. Normalerweise werden in Experimenten Personen zufällig der Treatmentgruppe oder der Kontrollgruppe zugeordnet nachdem sie sich für das Programm angemeldet haben. Auf dieser Weise bilden Experimente in der Regel Faktoren nicht ab, die Personen zur Teilnahme ermutigen oder von der Teilnahme abschrecken können. Ein weiterer Aspekt ist der begrenzte Zeithorizont, den ein Experiment normalerweise mit sich bringt. Läuft das Experiment nur für eine begrenzte Zeit und sind sich die potenziellen Teilnehmer dessen bewusst, kann ihr Verhalten anders sein, als wenn das Experiment zeitlich unbegrenzt wäre. Bei Experimenten muss man oft mit No-Shows und Cross-Overs rechnen, und nur nichtexperimentelle Methoden sind dafür geeignet, solche Phänomene zu berücksichtigen. Zuletzt können Experimente in der Regel Skaleneffekte und allgemeine Gleichgewichtseffekte nicht erfassen.
Bei der Durchführung von Experimenten kann einiges schief gehen. Erstens kann sich während der Durchführung die Intervention ändern. Dies passiert häufig, entweder weil das ursprüngliche Design sich als ungeeignet erwiesen hat oder weil sich die Bedingungen geändert haben. Die Intervention ist aus diesem Grund sorgfältig zu beobachten und die Bewertung gegebenenfalls entsprechend anzupassen. Ein weiteres potenzielles Problem ist die Möglichkeit, dass die Teilnehmer die Intervention nicht verstehen. Um hier vorzubeugen, sollten das Verständnis der Teilnehmer hinsichtlich der Intervention geprüft und ggf. Schulungen bereitgestellt werden.
Viele der hier beschriebenen Probleme sind bei randomisierten Bewertung des Job Training Partnership Act in den USA aufgetreten. Obwohl eine Zufallsauswahl von lokalen Programmen teilnehmen sollte, weigerten sich die meisten dieser Programme. Diese Weigerung wirft Fragen der externen Validität der Studie auf. Die Randomisierung für die Studie erfolgte, nachdem eine passende Maßnahmenstrategie für die verschiedenen Teilnehmer ausgewählt worden war. Diese Vorgehensweise stellte sicher, dass jede Strategie mit der Situation bei Nichtteilnahme am Programm verglichen werden konnte, jedoch konnten die alternativen Strategien dadurch nicht miteinander verglichen werden. Die Cross-Overs und No-Show-Raten für die Studie waren hoch, und es ist wahrscheinlich, dass viele Beamte die Ergebnisse falsch interpretierten. Zum Beispiel bekamen nur 40% der Männer, für die eine Schulung empfohlen wurde, dieses Treatment, aber auch 24% der Männer in der Kontrollgruppe. Die unterschiedlichen Ergebnisse der Treatment- und Kontrollgruppen sind also nicht auf die Tatsachte zurückzuführen, dass eine Gruppe Schulungen bekommen hat und die andere nicht. Eine weitere Besonderheit, die die Interpretation schwierig macht, ist, dass eine Maßnahmenstrategie sowohl die teuersten Maßnahmen (die Ausbildung am Arbeitsplatz) als auch die billigsten Maßnahmen (die Hilfe bei der Jobsuche) enthielt. Dadurch ist es nicht möglich, zwischen den Auswirkungen dieser disparaten Maßnahmen zu unterscheiden. Schließlich machte es der Zwischenbericht dem Leser schwer, die Auswirkungen, die in der Zeit nach dem Programm beobachtet wurden, von denen während der Programmzeit zu trennen, und die Auswirkungen für die gesamte Treatmentgruppe bekamen viel mehr Aufmerksamkeit als die nichtexperimentell geschätzten Auswirkungen auf die Maßnahmenteilnehmer. Höchstwahrscheinlich sind den Entscheidungsträgern subtile, aber wichtige Unterschiede hier entgangen.
Es gibt keinen Zweifel, dass Experimente zahlreiche Vorteile gegenüber nichtexperimentellen Bewertungen haben. Es können dabei jedoch viele Probleme auftreten, und ein Experiment kann das Nachdenken nicht ersetzen.
There are a number of factors that help determine the units used for random assignment. Assignment at the individual level generates the most observations, and hence the most precision, but in many settings it is not practical to conduct random assignment at the individual level. For example, in an educational setting, it is generally not feasible to assign students in the same classroom to different treatments. The most important problem resulting from random assignment at a more aggregated level is that there are fewer observations, leading to a greater probability that the treatment and control groups are not well matched and the potential for imprecise estimates of the treatment effect.
It is important to distinguish between a known null treatment and a broader “whatever they would normally get” control treatment. As discussed below, the latter situation often makes it difficult to know what comparison is specifically being made and how estimated the impacts should be interpreted.
Orr ( 1999 ) notes that by including a variety of treatment doses, we can learn more than the effect of a single dose level on participants; instead, we can estimate a behavioral response function that provides information on how the impact varies with the dosage. Heckman ( 2008 ) provides a broader look at the concept of economic causality.
There are many views on how serious Hawthorne effects distort impact estimates, in the original illumination studies at the Hawthorne works in the 1930s and in other contexts.
See Barnow et al. ( 1980 ) for a discussion of selection bias and a summary of approaches to deal with the problem.
As discussed more in the sections below, many circumstances can arise that make experimental findings difficult to interpret.
Propensity score matching is a two-step procedure where in the first stage the probability of participating in the program is estimated, and, in the simplest approach, in the second stage the comparison group is selected by matching each member of the treatment group with the nonparticipating person with the closest propensity score; there are numerous variations involving techniques such as multiple matches, weighting, and calipers. Regression discontinuity designs involve selection mechanisms where treatment/control status is determined by a screening variable.
It is important to keep in mind that regression discontinuity designs provide estimates of impact near the discontinuity, but experiments provide estimates over a broader range of the population.
See also the reply by Dehejia ( 2005 ) and the rejoinder by Smith and Todd ( 2005b ).
The paper by Wilde and Hollister ( 2007 ) is one of the papers reviewed by Cook et al. ( 2008 ), and they claim that because Wilde and Hollister control on too few covariates and draw their comparison group from other areas than where the treatment group resides, the Wilde and Hollister paper does not offer a good test of propensity score matching.
Schochet ( 2009 ) shows that a regression discontinuity design typically requires a sample three to four times as large as an experimental design to achieve the same level of statistical precision.
See Moffitt ( 1992 ) for a review of the topic and Card and Robins ( 2005 ) for a recent evaluation of entry effects.
See Lise et al. ( 2005 ) for further discussion of these issues.
See Heckman et al. ( 2000 ) for discussion of this issue and estimates for JTPA. The authors find that JTPA provides only a small increase in the opportunity to receive training and that both JTPA and its substitutes increase earnings for participants; thus, focusing only on the experimental estimates of training impacts can lead to a large underestimate of the impact of training on earnings.
The Job Corps evaluation was able to deny services to a small proportion of applicants by including all eligible Job Corps applicants in the study, with only a relatively small proportion of the treatment group interviewed. The reason that this type of design has not been more actively used is that if there is a substantial fixed cost per site included in the experiment, including all sites generates large costs and for a fixed budget results in a smaller overall sample.
Comprehensive community initiatives are generally complex interventions that include interventions in a number of areas including employment, education, health, and community organization. See Connell and Kubisch ( 1998 ) for a discussion of comprehensive community initiatives and why they are difficult to evaluate.
See Barnow ( 1987 ) for a summary of the diverse findings from the evaluations of the Comprehensive Employment and Training Act (CETA) that were obtained when a number of analysts used diverse nonexperimental methods to evaluate the program.
I was involved in the National JTPA study as a subcontractor on the component that investigated the possibility of using nonexperimental approaches to determine the impact of the program rather than experimental approaches.
The final report was published as Orr et al. ( 1996 ).
Although exempting participating sites from performance standards sanctions may increase participation, it also reduces external validity because the participating sites no longer face the same performance incentives.
Some tables in the executive summary (e.g., Exhibit S.2 and Exhibit S.6) only provide the impact per assignee, and significance levels are only provided for estimates of impact per assignee.
A U.S. Department of Labor senior official complained to me that one contractor refused to provide her with impacts per enrollee because they were based on nonexperimental methods and could not, therefore, be believed. She opined that the evaluation had little value for policy decisions if the evaluation could not provide the most important information she needed.
Although I argue that estimates on the eligible population, sometimes referred to as “intent to treat” (ITT) estimates are prone to misinterpretation, estimating participation rates and the determinants of participation can be valuable for policy officials to learn the extent to which eligible individuals are participating and what groups appear to be underserved. See Heckman and Smith ( 2004 ).
It is, of course, important to capture the impacts for the in-program period so that a cost-benefit analysis can be conducted.
For example, Stanley et al. ( 1998 ) summarize the impact findings from the National JTPA Study by presenting the earnings impacts in the second year after random assignment, which is virtually all a post-program period.
See Exhibit 3.18 of Bloom et al. ( 1993 ).
This is not a simple matter when program length varies significantly, as it did in the JTPA program. If the participants are followed long enough, however, part of the follow-up period should be virtually should all be after program exit.
Angrist, J.D., Krueger, A.B.: Does compulsory attendance affect schooling and earnings? Q. J. Econ. 106 (4), 979–1014 (1991)
Article Google Scholar
Angrist, J.D., Krueger, A.B.: Instrumental variables and the search for identification: from supply and demand to natural experiments. J. Econ. Perspect. 15 (4), 9–85 (2001)
Google Scholar
Barnow, B.S.: The impacts of CETA programs on earnings: a review of the literature. J. Hum. Resour. 22 (2), 157–193 (1987)
Barnow, B.S.: The ethics of federal social program evaluation: a response to Jan Blustein. J. Policy Anal. Manag. 24 (4), 846–848 (2005)
Barnow, B.S., Cain, G.G., Goldberger, A.S.: Issues in the analysis of selection bias. In: Stromsdorfer, E.W., Farkas, G. (eds.) Evaluation Studies Review Annual, vol. 5. Sage Publications, Beverly Hills (1980)
Bloom, H.S.: Accounting for no-shows in experimental evaluation designs. Evaluation Rev. 8 (2), 225–246 (1984)
Bloom, H.S., Orr, L.L., Cave, G., Bell, S.H., Doolittle, F.: The National JTPA Study: Title II-A Impacts on Earnings and Employment at 18 Months. Abt Associates, Bethesda, MD (1993)
Bloom, H.S., Michalopoulos, C., Hill, C.J., Lei, Y.: Can Nonexperimental Comparison Group Methods Match the Findings from a Random Assignment Evaluation of Mandatory Welfare to Work Programs? MDRC, New York (2002)
Blustein, J.: Toward a more public discussion of the ethics of federal social program evaluation. J. Policy Anal. Manag. 24 (4), 824–846 (2005a)
Blustein, J.: Response. J. Policy Anal. Manag. 24 (4), 851–852 (2005b)
Burtless, G.: The case for randomized field trials in economic and policy research. J. Econ. Perspect. 9 (2), 63–84 (1995)
Card, D., Robins, P.K.: How important are “entry effects” in financial incentive programs for welfare recipients? J. Econometrics 125 (1), 113–139 (2005)
Connell, J.P., Kubisch, A.C.: Applying a theory of change approach to the evaluation of comprehensive community initiatives: progress, prospects, and problems. In: Fulbright-Anderson, K., Kubisch, A.C., Connell, J.P. (eds.) New Approaches to Evaluating Community Initiatives, vol. 2, Theory, Measurement, and Analysis. The Aspen Institute, Washington, DC (1998)
Cook, T.D., Shadish, W.R., Wong, V.C.: Three conditions under which experiments and observational studies produce comparable causal estimates: new findings from within-study comparisons. J. Policy Anal. Manag. 27 (4), 724–750 (2008)
Dehejia, R.H.: Practical propensity score matching: a reply to Smith and Todd. J. Econometrics 125 (1), 355–364 (2005)
Dehejia, R.H., Wahba, S.: Propensity score matching methods for nonexperimental causal studies. Rev. Econ. Statistics 84 (1), 151–161 (2002)
Goldberger, A.S.: Selection Bias in Evaluating Treatment Effects: Some Formal Illustrations. Institute for Research on Poverty, Discussion Paper 123–72, University of Wisconsin, Madison, WI (1972)
Greenberg, D.H., Shroder, M.: The Digest of Social Experiments, 3rd edn. The Urban Institute Press, Washington DC (2004)
Hahn J., Todd, P.E., Van der Klaauw, W.: Identification and estimation of treatment effects with a regression discontinuity design. Econometrica 69 (1), 201–209 (2001)
Heckman, J.J.: Economic causality. Int. Stat. Rev. 76 (1), 1–27 (2008)
Heckman, J.J., Smith, J.A.: Assessing the case for social experiments. J. Econ. Perspect. 9 (2), 85–110 (1995)
Heckman, J.J., Smith, J.A.: The determinants of participation in a social program: evidence from a prototypical job training program. J. Labor Econ. 22 (2), 243–298 (2004)
Heckman, J.J., Ichimura, H., Todd, P.E.: Matching as an econometric evaluation estimator: evidence from evaluating a job training programme. Rev. Econ. Stud. 64 (4), 605–654 (1997)
Heckman, J.J., Hohmann, N., Smith, J., Khoo, M.: Substitution and dropout bias in social experiments: a study of an influential social experiment. Q. J. Econ. 115 (2), 651–694 (2000)
Hollister, R.G. jr.: The role of random assignment in social policy research: opening statement. J. Policy Anal. Manag. 27 (2), 402–409 (2008)
Lise, J., Seitz, S., Smith, J.: Equilibrium Policy Experiments and the Evaluation of Social Programs. Unpublished manuscript (2005)
Moffitt, R.: Evaluation methods for program entry effects. In: Manski, C., Garfinkel, I. (eds.) Evaluating Welfare and Training Programs. Harvard University Press, Cambridge, MA (1992)
Orr, L.L.: Social Experiments: Evaluating Public Programs with Experimental Methods. Sage Publications, Thousand Oaks, CA (1999)
Orr, L.L., Bloom, H.S., Bell, S.H., Doolittle, F., Lin, W.: Does Training for the Disadvantaged Work? Evidence from the National JTPA Study. The Urban Institute Press, Washington, DC (1996)
Rolston, H.: To learn or not to learn. J. Policy Anal. Manag. 24 (4), 848–849 (2005)
Schochet, P.Z.: National Job Corps Study: Methodological Appendixes on the Impact Analysis. Mathematical Policy Research, Princeton, NJ (2001)
Schochet, P.Z.: Comments on Dr. Blustein's paper, toward a more public discussion of the ethics of federal social program evaluation. J. Policy Anal. Manag. 24 (4), 849–850 (2005)
Schochet, P.Z.: Statistical power for regression discontinuity designs in education evaluations. J. Educ. Behav. Stat. 34 (2), 238–266 (2009)
Shadish, W.R., Clark, M.H., Steiner, P.M.: Can nonrandomized experiments yield accurate answers? A randomized experiment comparing random and nonrandom assignments. J. Am. Stat. Assoc. 103 (484), 1334–1343 (2008)
Smith, J.A., Todd, P.E.: Does matching overcome LaLonde's critique of nonexperimental estimators? J. Econometrics 125 (1), 305–353 (2005a)
Smith, J.A., Todd, P.E.: Rejoinder. J. Econometrics 125 (1), 305–353 (2005b)
Stanley, M., Katz, L., Krueger, A.: Developing Skills: What We Know about the Impacts of American Employment and Training Programs on Employment, Earnings, and Educational Outcomes. Cambridge, MA, unpublished manuscript (1998)
Wilde, E.T., Hollister, R.: How close is close enough? Evaluating propensity score matching using data from a class size reduction experiment. J. Policy Anal. Manag. 26 (3), 455–477 (2007)
Wilson, L.A., Stoker, R.P., McGrath, D.: Welfare bureaus as moral tutors: what do clients learn from paternalistic welfare reforms? Soc. Sci. Quart. 80 (3), 473–486 (1999)
Download references
Acknowledgements
I am grateful to Laura Langbein, David Salkever, Peter Schochet, Gesine Stephan, and participants in workshops at George Washington University and the University of Maryland at Baltimore County for comments. I am particularly indebted to Jeffrey Smith for his thoughtful detailed comments and suggestions. Responsibility for remaining errors is mine.
Author information
Authors and affiliations.
Trachtenberg School of Public Policy and Public Administration, George Washington University, 805 21st St, NW, Washington, DC, 20052, USA
Burt S. Barnow
You can also search for this author in PubMed Google Scholar
Corresponding author
Correspondence to Burt S. Barnow .
Rights and permissions
Reprints and permissions
About this article
Cite this article.
Barnow, B.S. Setting up social experiments: the good, the bad, and the ugly. ZAF 43 , 91–105 (2010). https://doi.org/10.1007/s12651-010-0042-6
Download citation
Published : 20 October 2010
Issue Date : November 2010
DOI : https://doi.org/10.1007/s12651-010-0042-6
Share this article
Anyone you share the following link with will be able to read this content:
Sorry, a shareable link is not currently available for this article.
Provided by the Springer Nature SharedIt content-sharing initiative
- Propensity Score
- Random Assignment
- Propensity Score Match
- Social Experiment
- Impact Estimate
Want to create or adapt books like this? Learn more about how Pressbooks supports open publishing practices.
8.1 Experimental design: What is it and when should it be used?
Learning objectives.
- Define experiment
- Identify the core features of true experimental designs
- Describe the difference between an experimental group and a control group
- Identify and describe the various types of true experimental designs
Experiments are an excellent data collection strategy for social workers wishing to observe the effects of a clinical intervention or social welfare program. Understanding what experiments are and how they are conducted is useful for all social scientists, whether they actually plan to use this methodology or simply aim to understand findings from experimental studies. An experiment is a method of data collection designed to test hypotheses under controlled conditions. In social scientific research, the term experiment has a precise meaning and should not be used to describe all research methodologies.

Experiments have a long and important history in social science. Behaviorists such as John Watson, B. F. Skinner, Ivan Pavlov, and Albert Bandura used experimental design to demonstrate the various types of conditioning. Using strictly controlled environments, behaviorists were able to isolate a single stimulus as the cause of measurable differences in behavior or physiological responses. The foundations of social learning theory and behavior modification are found in experimental research projects. Moreover, behaviorist experiments brought psychology and social science away from the abstract world of Freudian analysis and towards empirical inquiry, grounded in real-world observations and objectively-defined variables. Experiments are used at all levels of social work inquiry, including agency-based experiments that test therapeutic interventions and policy experiments that test new programs.
Several kinds of experimental designs exist. In general, designs considered to be true experiments contain three basic key features:
- random assignment of participants into experimental and control groups
- a “treatment” (or intervention) provided to the experimental group
- measurement of the effects of the treatment in a post-test administered to both groups
Some true experiments are more complex. Their designs can also include a pre-test and can have more than two groups, but these are the minimum requirements for a design to be a true experiment.
Experimental and control groups
In a true experiment, the effect of an intervention is tested by comparing two groups: one that is exposed to the intervention (the experimental group , also known as the treatment group) and another that does not receive the intervention (the control group ). Importantly, participants in a true experiment need to be randomly assigned to either the control or experimental groups. Random assignment uses a random number generator or some other random process to assign people into experimental and control groups. Random assignment is important in experimental research because it helps to ensure that the experimental group and control group are comparable and that any differences between the experimental and control groups are due to random chance. We will address more of the logic behind random assignment in the next section.
Treatment or intervention
In an experiment, the independent variable is receiving the intervention being tested—for example, a therapeutic technique, prevention program, or access to some service or support. It is less common in of social work research, but social science research may also have a stimulus, rather than an intervention as the independent variable. For example, an electric shock or a reading about death might be used as a stimulus to provoke a response.
In some cases, it may be immoral to withhold treatment completely from a control group within an experiment. If you recruited two groups of people with severe addiction and only provided treatment to one group, the other group would likely suffer. For these cases, researchers use a control group that receives “treatment as usual.” Experimenters must clearly define what treatment as usual means. For example, a standard treatment in substance abuse recovery is attending Alcoholics Anonymous or Narcotics Anonymous meetings. A substance abuse researcher conducting an experiment may use twelve-step programs in their control group and use their experimental intervention in the experimental group. The results would show whether the experimental intervention worked better than normal treatment, which is useful information.
The dependent variable is usually the intended effect the researcher wants the intervention to have. If the researcher is testing a new therapy for individuals with binge eating disorder, their dependent variable may be the number of binge eating episodes a participant reports. The researcher likely expects her intervention to decrease the number of binge eating episodes reported by participants. Thus, she must, at a minimum, measure the number of episodes that occur after the intervention, which is the post-test . In a classic experimental design, participants are also given a pretest to measure the dependent variable before the experimental treatment begins.
Types of experimental design
Let’s put these concepts in chronological order so we can better understand how an experiment runs from start to finish. Once you’ve collected your sample, you’ll need to randomly assign your participants to the experimental group and control group. In a common type of experimental design, you will then give both groups your pretest, which measures your dependent variable, to see what your participants are like before you start your intervention. Next, you will provide your intervention, or independent variable, to your experimental group, but not to your control group. Many interventions last a few weeks or months to complete, particularly therapeutic treatments. Finally, you will administer your post-test to both groups to observe any changes in your dependent variable. What we’ve just described is known as the classical experimental design and is the simplest type of true experimental design. All of the designs we review in this section are variations on this approach. Figure 8.1 visually represents these steps.

An interesting example of experimental research can be found in Shannon K. McCoy and Brenda Major’s (2003) study of people’s perceptions of prejudice. In one portion of this multifaceted study, all participants were given a pretest to assess their levels of depression. No significant differences in depression were found between the experimental and control groups during the pretest. Participants in the experimental group were then asked to read an article suggesting that prejudice against their own racial group is severe and pervasive, while participants in the control group were asked to read an article suggesting that prejudice against a racial group other than their own is severe and pervasive. Clearly, these were not meant to be interventions or treatments to help depression, but were stimuli designed to elicit changes in people’s depression levels. Upon measuring depression scores during the post-test period, the researchers discovered that those who had received the experimental stimulus (the article citing prejudice against their same racial group) reported greater depression than those in the control group. This is just one of many examples of social scientific experimental research.
In addition to classic experimental design, there are two other ways of designing experiments that are considered to fall within the purview of “true” experiments (Babbie, 2010; Campbell & Stanley, 1963). The posttest-only control group design is almost the same as classic experimental design, except it does not use a pretest. Researchers who use posttest-only designs want to eliminate testing effects , in which participants’ scores on a measure change because they have already been exposed to it. If you took multiple SAT or ACT practice exams before you took the real one you sent to colleges, you’ve taken advantage of testing effects to get a better score. Considering the previous example on racism and depression, participants who are given a pretest about depression before being exposed to the stimulus would likely assume that the intervention is designed to address depression. That knowledge could cause them to answer differently on the post-test than they otherwise would. In theory, as long as the control and experimental groups have been determined randomly and are therefore comparable, no pretest is needed. However, most researchers prefer to use pretests in case randomization did not result in equivalent groups and to help assess change over time within both the experimental and control groups.
Researchers wishing to account for testing effects but also gather pretest data can use a Solomon four-group design. In the Solomon four-group design , the researcher uses four groups. Two groups are treated as they would be in a classic experiment—pretest, experimental group intervention, and post-test. The other two groups do not receive the pretest, though one receives the intervention. All groups are given the post-test. Table 8.1 illustrates the features of each of the four groups in the Solomon four-group design. By having one set of experimental and control groups that complete the pretest (Groups 1 and 2) and another set that does not complete the pretest (Groups 3 and 4), researchers using the Solomon four-group design can account for testing effects in their analysis.
| Group 1 | X | X | X |
| Group 2 | X | X | |
| Group 3 | X | X | |
| Group 4 | X |
Solomon four-group designs are challenging to implement in the real world because they are time- and resource-intensive. Researchers must recruit enough participants to create four groups and implement interventions in two of them.
Overall, true experimental designs are sometimes difficult to implement in a real-world practice environment. It may be impossible to withhold treatment from a control group or randomly assign participants in a study. In these cases, pre-experimental and quasi-experimental designs–which we will discuss in the next section–can be used. However, the differences in rigor from true experimental designs leave their conclusions more open to critique.
Experimental design in macro-level research
You can imagine that social work researchers may be limited in their ability to use random assignment when examining the effects of governmental policy on individuals. For example, it is unlikely that a researcher could randomly assign some states to implement decriminalization of recreational marijuana and some states not to in order to assess the effects of the policy change. There are, however, important examples of policy experiments that use random assignment, including the Oregon Medicaid experiment. In the Oregon Medicaid experiment, the wait list for Oregon was so long, state officials conducted a lottery to see who from the wait list would receive Medicaid (Baicker et al., 2013). Researchers used the lottery as a natural experiment that included random assignment. People selected to be a part of Medicaid were the experimental group and those on the wait list were in the control group. There are some practical complications macro-level experiments, just as with other experiments. For example, the ethical concern with using people on a wait list as a control group exists in macro-level research just as it does in micro-level research.
Key Takeaways
- True experimental designs require random assignment.
- Control groups do not receive an intervention, and experimental groups receive an intervention.
- The basic components of a true experiment include a pretest, posttest, control group, and experimental group.
- Testing effects may cause researchers to use variations on the classic experimental design.
- Classic experimental design- uses random assignment, an experimental and control group, as well as pre- and posttesting
- Control group- the group in an experiment that does not receive the intervention
- Experiment- a method of data collection designed to test hypotheses under controlled conditions
- Experimental group- the group in an experiment that receives the intervention
- Posttest- a measurement taken after the intervention
- Posttest-only control group design- a type of experimental design that uses random assignment, and an experimental and control group, but does not use a pretest
- Pretest- a measurement taken prior to the intervention
- Random assignment-using a random process to assign people into experimental and control groups
- Solomon four-group design- uses random assignment, two experimental and two control groups, pretests for half of the groups, and posttests for all
- Testing effects- when a participant’s scores on a measure change because they have already been exposed to it
- True experiments- a group of experimental designs that contain independent and dependent variables, pretesting and post testing, and experimental and control groups
Image attributions
exam scientific experiment by mohamed_hassan CC-0
Foundations of Social Work Research Copyright © 2020 by Rebecca L. Mauldin is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License , except where otherwise noted.
Share This Book
Program Type
5 ground-breaking social psychology experiments.
Home » Blog » Psychology » 5 Ground-Breaking Social Psychology Experiments
Psychologists often use experiments to answer humanity’s most difficult questions. After the atrocities of Nazi Germany in World War II, many wondered how people could follow the orders to perform such horrific actions.
Yale researcher Stanley Milgram devised an experiment around the following question: “Could it be that [Adolf] Eichmann and his million accomplices in the Holocaust were just following orders? Could we call them all accomplices?”
[Adolf Eichmann was one of the major organizers of the Holocaust.]
He found that other populations would follow orders to harm people despite the orders conflicting with their personal morals. By studying this social phenomenon, scientists were able to surmise that atrocities committed during the war were not endemic to German soldiers, as initially believed.
Throughout history, other psychology experiments have tried to address specific issues to foster better understanding of human behavior.
Here is a look at five notable experiments from the second half of the 20th century to present day:
Bobo Doll Experiment
Conducted in 1961 by scientist Albert Bandura, this experiment sought to prove human behavior was learned through social imitation, rather than inherited genetically. Bandura hypothesized children would mimic an adult’s behavior if they trusted the adult. He chose to use a Bobo doll, a roughly 5-foot-tall inflatable toy weighted at the bottom that bounces back to standing upright after being struck.
One group of children did not witness any adult interaction with the toy. Another group watched an adult behave aggressively. Bandura’s experiment found that children exposed to aggression were more likely to imitate the behavior and boys were three times more likely to mimic violence than girls.
Bystander Effect
In the 1960s, John Darley and Bibb Latané sought to measure how much time elapsed before bystanders reacted and either intervened or ignored the need for help when an emergency situation involving a group or an individual was staged. The researchers were inspired by the murder of Kitty Genovese in 1964, which became infamous after The New York Times reported that there were 38 witnesses to her murder and none of them tried to help.
Although the Kitty Genovese phenomenon was debunked later by the Times itself , it caused Darley and Latané’s discovery of The Bystander Effect. They demonstrated that a larger number of bystanders diminished the chances any of them would offer help. The Bystander Effect has continued to be replicated for years.
Halo Effect
The “halo effect” is a famous social psychology finding which suggests global or group evaluations about an individual can influence judgments about a specific trait. For example, a likable person is often perceived to be intelligent. The term, originally coined by psychology Edward Thorndike, is a type of confirmation bias.
In the 1970s, researchers Richard Nisbett and Timothy DeCamp Wilson performed an experiment to demonstrate this by showing two groups of students the same lecture, but changing the demeanor of the lecturer from one group to the next. When the lecturer appeared friendly, students responded more favorably than the group who saw the lecturer who appeared cold and distant.
The Chameleon Effect
Also referred to as “unintentional mirroring,” the Chameleon Effect is believed to be a natural tendency for one person to imitate another person based on how well they get along without any realization that it’s happening. Tanya Chartrand and John Bargh from New York University studied this phenomenon in the 1990s. They interviewed participants individually while affecting different mannerisms throughout the talk to gauge the bond that developed.
During two follow-up talks, the scientists mimicked the posture and other mannerisms of some test subjects. The participants mimicked the scientists more in the first experiment and found the scientists more likable when they mimicked their own mannerisms in the follow-ups. Those participants who weren’t mimicked had a more neutral opinion of the scientists.
The Volkswagen Fun Theory
In 2009, advertising agency DDB Stockholm created an initiative on behalf of car manufacturer Volkswagen. The company came up with the “ Fun Theory ,” conducting three experiments to see whether people might choose to change behavior and do something based on how much fun it was to do, such as recycling, throwing away trash or taking stairs versus an escalator.
In one instance, a set of stairs next to an escalator was decorated to look like piano keys with accompanying notes for each step a person took while traversing the stairs. The experiment found 66% more people chose the stairs than usual. In another, a trash bin with sound effects when people deposited litter collected more trash than nearby bins.
Though these were part of an advertising campaign rather than a scientific experiment, the results indicate people may be more inclined to perform a task such as taking stairs instead of an escalator if it appears to be fun.
RELATED ARTICLES
What is hybrid project management, supply chain lessons from covid-19, 833-591-1092.
Risepoint maintains this website on behalf of Florida Institute of Technology. Florida Tech maintains responsibility for curriculum, teaching, admissions, tuition, financial aid, accreditation, and all other academic- and instruction-related functions and decisions.
Learn more about Risepoint.
© 2024 privacy | terms | student disclosures
Get Our Program Guide
If you are ready to learn more about our programs, get started by downloading our program guide now.
11+ Psychology Experiment Ideas (Goals + Methods)
Have you ever wondered why some days you remember things easily, while on others you keep forgetting? Or why certain songs make you super happy and others just…meh?
Our minds are like big, mysterious puzzles, and every day we're finding new pieces to fit. One of the coolest ways to explore our brains and the way they work is through psychology experiments.
A psychology experiment is a special kind of test or activity researchers use to learn more about how our minds work and why we behave the way we do.
It's like a detective game where scientists ask questions and try out different clues to find answers about our feelings, thoughts, and actions. These experiments aren't just for scientists in white coats but can be fun activities we all try to discover more about ourselves and others.
Some of these experiments have become so famous, they’re like the celebrities of the science world! Like the Marshmallow Test, where kids had to wait to eat a yummy marshmallow, or Pavlov's Dogs, where dogs learned to drool just hearing a bell.
Let's look at a few examples of psychology experiments you can do at home.
What Are Some Classic Experiments?
Imagine a time when the mysteries of the mind were being uncovered in groundbreaking ways. During these moments, a few experiments became legendary, capturing the world's attention with their intriguing results.

The Marshmallow Test
One of the most talked-about experiments of the 20th century was the Marshmallow Test , conducted by Walter Mischel in the late 1960s at Stanford University.
The goal was simple but profound: to understand a child's ability to delay gratification and exercise self-control.
Children were placed in a room with a marshmallow and given a choice: eat the marshmallow now or wait 15 minutes and receive two as a reward. Many kids struggled with the wait, some devouring the treat immediately, while others demonstrated remarkable patience.
But the experiment didn’t end there. Years later, Mischel discovered something astonishing. The children who had waited for the second marshmallow were generally more successful in several areas of life, from school achievements to job satisfaction!
While this experiment highlighted the importance of teaching patience and self-control from a young age, it wasn't without its criticisms. Some argued that a child's background, upbringing, or immediate surroundings might play a significant role in their choices.
Moreover, there were concerns about the ethics of judging a child's potential success based on a brief interaction with a marshmallow.
Pavlov's Dogs
Traveling further back in time and over to Russia, another classic experiment took the world by storm. Ivan Pavlov , in the early 1900s, wasn't initially studying learning or behavior. He was exploring the digestive systems of dogs.
But during his research, Pavlov stumbled upon a fascinating discovery. He noticed that by ringing a bell every time he fed his dogs, they eventually began to associate the bell's sound with mealtime. So much so, that merely ringing the bell, even without presenting food, made the dogs drool in anticipation!
This reaction demonstrated the concept of "conditioning" - where behaviors can be learned by linking two unrelated stimuli. Pavlov's work revolutionized the world's understanding of learning and had ripple effects in various areas like animal training and therapy techniques.
Pavlov came up with the term classical conditioning , which is still used today. Other psychologists have developed more nuanced types of conditioning that help us understand how people learn to perform different behaviours.
Classical conditioning is the process by which a neutral stimulus becomes associated with a meaningful stimulus , leading to the same response. In Pavlov's case, the neutral stimulus (bell) became associated with the meaningful stimulus (food), leading the dogs to salivate just by hearing the bell.
Modern thinkers often critique Pavlov's methods from an ethical standpoint. The dogs, crucial to his discovery, may not have been treated with today's standards of care and respect in research.
Both these experiments, while enlightening, also underline the importance of conducting research with empathy and consideration, especially when it involves living beings.
What is Ethical Experimentation?
The tales of Pavlov's bells and Mischel's marshmallows offer us not just insights into the human mind and behavior but also raise a significant question: At what cost do these discoveries come?
Ethical experimentation isn't just a fancy term; it's the backbone of good science. When we talk about ethics, we're referring to the moral principles that guide a researcher's decisions and actions. But why does it matter so much in the realm of psychological experimentation?
An example of an experiment that had major ethical issues is an experiment called the Monster Study . This study was conducted in 1936 and was interested in why children develop a stutter.
The major issue with it is that the psychologists treated some of the children poorly over a period of five months, telling them things like “You must try to stop yourself immediately. Don’t ever speak unless you can do it right.”
You can imagine how that made the children feel!
This study helped create guidelines for ethical treatment in experiments. The guidelines include:
Respect for Individuals: Whether it's a dog in Pavlov's lab or a child in Mischel's study room, every participant—human or animal—deserves respect. They should never be subjected to harm or undue stress. For humans, informed consent (knowing what they're signing up for) is a must. This means that if a child is participating, they, along with their guardians, should understand what the experiment entails and agree to it without being pressured.
Honesty is the Best Policy: Researchers have a responsibility to be truthful. This means not only being honest with participants about the study but also reporting findings truthfully, even if the results aren't what they hoped for. There can be exceptions if an experiment will only succeed if the participants aren't fully aware, but it has to be approved by an ethics committee .
Safety First: No discovery, no matter how groundbreaking, is worth harming a participant. The well-being and mental, emotional, and physical safety of participants is paramount. Experiments should be designed to minimize risks and discomfort.
Considering the Long-Term: Some experiments might have effects that aren't immediately obvious. For example, while a child might seem fine after participating in an experiment, they could feel stressed or anxious later on. Ethical researchers consider and plan for these possibilities, offering support and follow-up if needed.
The Rights of Animals: Just because animals can't voice their rights doesn't mean they don't have any. They should be treated with care, dignity, and respect. This means providing them with appropriate living conditions, not subjecting them to undue harm, and considering alternatives to animal testing when possible.
While the world of psychological experiments offers fascinating insights into behavior and the mind, it's essential to tread with care and compassion. The golden rule? Treat every participant, human or animal, as you'd wish to be treated. After all, the true mark of a groundbreaking experiment isn't just its findings but the ethical integrity with which it's conducted.
So, even if you're experimenting at home, please keep in mind the impact your experiments could have on the people and beings around you!
Let's get into some ideas for experiments.
1) Testing Conformity
Our primary aim with this experiment is to explore the intriguing world of social influences, specifically focusing on how much sway a group has over an individual's decisions. This social influence is called groupthink .
Humans, as social creatures, often find solace in numbers, seeking the approval and acceptance of those around them. But how deep does this need run? Does the desire to "fit in" overpower our trust in our own judgments?
This experiment not only provides insights into these questions but also touches upon the broader themes of peer pressure, societal norms, and individuality. Understanding this could shed light on various real-world situations, from why fashion trends catch on to more critical scenarios like how misinformation can spread.
Method: This idea is inspired by the classic Asch Conformity Experiments . Here's a simple way to try it:
- Assemble a group of people (about 7-8). Only one person will be the real participant; the others will be in on the experiment.
- Show the group a picture of three lines of different lengths and another line labeled "Test Line."
- Ask each person to say out loud which of the three lines matches the length of the "Test Line."
- Unknown to the real participant, the other members will intentionally choose the wrong line. This is to see if the participant goes along with the group's incorrect choice, even if they can see it's wrong.
Real-World Impacts of Groupthink
Groupthink is more than just a science term; we see it in our daily lives:
Decisions at Work or School: Imagine being in a group where everyone wants to do one thing, even if it's not the best idea. People might not speak up because they're worried about standing out or being the only one with a different opinion.
Wrong Information: Ever heard a rumor that turned out to be untrue? Sometimes, if many people believe and share something, others might believe it too, even if it's not correct. This happens a lot on the internet.
Peer Pressure: Sometimes, friends might all want to do something that's not safe or right. People might join in just because they don't want to feel left out.
Missing Out on New Ideas: When everyone thinks the same way and agrees all the time, cool new ideas might never get heard. It's like always coloring with the same crayon and missing out on all the other bright colors!
2) Testing Color and Mood

We all have favorite colors, right? But did you ever wonder if colors can make you feel a certain way? Color psychology is the study of how colors can influence our feelings and actions.
For instance, does blue always calm us down? Does red make us feel excited or even a bit angry? By exploring this, we can learn how colors play a role in our daily lives, from the clothes we wear to the color of our bedroom walls.
- Find a quiet room and set up different colored lights or large sheets of colored paper: blue, red, yellow, and green.
- Invite some friends over and let each person spend a few minutes under each colored light or in front of each colored paper.
- After each color, ask your friends to write down or talk about how they feel. Are they relaxed? Energized? Happy? Sad?
Researchers have always been curious about this. Some studies have shown that colors like blue and green can make people feel calm, while colors like red might make them feel more alert or even hungry!
Real-World Impacts of Color Psychology
Ever noticed how different places use colors?
Hospitals and doctors' clinics often use soft blues and greens. This might be to help patients feel more relaxed and calm.
Many fast food restaurants use bright reds and yellows. These colors might make us feel hungry or want to eat quickly and leave.
Classrooms might use a mix of colors to help students feel both calm and energized.
3) Testing Music and Brainpower
Think about your favorite song. Do you feel smarter or more focused when you listen to it? This experiment seeks to understand the relationship between music and our brain's ability to remember things. Some people believe that certain types of music, like classical tunes, can help us study or work better. Let's find out if it's true!
- Prepare a list of 10-15 things to remember, like a grocery list or names of places.
- Invite some friends over. First, let them try to memorize the list in a quiet room.
- After a short break, play some music (try different types like pop, classical, or even nature sounds) and ask them to memorize the list again.
- Compare the results. Was there a difference in how much they remembered with and without music?
The " Mozart Effect " is a popular idea. Some studies in the past suggested that listening to Mozart's music might make people smarter, at least for a little while. But other researchers think the effect might not be specific to Mozart; it could be that any music we enjoy boosts our mood and helps our brain work better.
Real-World Impacts of Music and Memory
Think about how we use music:
- Study Sessions: Many students listen to music while studying, believing it helps them concentrate better.
- Workout Playlists: Gyms play energetic music to keep people motivated and help them push through tough workouts.
- Meditation and Relaxation: Calm, soothing sounds are often used to help people relax or meditate.
4) Testing Dreams and Food
Ever had a really wild dream and wondered where it came from? Some say that eating certain foods before bedtime can make our dreams more vivid or even a bit strange.
This experiment is all about diving into the dreamy world of sleep to see if what we eat can really change our nighttime adventures. Can a piece of chocolate or a slice of cheese transport us to a land of wacky dreams? Let's find out!
- Ask a group of friends to keep a "dream diary" for a week. Every morning, they should write down what they remember about their dreams.
- For the next week, ask them to eat a small snack before bed, like cheese, chocolate, or even spicy foods.
- They should continue writing in their "dream diary" every morning.
- At the end of the two weeks, compare the dream notes. Do the dreams seem different during the snack week?
The link between food and dreams isn't super clear, but some people have shared personal stories. For example, some say that spicy food can lead to bizarre dreams. Scientists aren't completely sure why, but it could be related to how food affects our body temperature or brain activity during sleep.
A cool idea related to this experiment is that of vivid dreams , which are very clear, detailed, and easy to remember dreams. Some people are even able to control their vivid dreams, or say that they feel as real as daily, waking life !
Real-World Impacts of Food and Dreams
Our discoveries might shed light on:
- Bedtime Routines: Knowing which foods might affect our dreams can help us choose better snacks before bedtime, especially if we want calmer sleep.
- Understanding Our Brain: Dreams can be mysterious, but studying them can give us clues about how our brains work at night.
- Cultural Beliefs: Many cultures have myths or stories about foods and dreams. Our findings might add a fun twist to these age-old tales!
5) Testing Mirrors and Self-image
Stand in front of a mirror. How do you feel? Proud? Shy? Curious? Mirrors reflect more than just our appearance; they might influence how we think about ourselves.
This experiment delves into the mystery of self-perception. Do we feel more confident when we see our reflection? Or do we become more self-conscious? Let's take a closer look.
- Set up two rooms: one with mirrors on all walls and another with no mirrors at all.
- Invite friends over and ask them to spend some time in each room doing normal activities, like reading or talking.
- After their time in both rooms, ask them questions like: "Did you think about how you looked more in one room? Did you feel more confident or shy?"
- Compare the responses to see if the presence of mirrors changes how they feel about themselves.
Studies have shown that when people are in rooms with mirrors, they can become more aware of themselves. Some might stand straighter, fix their hair, or even change how they behave. The mirror acts like an audience, making us more conscious of our actions.
Real-World Impacts of Mirrors and Self-perception
Mirrors aren't just for checking our hair. Ever wonder why clothing stores have so many mirrors? They might help shoppers visualize themselves in new outfits, encouraging them to buy.
Mirrors in gyms can motivate people to work out with correct form and posture. They also help us see progress in real-time!
And sometimes, looking in a mirror can be a reminder to take care of ourselves, both inside and out.
But remember, what we look like isn't as important as how we act in the world or how healthy we are. Some people claim that having too many mirrors around can actually make us more self conscious and distract us from the good parts of ourselves.
Some studies are showing that mirrors can actually increase self-compassion , amongst other things. As any tool, it seems like mirrors can be both good and bad, depending on how we use them!
6) Testing Plants and Talking

Have you ever seen someone talking to their plants? It might sound silly, but some people believe that plants can "feel" our vibes and that talking to them might even help them grow better.
In this experiment, we'll explore whether plants can indeed react to our voices and if they might grow taller, faster, or healthier when we chat with them.
- Get three similar plants, placing each one in a separate room.
- Talk to the first plant, saying positive things like "You're doing great!" or singing to it.
- Say negative things to the second plant, like "You're not growing fast enough!"
- Don't talk to the third plant at all; let it be your "silent" control group .
- Water all plants equally and make sure they all get the same amount of light.
- At the end of the month, measure the growth of each plant and note any differences in their health or size.
The idea isn't brand new. Some experiments from the past suggest plants might respond to sounds or vibrations. Some growers play music for their crops, thinking it helps them flourish.
Even if talking to our plants doesn't have an impact on their growth, it can make us feel better! Sometimes, if we are lonely, talking to our plants can help us feel less alone. Remember, they are living too!
Real-World Impacts of Talking to Plants
If plants do react to our voices, gardeners and farmers might adopt new techniques, like playing music in greenhouses or regularly talking to plants.
Taking care of plants and talking to them could become a recommended activity for reducing stress and boosting mood.
And if plants react to sound, it gives us a whole new perspective on how connected all living things might be .
7) Testing Virtual Reality and Senses
Virtual reality (VR) seems like magic, doesn't it? You put on a headset and suddenly, you're in a different world! But how does this "new world" affect our senses? This experiment wants to find out how our brains react to VR compared to the real world. Do we feel, see, or hear things differently? Let's get to the bottom of this digital mystery!
- You'll need a VR headset and a game or experience that can be replicated in real life (like walking through a forest). If you don't have a headset yourself, there are virtual reality arcades now!
- Invite friends to first experience the scenario in VR.
- Afterwards, replicate the experience in the real world, like taking a walk in an actual forest.
- Ask them questions about both experiences: Did one seem more real than the other? Which sounds were more clear? Which colors were brighter? Did they feel different emotions?
As VR becomes more popular, scientists have been curious about its effects. Some studies show that our brains can sometimes struggle to tell the difference between VR and reality. That's why some people might feel like they're really "falling" in a VR game even though they're standing still.
Real-World Impacts of VR on Our Senses
Schools might use VR to teach lessons, like taking students on a virtual trip to ancient Egypt. Understanding how our senses react in VR can also help game designers create even more exciting and realistic games.
Doctors could use VR to help patients overcome fears or to provide relaxation exercises. This is actually already a method therapists can use for helping patients who have serious phobias. This is called exposure therapy , which basically means slowly exposing someone (or yourself) to the thing you fear, starting from very far away to becoming closer.
For instance, if someone is afraid of snakes. You might show them images of snakes first. Once they are comfortable with the picture, they can know there is one in the next room. Once they are okay with that, they might use a VR headset to see the snake in the same room with them, though of course there is not an actual snake there.
8) Testing Sleep and Learning
We all know that feeling of trying to study or work when we're super tired. Our brains feel foggy, and it's hard to remember stuff. But how exactly does sleep (or lack of it) influence our ability to learn and remember things?
With this experiment, we'll uncover the mysteries of sleep and see how it can be our secret weapon for better learning.
- Split participants into two groups.
- Ask both groups to study the same material in the evening.
- One group goes to bed early, while the other stays up late.
- The next morning, give both groups a quiz on what they studied.
- Compare the results to see which group remembered more.
Sleep and its relation to learning have been explored a lot. Scientists believe that during sleep, especially deep sleep, our brains sort and store new information. This is why sometimes, after a good night's rest, we might understand something better or remember more.
Real-World Impacts of Sleep and Learning
Understanding the power of sleep can help:
- Students: If they know the importance of sleep, students might plan better, mixing study sessions with rest, especially before big exams.
- Workplaces: Employers might consider more flexible hours, understanding that well-rested employees learn faster and make fewer mistakes.
- Health: Regularly missing out on sleep can have other bad effects on our health. So, promoting good sleep is about more than just better learning.
9) Testing Social Media and Mood
Have you ever felt different after spending time on social media? Maybe happy after seeing a friend's fun photos, or a bit sad after reading someone's tough news.
Social media is a big part of our lives, but how does it really affect our mood? This experiment aims to shine a light on the emotional roller-coaster of likes, shares, and comments.
- Ask participants to note down how they're feeling - are they happy, sad, excited, or bored?
- Have them spend a set amount of time (like 30 minutes) on their favorite social media platforms.
- After the session, ask them again about their mood. Did it change? Why?
- Discuss what they saw or read that made them feel that way.
Previous research has shown mixed results. Some studies suggest that seeing positive posts can make us feel good, while others say that too much time on social media can make us feel lonely or left out.
Real-World Impacts of Social Media on Mood
Understanding the emotional impact of social media can help users understand their feelings and take breaks if needed. Knowing is half the battle! Additionally, teachers and parents can guide young users on healthy social media habits, like limiting time or following positive accounts.
And if it's shown that social media does impact mood, social media companies can design friendlier, less stressful user experiences.
But even if the social media companies don't change things, we can still change our social media habits to make ourselves feel better.
10) Testing Handwriting or Typing
Think about the last time you took notes. Did you grab a pen and paper or did you type them out on a computer or tablet?
Both ways are popular, but there's a big question: which method helps us remember and understand better? In this experiment, we'll find out if the classic art of handwriting has an edge over speedy typing.
- Divide participants into two groups.
- Present a short lesson or story to both groups.
- One group will take notes by hand, while the other will type them out.
- After some time, quiz both groups on the content of the lesson or story.
- Compare the results to see which note-taking method led to better recall and understanding.
Studies have shown some interesting results. While typing can be faster and allows for more notes, handwriting might boost memory and comprehension because it engages the brain differently, making us process the information as we write.
Importantly, each person might find one or the other works better for them. This could be useful in understanding our learning habits and what instructional style would be best for us.
Real-World Impacts of Handwriting vs. Typing
Knowing the pros and cons of each method can:
- Boost Study Habits: Students can pick the method that helps them learn best, especially during important study sessions or lectures.
- Work Efficiency: In jobs where information retention is crucial, understanding the best method can increase efficiency and accuracy.
- Tech Design: If we find out more about how handwriting benefits us, tech companies might design gadgets that mimic the feel of writing while combining the advantages of digital tools.
11) Testing Money and Happiness

We often hear the saying, "Money can't buy happiness," but is that really true? Many dream of winning the lottery or getting a big raise, believing it would solve all problems.
In this experiment, we dig deep to see if there's a real connection between wealth and well-being.
- Survey a range of participants, from those who earn a little to those who earn a lot, about their overall happiness. You can keep it to your friends and family, but that might not be as accurate as surveying a wider group of people.
- Ask them to rank things that bring them joy and note if they believe more money would boost their happiness. You could try different methods, one where you include some things that they have to rank, such as gardening, spending time with friends, reading books, learning, etc. Or you could just leave a blank list that they can fill in with their own ideas.
- Study the data to find patterns or trends about income and happiness.
Some studies have found money can boost happiness, especially when it helps people out of tough financial spots. But after reaching a certain income, extra dollars usually do not add much extra joy.
In fact, psychologists just realized that once people have an income that can comfortably support their needs (and some of their wants), they stop getting happier with more . That number is roughly $75,000, but of course that depends on the cost of living and how many members are in the family.
Real-World Impacts of Money and Happiness
If we can understand the link between money and joy, it might help folks choose jobs they love over jobs that just pay well. And instead of buying things, people might spend on experiences, like trips or classes, that make lasting memories.
Most importantly, we all might spend more time on hobbies, friends, and family, knowing they're big parts of what makes life great.
Some people are hoping that with Artificial Intelligence being able to do a lot of the less well-paying jobs, people might be able to do work they enjoy more, all while making more money and having more time to do the things that make them happy.
12) Testing Temperature and Productivity
Have you ever noticed how a cold classroom or office makes it harder to focus? Or how on hot days, all you want to do is relax? In this experiment, we're going to find out if the temperature around us really does change how well we work.
- Find a group of participants and a room where you can change the temperature.
- Set the room to a chilly temperature and give the participants a set of tasks to do.
- Measure how well and quickly they do these tasks.
- The next day, make the room comfortably warm and have them do similar tasks.
- Compare the results to see if the warmer or cooler temperature made them work better.
Some studies have shown that people can work better when they're in a room that feels just right, not too cold or hot. Being too chilly can make fingers slow, and being too warm can make minds wander.
What temperature is "just right"? It won't be the same for everyone, but most people find it's between 70-73 degrees Fahrenheit (21-23 Celsius).
Real-World Implications of Temperature and Productivity
If we can learn more about how temperature affects our work, teachers might set classroom temperatures to help students focus and learn better, offices might adjust temperatures to get the best work out of their teams, and at home, we might find the best temperature for doing homework or chores quickly and well.
Interestingly, temperature also has an impact on our sleep quality. Most people find slightly cooler rooms to be better for good sleep. While the daytime temperature between 70-73F is good for productivity, a nighttime temperature around 65F (18C) is ideal for most people's sleep.
Psychology is like a treasure hunt, where the prize is understanding ourselves better. With every experiment, we learn a little more about why we think, feel, and act the way we do. Some of these experiments might seem simple, like seeing if colors change our mood or if being warm helps us work better. But even the simple questions can have big answers that help us in everyday life.
Remember, while doing experiments is fun, it's also important to always be kind and think about how others feel. We should never make someone uncomfortable just for a test. Instead, let's use these experiments to learn and grow, helping to make the world a brighter, more understanding place for everyone.
Related posts:
- 150+ Flirty Goodnight Texts For Him (Sweet and Naughty Examples)
- Dream Interpreter & Dictionary (270+ Meanings)
- Sleep Stages (Light, Deep, REM)
- What Part of the Brain Regulates Body Temperature?
- Why Do We Dream? (6 Theories and Psychological Reasons)
Reference this article:
About The Author
Free Personality Test

Free Memory Test

Free IQ Test

PracticalPie.com is a participant in the Amazon Associates Program. As an Amazon Associate we earn from qualifying purchases.
Follow Us On:
Youtube Facebook Instagram X/Twitter
Psychology Resources
Developmental
Personality
Relationships
Psychologists
Serial Killers
Psychology Tests
Personality Quiz
Memory Test
Depression test
Type A/B Personality Test
© PracticalPsychology. All rights reserved
Privacy Policy | Terms of Use
Social Experimentation

Since 1970 the United States government has spent over half a billion dollars on social experiments intended to assess the effect of potential tax policies, health insurance plans, housing subsidies, and other programs. Was it worth it? Was anything learned from these experiments that could not have been learned by other, and cheaper, means? Could the experiments have been better designed or analyzed? These are some of the questions addressed by the contributors to this volume, the result of a conference on social experimentation sponsored in 1981 by the National Bureau of Economic Research. The first section of the book looks at four types of experiments and what each accomplished. Frank P. Stafford examines the negative income tax experiments, Dennis J. Aigner considers the experiments with electricity pricing based on time of use, Harvey S. Rosen evaluates housing allowance experiments, and Jeffrey E. Harris reports on health experiments. In the second section, addressing experimental design and analysis, Jerry A. Hausman and David A. Wise highlight the absence of random selection of participants in social experiments, Frederick Mosteller and Milton C. Weinstein look specifically at the design of medical experiments, and Ernst W. Stromsdorfer examines the effects of experiments on policy. Each chapter is followed by the commentary of one or more distinguished economists.
Working Groups
More from nber.
In addition to working papers , the NBER disseminates affiliates’ latest findings through a range of free periodicals — the NBER Reporter , the NBER Digest , the Bulletin on Retirement and Disability , the Bulletin on Health , and the Bulletin on Entrepreneurship — as well as online conference reports , video lectures , and interviews .

0, text: error()">
0, text: error(), css: errorCssClass">
Reset your password
Enter your email address or username and we’ll send you a link to reset your password
Check your inbox
An email with a link to reset your password was sent to the email address associated with your account
Provide email
Please enter your email to complete registration
Activate to continue
Your account isn't active yet. We've emailed you an activation link. Please check your inbox and click the link to activate your account
0, text: error" style="display: none;">
0, text: success" style="display: none;">
- Relationships
The Bored Panda iOS app is live! Fight boredom with iPhones and iPads here .
- Partnership
- Success stories
- --> -->